教程:为 Fabric 数据仓库设置 dbt
适用于:✅Microsoft Fabric 中的仓库
本教程将指导你完成设置 dbt 并将第一个项目部署到 Fabric 仓库。
介绍
dbt(数据生成工具)开放源代码框架可简化数据转换和分析工程。 它侧重于分析层中基于 SQL 的转换,并将 SQL 视为代码。 dbt 支持版本控制、模块化、测试和文档。
Microsoft Fabric 的 dbt 适配器可用于创建 dbt 项目,然后会将其部署到 Fabric 数据仓库。
还可以仅通过更改适配器来更改 dbt 项目的目标平台,例如,可将为 Azure Synapse 专用 SQL 池生成的项目在几秒钟内升级到 Fabric 数据仓库。
Microsoft Fabric dbt 适配器的先决条件
按照以下列表安装和设置 dbt 先决条件:
使用 的
pip install dbt-fabric中最新版本的 dbt-fabric 适配器。pip install dbt-fabric注意
通过将
pip install dbt-fabric更改为pip install dbt-synapse并使用以下说明,可以为 Synapse 专用 SQL 池安装 dbt 适配器。请确保使用
pip list命令验证是否已安装 dbt-fabric 及其依赖项:pip list应从此命令返回包和当前版本的长列表。
如果还没有仓库,请创建一个仓库。 可以使用本练习的试用容量:注册 Microsoft Fabric 免费试用版、创建工作区,然后创建仓库。
开始使用 dbt-fabric 适配器
此教程使用 Visual Studio Code,但你可以使用所选的首选工具。
将 jaffle_shop 演示 dbt 项目克隆到计算机上。
- 可以使用 Visual Studio Code 的内置源代码管理克隆存储库。
- 或者,例如,可以使用
git clone命令:
git clone https://github.com/dbt-labs/jaffle_shop.git在 Visual Studio Code 中打开
jaffle_shop项目文件夹。
如果已创建仓库,则可以跳过注册。
创建
