操作说明:从 Microsoft Fabric 访问湖屋和笔记本中的镜像 Azure Cosmos DB 数据(预览)
在本指南中,你将了解如何从 Microsoft Fabric 访问湖屋和笔记本中的镜像 Azure Cosmos DB 数据(预览版)。
重要
Azure Cosmos DB 镜像目前处于预览阶段。 预览期间不支持生产工作负载。 目前,仅支持 Azure Cosmos DB for NoSQL 帐户。
先决条件
- 一个现有的 Azure Cosmos DB for NoSQL 帐户。
- 如果你没有 Azure 订阅,请免费试用 Azure Cosmos DB for NoSQL。
- 如果你当前有 Azure 订阅,请创建新的 Azure Cosmos DB for NoSQL 帐户。
- 现有的 Fabric 容量。 如果没有现有容量,请启动 Fabric 试用版。
- 必须为 Fabric 镜像配置 Azure Cosmos DB for NoSQL 帐户。 有关详细信息,请参阅帐户要求。
提示
在公共预览期间,建议使用现有 Azure Cosmos DB 数据的测试或开发副本,以便从备份中快速恢复。
设置镜像和先决条件
为 Azure Cosmos DB for NoSQL 数据库配置镜像。 如果不确定如何配置镜像,请参阅配置镜像数据库教程。
导航到 Fabric 门户。
使用 Azure Cosmos DB 帐户的凭证创建新的连接和镜像数据库。
等待复制完成数据的初始快照。
访问湖屋和笔记本中的镜像数据
使用湖屋进一步扩展可用于分析 Azure Cosmos DB 的 NoSQL 镜像数据的工具数量。 在这里,你可以使用湖屋构建一个 Spark 笔记本来查询数据。
再次导航到 Fabric 门户主页。
在导航菜单中,选择创建。
选择“创建”,找到“数据工程师”部分,然后选择“湖屋”。
为湖屋命名,然后选择“创建”。
现在,选择“获取数据”,然后选择“新建快捷方式”。 从快捷方式选项列表中,选择 Microsoft OneLake。
从 Fabric 工作区的镜像数据库列表中选择镜像 Azure Cosmos DB for NoSQL 数据库。 选择用于湖屋的表,选择“下一步”,然后选择“创建”。
在湖屋中打开表的上下文菜单,然后选择“新建或现有笔记本”。
新笔记本会自动打开并使用
SELECT LIMIT 1000加载数据帧。使用 Spark 运行
SELECT *之类的查询。df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)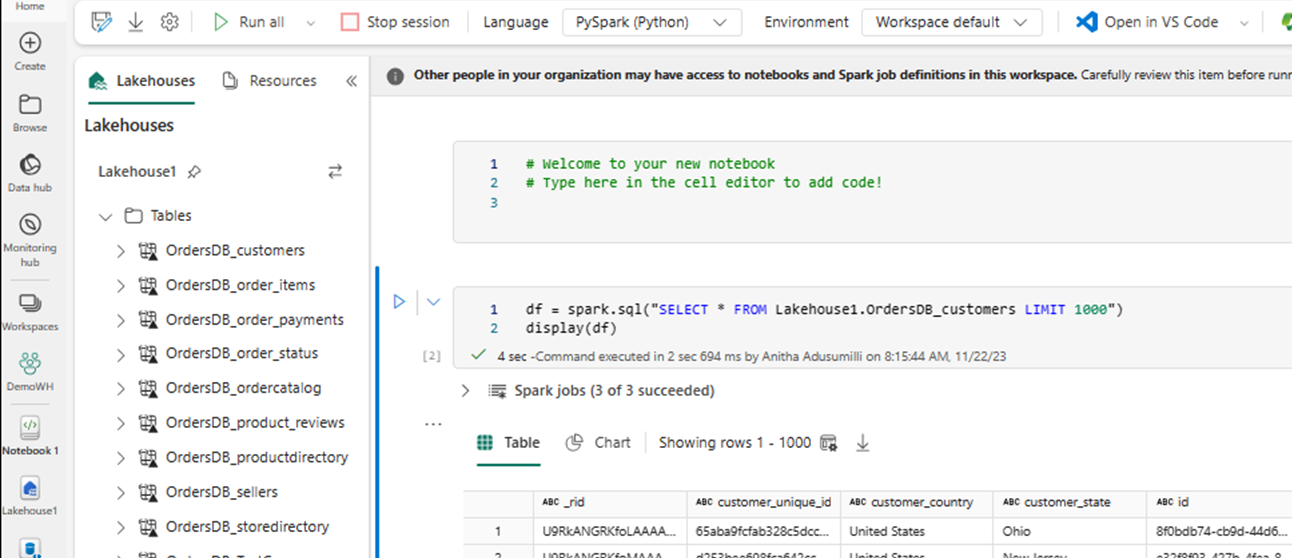
注意
此示例假定了表的名称。 编写 Spark 查询时使用你自己的表。

使用 Spark 写回
最后,可以使用 Spark 和 Python 代码将数据从 Fabric 中的笔记本写回 Azure Cosmos DB 帐户。 你可能需要通过这种方式将分析结果写回 Cosmos DB,然后将其用作 OLTP 应用程序的服务平面。
在笔记本中创建四个代码单元。
首先,查询镜像数据。
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")提示
这些示例代码块中的表名称假定采用特定的数据架构。 可随意将其替换为自己的表和列名称。
现在转换并聚合数据。
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))接下来,将 Spark 配置为使用凭证、数据库名称和容器名称将数据写回 Azure Cosmos DB for NoSQL 帐户。
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }最后,使用 Spark 写回源数据库。
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()运行所有代码单元。
重要
对 Azure Cosmos DB 的写入操作将消耗请求单位 (RU)。