为 Direct Lake 创建湖屋
本文介绍如何创建 lakehouse、在 lakehouse 中创建 Delta 表,然后在 Microsoft Fabric 工作区中创建 lakehouse 的基本语义模型。
在开始为 Direct Lake 创建湖屋之前,请务必阅读 Direct Lake 概述。
创建湖仓
在 Microsoft Fabric 工作区中,选择“新建”>“更多选项”,然后在“数据工程”中选择“湖屋”磁贴。
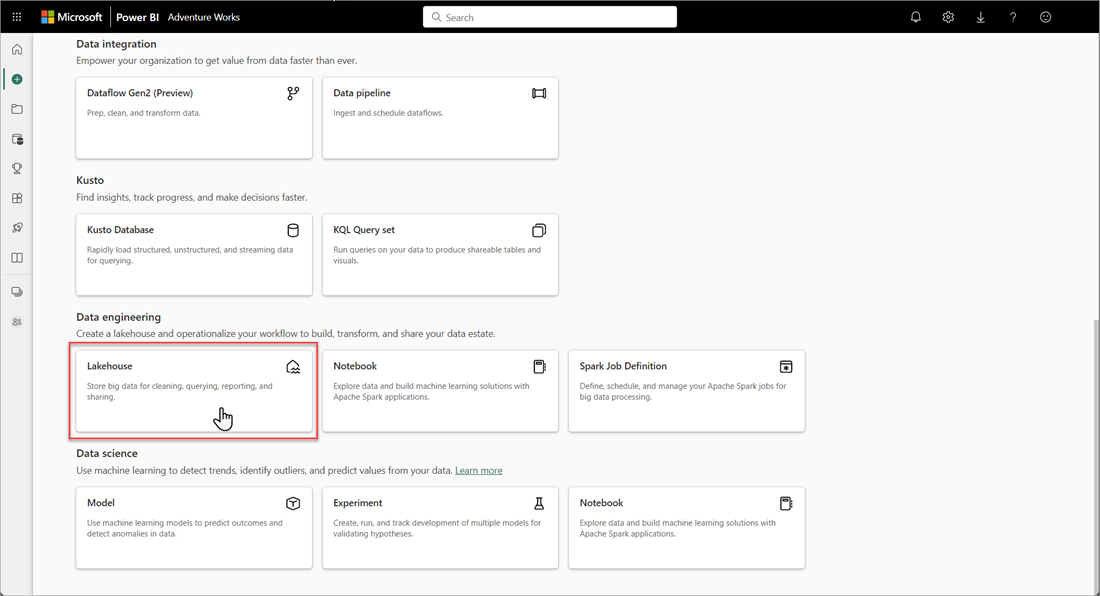
在“新建湖屋”对话框中,输入名称,然后选择“创建”。 该名称只能包含字母数字字符和下划线。