profiles.yml文件。 将以下配置添加到profiles.yml。 此文件使用 dbt-fabric 适配器配置与 Microsoft Fabric 中仓库的连接。config: partial_parse: true jaffle_shop: target: fabric-dev outputs: fabric-dev: authentication: CLI database: <put the database name here> driver: ODBC Driver 18 for SQL Server host: <enter your SQL analytics endpoint here> schema: dbo threads: 4 type: fabric注意
将
type从fabric更改为synapse,以根据需要将数据库适配器切换为 Azure Synapse Analytics。 通过更改数据库适配器,可以更新任何现有 dbt 项目的数据平台。 有关详细信息,请参阅受支持的数据平台的 dbt 列表。在 Visual Studio Code 终端中向 Azure 验证自己的身份。
- 如果使用的是 Azure CLI 身份验证,请在 Visual Studio Code 终端中运行
az login。 - 有关在 Microsoft Fabric 中进行的服务主体身份验证或其他 Microsoft Entra ID(以前称为 Azure Active Directory)身份验证,请参阅 dbt(数据生成工具)设置和 dbt 资源配置。 有关详细信息,请参阅 Microsoft Entra 身份验证作为 Microsoft Fabric 中 SQL 身份验证的替代方法。
- 如果使用的是 Azure CLI 身份验证,请在 Visual Studio Code 终端中运行
现在,你已准备好测试连接。 在 Visual Studio Code 终端中运行
dbt debug以测试与仓库的连接。dbt debug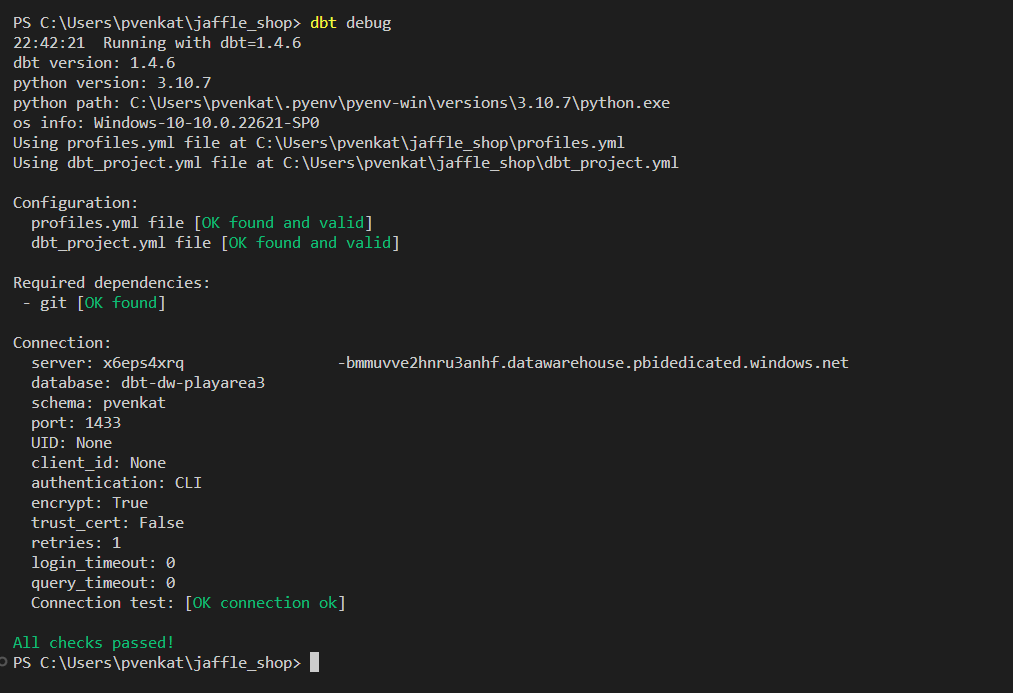
通过所有检查,这意味着可以使用 dbt-fabric 适配器从
jaffle_shopdbt 项目连接仓库。现在,可以测试适配器是否正常工作。 首先运行
dbt seed以将示例数据插入仓库。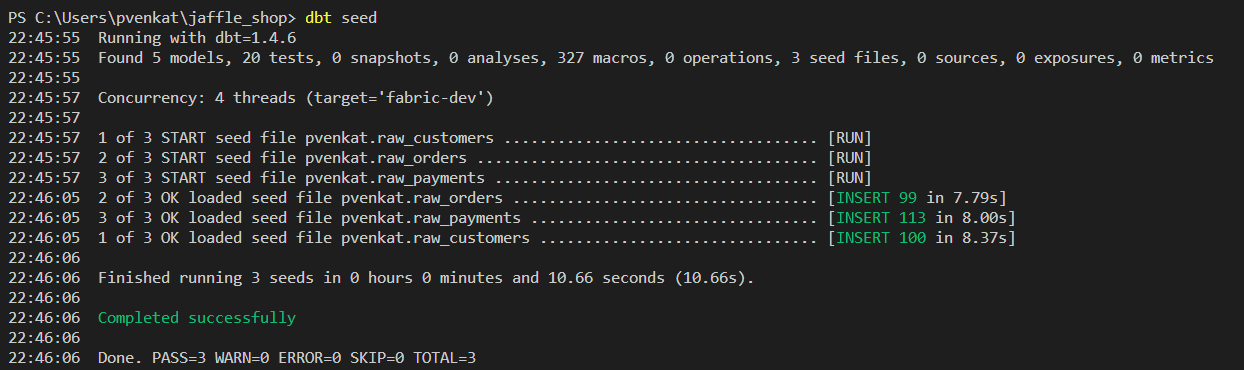
运行
dbt run以针对某些测试验证数据。dbt run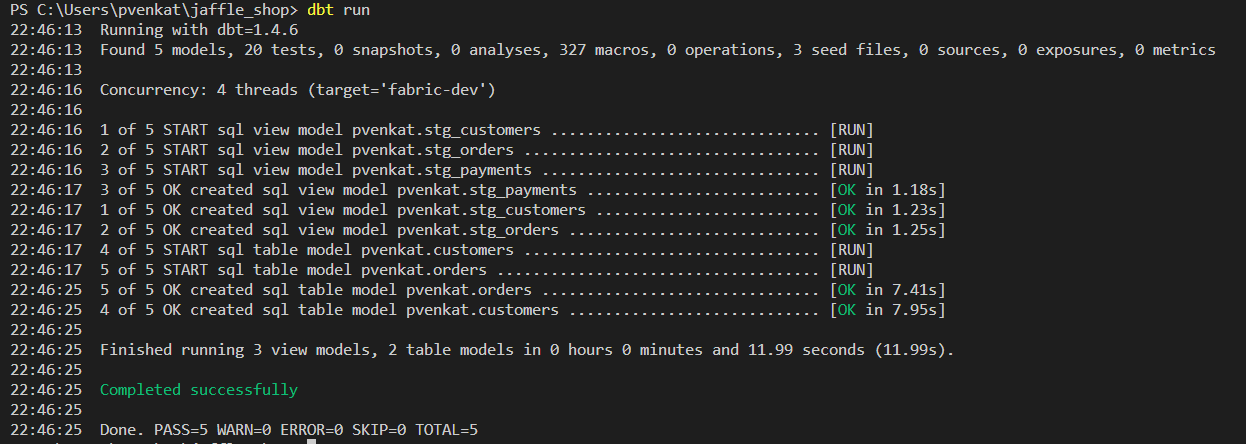
