Fabric 数据仓库中的缓存
适用于:✅Microsoft Fabric 中的 SQL 分析终结点和仓库
从数据湖中检索数据是一项非常重要的输入/输出 (IO) 操作,对查询性能有很大影响。 Fabric 数据仓库采用经过优化的访问模式来增强从存储中读取数据的过程和提高查询执行速度。 此外,它会智能地利用本地缓存最大程度减少对远程存储的读取需求。
缓存是一种通过减少 IO 操作来优化数据处理应用性能的技术。 缓存将经常访问的数据和元数据存储在较快的存储层(如本地内存或本地 SSD 磁盘)中,以便可以直接通过缓存更快地处理后续请求。 如果某个查询之前曾访问过某组数据,则任何后续查询都可以直接从内存中缓存中检索这些数据。 此方法可显著减少 IO 延迟,因为与从远程存储提取数据相比,本地内存操作明显更快。
缓存对用户是完全透明的。 查询会缓存访问的所有数据,无论访问对象的来源是什么,不管是仓库表还是 OneLake 快捷方式,即使是引用非 Azure 服务的 OneLake 快捷方式。
本文稍后将介绍两种类型的缓存:
- 内存中缓存
- 磁盘缓存
内存中缓存
查询访问和检索存储中的数据时,会执行转换过程,将数据从基于文件的原始格式转码为内存中缓存中的高度优化的结构。

缓存中数据的组织采用一种针对分析查询进行了优化的压缩列格式。 每列数据存储在一起,并与其他列分开处理,这样可以更好地压缩,因为类似的数据值一起存储可减少内存占用。 当查询需要对特定列执行操作时(如聚合或筛选),引擎可以更高效地运作,因为无需处理其他列的不必要的数据。
此外,这种列式存储还有利于并行处理,这可以显著加快大型数据集的查询执行速度。 引擎可以利用新式多核处理器,同时对多个列执行操作。
这种方法对于查询时需要扫描大量数据来执行聚合、筛选和其他数据操作的分析工作负载尤其有用。
磁盘缓存
有些数据集非常大,无法保存在内存中缓存中。 为了持续对这些数据集进行快速查询,仓库会利用磁盘空间作为内存中缓存的扩充容量。 并且,加载到内存中缓存中的任何信息都会序列化为 SSD 缓存。
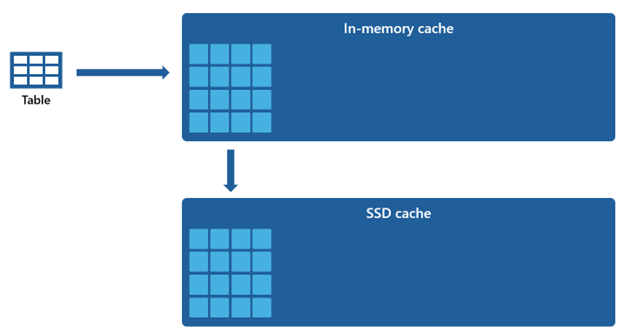
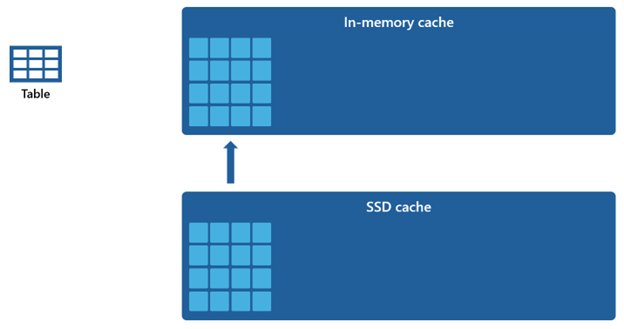
由于内存中缓存的容量比 SSD 缓存小,因此从内存中缓存中删除的数据会长时间保留在 SSD 缓存中。 当后续查询请求这些数据时,会以相较远程存储提取时快得多的速度将数据从 SSD 缓存检索到内存中缓存中,最终实现更为一致的查询性能。
缓存管理
缓存会一直保持活动状态,并在后台流畅运行,无需任何人工干预。 无需禁用缓存,因为这样做会不可避免地导致查询性能明显下降。
缓存机制由 Microsoft Fabric 自动协调和维护,所以没有为用户提供手动清理缓存的功能。
缓存在事务层面的完全一致性可确保存储的数据在最初加载到内存中缓存后,经过任何修改(例如执行了数据操作语言 (DML) 操作)后仍可确保数据的一致性。
缓存达到其容量阈值时,如果首次读取新数据,将从缓存中删除长时间未使用的对象。 设置此操作是为了让新数据有空间流入,并持续实现最优缓存利用策略。