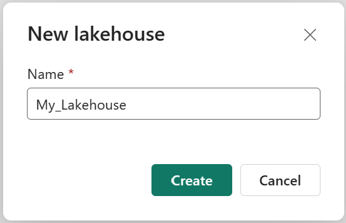
验证新湖屋是否已创建且成功打开。
在湖屋中创建 Delta 表
创建新的 Lakehouse 后,必须至少创建一个 Delta 表,以便 Direct Lake 可以访问某些数据。 Direct Lake 可以读取 parquet 格式的文件,但为了获得最佳性能,最好使用 VORDER 压缩方法压缩数据。 VORDER 使用 Power BI 引擎的本机压缩算法压缩数据。 这样,引擎就可以尽快将数据加载到内存中。
有多个选项可用来将数据加载到湖屋中,包括数据管道和脚本。 以下步骤基于 Azure 开放数据集使用 PySpark 来将 Delta 表添加到湖屋:
在新创建的 Lakehouse 中,选择 打开笔记本,然后选择 新笔记本。
将以下代码片段复制并粘贴到第一个代码单元中,让 SPARK 访问打开的模型,然后按 Shift + Enter 运行代码。
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)验证代码是否成功输出远程 Blob 对象的路径。
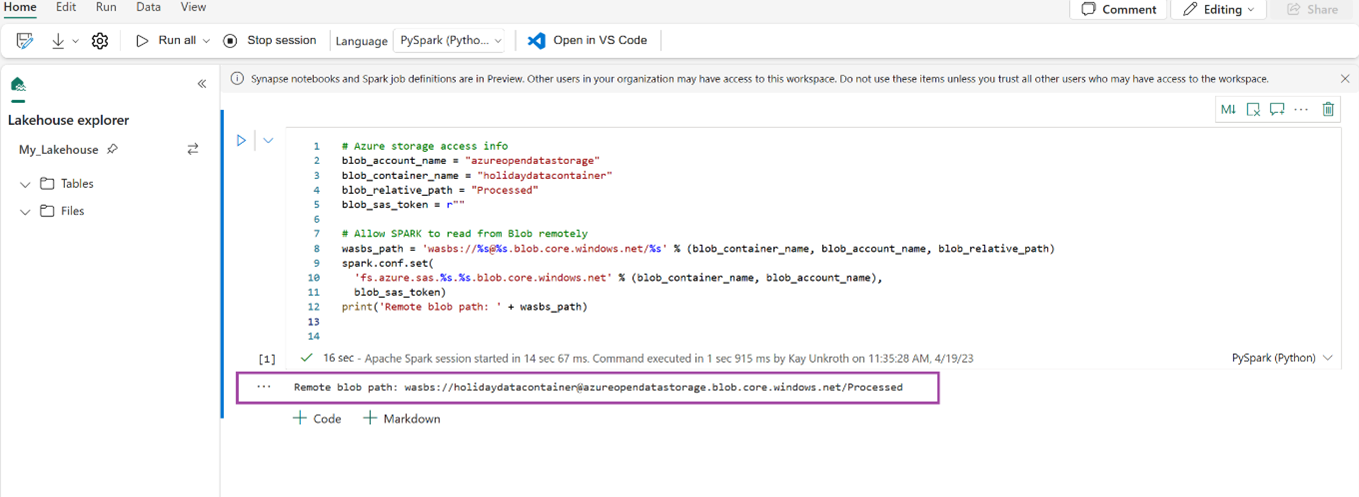
将以下代码复制粘贴到下一个单元格,然后按 Shift + Enter。