运行
dbt test以运行演示 dbt 项目中定义的模型。dbt test




现已将 dbt 项目部署到 Fabric 数据仓库。
在不同仓库之间移动
在不同的仓库之间移动 dbt 项目非常简单。 可以使用以下三个步骤的过程快速迁移任何受支持仓库上的 dbt 项目:
安装新适配器。 有关详细信息和完整安装说明,请参阅 dbt 适配器。
更新
type文件中的profiles.yml属性。生成项目。
Fabric 数据工厂中的 dbt
与常用的工作流管理系统 Apache Airflow 集成时,dbt 将成为编排数据转换的强大工具。 Airflow 的计划和任务管理功能使数据团队能够自动执行 dbt 运行。 它可以确保定期进行数据更新,并保持一致的高质量数据流进行分析和报告。 这种组合方法将 dbt 的转换专业知识与 Airflow 的工作流管理结合使用,提供高效可靠的数据管道,最终产生更快、更深入的数据驱动决策。
Apache Airflow 是一个开源平台,用于以编程方式创建、计划和监视复杂的数据工作流。 它允许定义一组称为运算器的任务,这些任务可以组合成有向无环图 (DAG) 以表示数据管道。
有关通过仓库使 dbt 可操作化的详细信息,请参阅通过 Microsoft Fabric 中的数据工厂使用 dbt 转换数据。
注意事项
使用 dbt-fabric 适配器时要考虑的重要事项:
Fabric 支持适用于用户主体、用户标识和服务主体的 Microsoft Entra ID(以前称为 Azure Active Directory)身份验证。 用于在仓库上交互工作的建议身份验证模式是 CLI(命令行接口)和使用服务主体实现自动化。
查看 Fabric 数据仓库不支持的 T-SQL (Transact-SQL) 命令。
使用
Create Table as Select(CTAS)、DROP和CREATE时,dbt-fabric 适配器支持某些 T–SQL 命令,例如ALTER TABLE ADD/ALTER/DROP COLUMN、MERGE、TRUNCATE、sp_rename。查看不支持的数据类型,以了解受支持的和不受支持的数据类型。
可以通过访问问题 · microsoft/dbt-fabric · GitHub 来记录 GitHub 上有关 dbt-fabric 适配器的问题。