将 OneLake 与 Azure Databricks 集成
此方案演示如何通过 Azure Databricks 连接到 OneLake。 完成本教程后,你将能够从 Azure Databricks 工作区读取和写入 Microsoft Fabric 湖屋。
先决条件
在连接之前,必须具备:
- Fabric 工作区和湖屋。
- 高级 Azure Databricks 工作区。 只有高级 Azure Databricks 工作区支持 Microsoft Entra 凭据直通,这是此方案所需的。
设置 Databricks 工作区
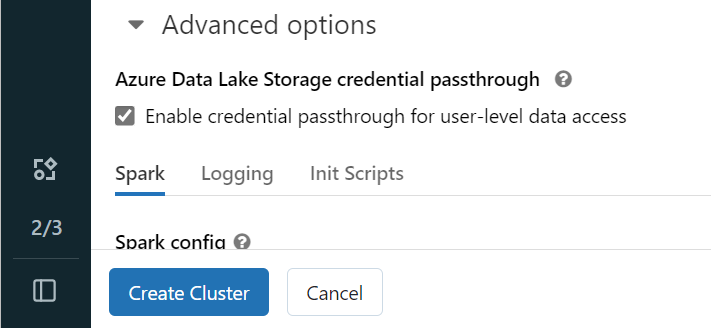
打开 Azure Databricks 工作区,然后选择“创建”>“群集”。
要使用 Microsoft Entra 标识向 OneLake 进行身份验证,必须在“高级选项”中对群集启用 Azure Data Lake Storage (ADLS) 凭据直通。
注意
还可以使用服务主体将 Databricks 连接到 OneLake。 有关使用服务主体对 Azure Databricks 进行身份验证的详细信息,请参阅管理服务主体。
使用首选参数创建群集。 有关创建 Databricks 群集的详细信息,请参阅配置群集 - Azure Databricks。
打开笔记本并将其连接到新创建的群集。
创作笔记本
导航到 Fabric 湖屋并将 Azure Blob 文件系统 (ABFS) 路径复制到湖屋。 可以在“属性”窗格中找到它。
注意
Azure Databricks 仅在读取和写入 ADLS Gen2 和 OneLake 时支持 Azure Blob 文件系统 (ABFS) 驱动程序:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/。将湖屋的路径保存到 Databricks 笔记本中。 此湖屋是你稍后写入已处理的数据的地方:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'将数据从 Databricks 公共数据集加载到数据帧中。 还可以从 Fabric 中的其他位置读取文件,或从已拥有的其他 ADLS Gen2 帐户中选择一个文件。
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")筛选、转换或准备数据。 对于此方案,可以剪裁数据集以加快加载速度、与其他数据集联接或筛选到特定结果。
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)使用 OneLake 路径将筛选的数据帧写入 Fabric 湖屋。
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)通过读取新加载的文件来测试数据是否已成功写入。
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
祝贺。 现在可以使用 Azure Databricks 在 Fabric 中读取和写入数据。