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())验证代码是否已成功输出 DataFrame 架构。
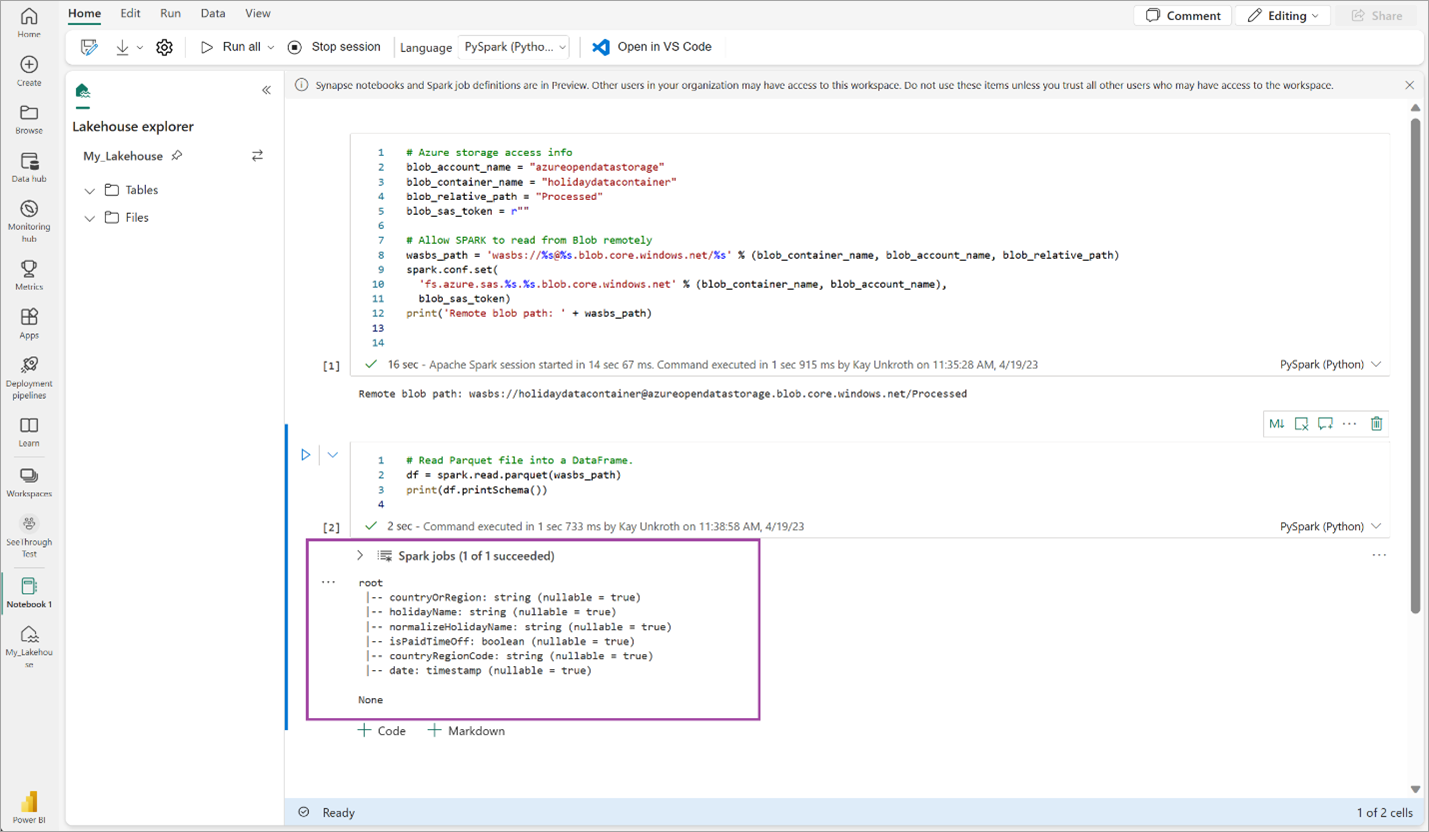
将以下行复制粘贴到下一个单元格中,然后按 Shift + Enter。 第一个指令启用 VORDER 压缩方法,下一个指令将 DataFrame 保存为 Lakehouse 中的 Delta 表。
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")验证所有 SPARK 作业是否已成功完成。 展开 SPARK 作业列表以查看更多详细信息。
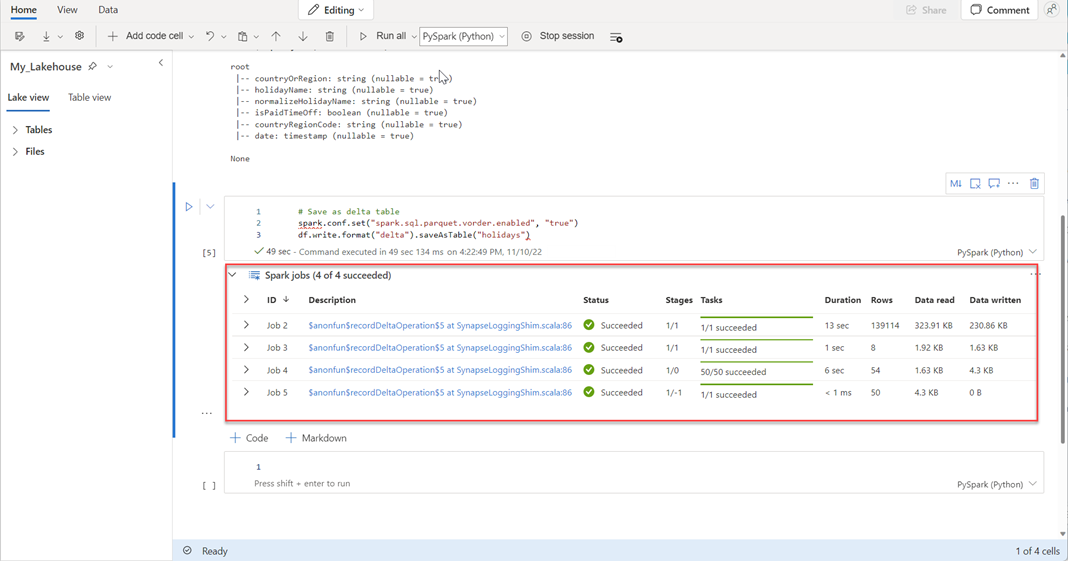
若要验证表是否已成功创建,请在左上角区域 表旁边,选择省略号(...),然后选择 刷新,然后展开 表 节点。
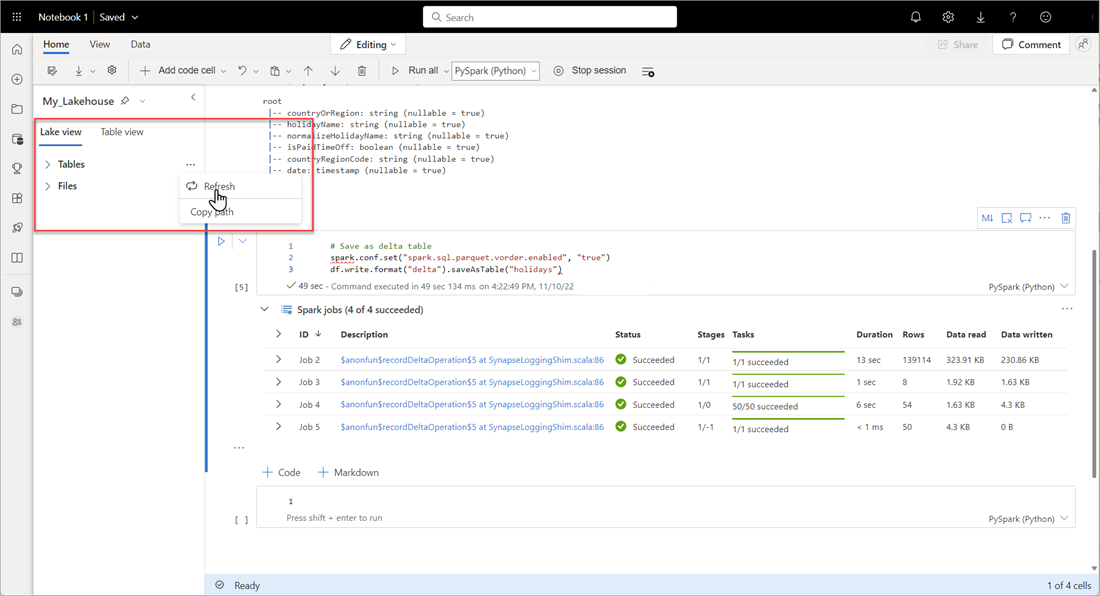
使用与上述方法或其他受支持的方法相同的方法,为要分析的数据添加更多 Delta 表。
为湖屋创建基本的 Direct Lake 模型
在 lakehouse 中,选择 “新建语义模型”,然后在对话框中选择要包含的表。
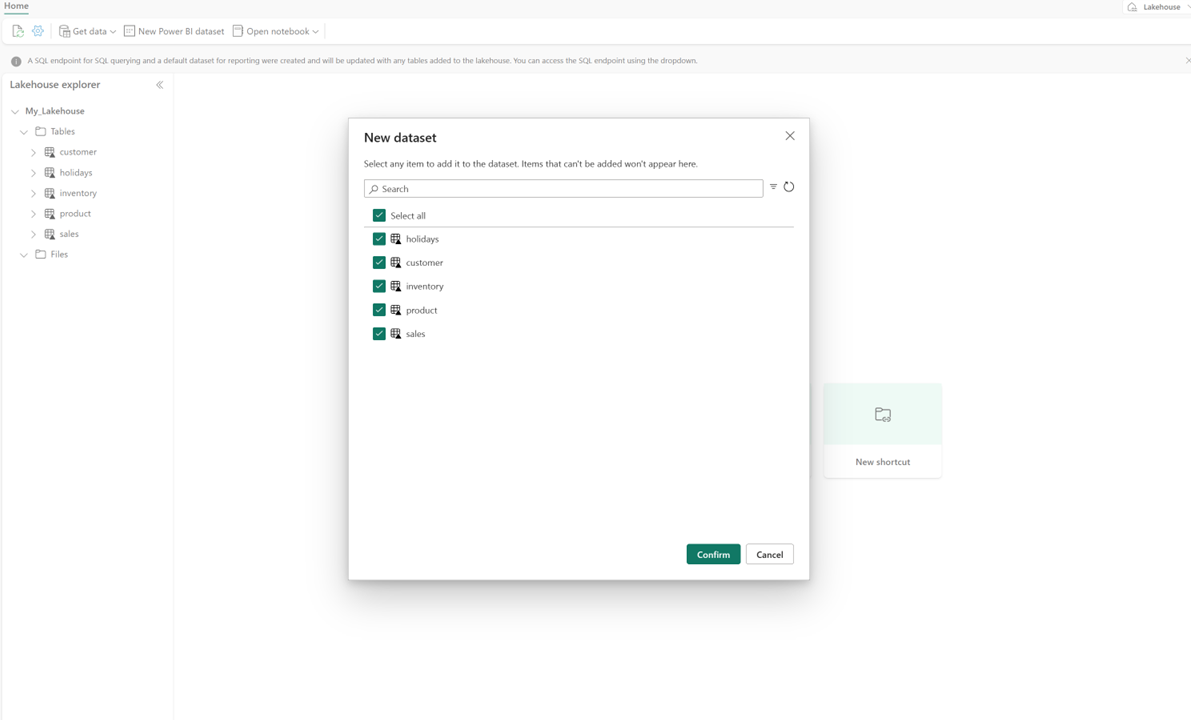
选择“确认”以生成 Direct Lake 模型。 该模型根据湖屋的名称自动保存在工作区中,然后打开模型。
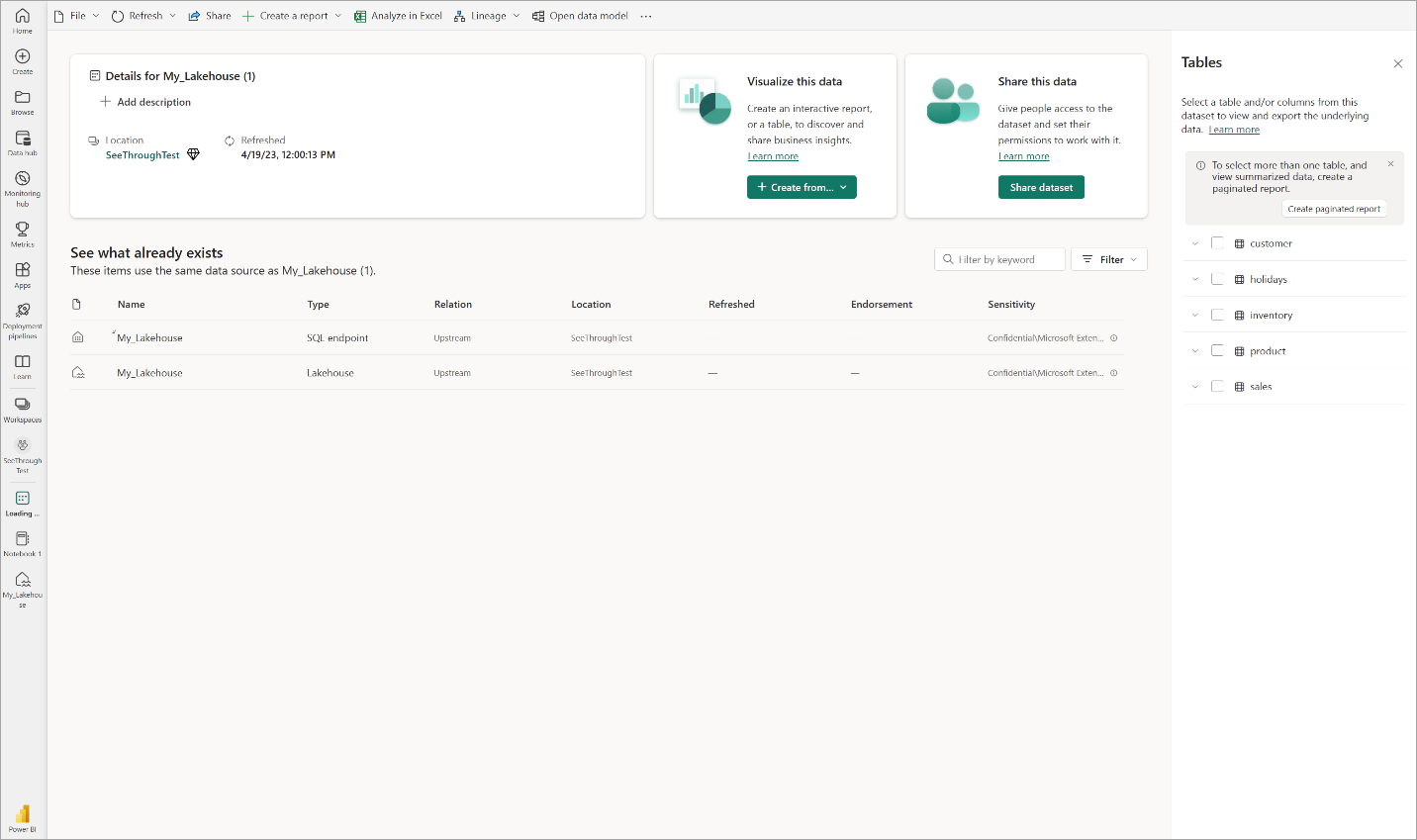
选择 打开数据模型 打开 Web 建模体验,可在其中添加表关系和 DAX 度量值。
显示 Power BI 中的 Web 建模的
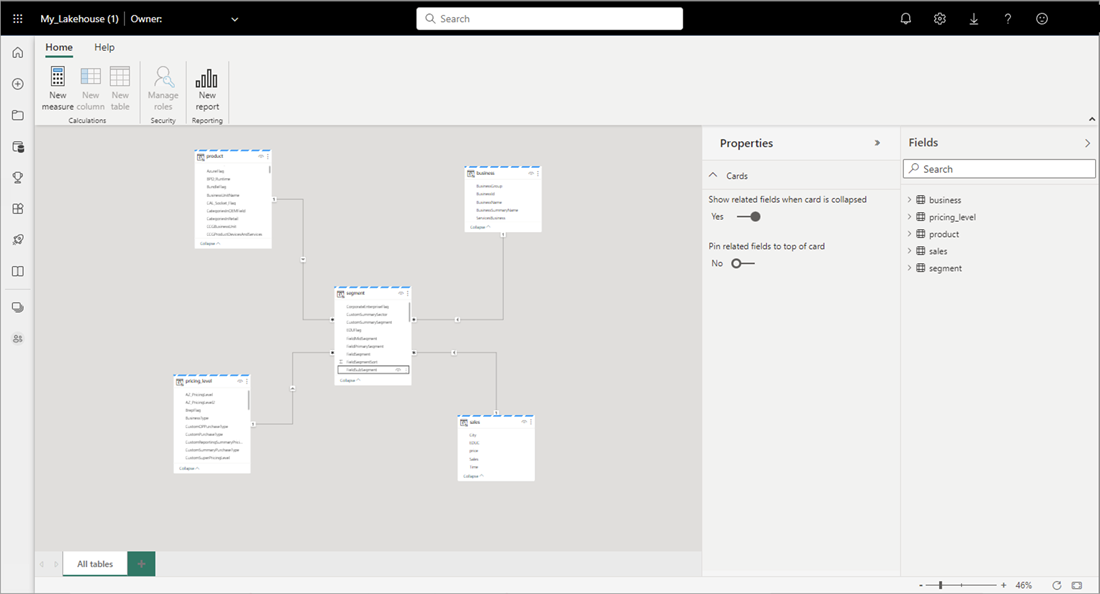
完成添加关系和 DAX 度量值后,可以创建报表、生成复合模型,并通过 XMLA 终结点查询模型的方式与任何其他模型大致相同。