教程:使用 R 预测航班延误
本教程演示了 Microsoft Fabric 中 Synapse 数据科学工作流的端到端示例。 它使用 nycflights13 数据和 R,来预测飞机是否到达迟到超过30分钟。 然后,它使用预测结果生成交互式 Power BI 仪表板。
本教程介绍如何:
- 使用 tidymodels 包(recipes、parsnip、rsample、workflows)来处理数据并训练机器学习模型
- 将输出数据作为增量表写入湖屋
- 生成 Power BI 可视化报表以直接访问该 Lakehouse 中的数据
先决条件
获取 Microsoft Fabric 订阅。 或者,注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左下侧的体验切换器切换到 Fabric。
打开或创建笔记本。 若要了解如何操作,请参阅 如何使用 Microsoft Fabric 笔记本。
将语言选项设置为 SparkR (R) 以更改主要语言。
将笔记本附加到湖屋。 在左侧,选择 添加,以添加现有的湖屋或创建新的湖屋。
安装软件包
安装nycflights13包来使用本教程中的代码。
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
浏览数据
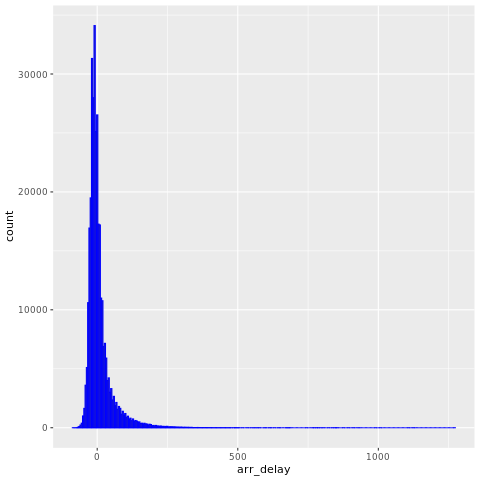
nycflights13 数据提供有关2013年纽约市附近抵达的325,819个航班的信息。 首先,查看航班延误的分布情况。 此图显示到达延迟的分布是右倾斜的。 它在高值中具有长尾。
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
加载数据,对变量进行一些更改:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
在生成模型之前,请考虑一些对于预处理和建模非常重要的特定变量。
变量 arr_delay 是一个因子变量。 对于逻辑回归模型训练,结果变量是一个因子变量非常重要。
glimpse(flight_data)
此数据集中大约有16%的航班到达时晚了30多分钟。
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
dest 功能有 104 个航班目的地。
unique(flight_data$dest)
有16个不同的运营商。
unique(flight_data$carrier)
拆分数据
将单个数据集拆分为两组:训练 集和 测试 集。 在训练数据集中保留原始数据集中的大多数行(作为随机选择的子集)。 使用训练数据集来适应模型,并使用测试数据集来度量模型性能。
使用 rsample 包创建包含有关如何拆分数据的信息的对象。 然后,使用另外两个 rsample 函数为训练和测试集创建数据帧:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
创建食谱和角色
为简单的逻辑回归模型创建食谱。 在训练模型之前,请使用食谱创建新的预测器,并执行模型所需的预处理。
使用 update_role() 函数,使食谱知道 flight 和 time_hour 是变量,其自定义角色称为 ID。 角色可以具有任何字符值。 公式包括训练集中除作为预测器的 arr_delay 之外的所有变量。 该配方保留这两个 ID 变量,但不将它们用作结果或预测器。
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
若要查看当前变量和角色集,请使用 summary() 函数:
summary(flights_rec)
创建功能
执行一些特征工程来改进模型。 航班日期可能对迟到的可能性产生合理的影响。
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
它可能有助于添加从可能对模型具有重要性的日期派生的模型术语。 从单个日期变量派生以下有意义的特征:
- 星期几
- 月份
- 日期是否对应于假日
将三个步骤添加到食谱中:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
使用食谱调整模型
使用逻辑回归对航班数据建模。 首先,使用 parsnip 包生成模型规范:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
使用 workflows 包将 parsnip 模型(lr_mod)与食谱捆绑在一起(flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
训练模型
此函数可以准备食谱,并从生成的预测器训练模型:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
使用帮助程序函数 xtract_fit_parsnip() 和 extract_recipe() 从工作流中提取模型或食谱对象。 在此示例中,提取拟合的模型对象,然后使用 broom::tidy() 函数来获取整齐的模型系数表。
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
预测结果
对 predict() 的单次调用使用训练的工作流 (flights_fit) 通过看不见的测试数据进行预测。 predict() 方法将食谱应用于新数据,然后将结果传递给拟合的模型。
predict(flights_fit, test_data)
获取 predict() 的输出以返回预测类:late 与 on_time。 但是,对于每个航班的预测类概率,请将 augment() 与模型结合使用并结合测试数据,以将它们保存在一起:
flights_aug <-
augment(flights_fit, test_data)
查看数据:
glimpse(flights_aug)
评估模型
我们现在有一个包含预测类概率的 tibble。 在前几行中,模型正确预测了五个实时航班(.pred_on_time 的值是 p > 0.50)。 但是,总共有 81,455 行要预测。
我们需要一个指标,评估模型在预测延迟到达方面的准确性,并与结果变量arr_delay的真实状态进行比较。
使用曲线接收器操作特征(AUC-ROC)下的面积作为指标。 使用 yardstick 软件包中的 roc_curve() 和 roc_auc()进行计算。
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
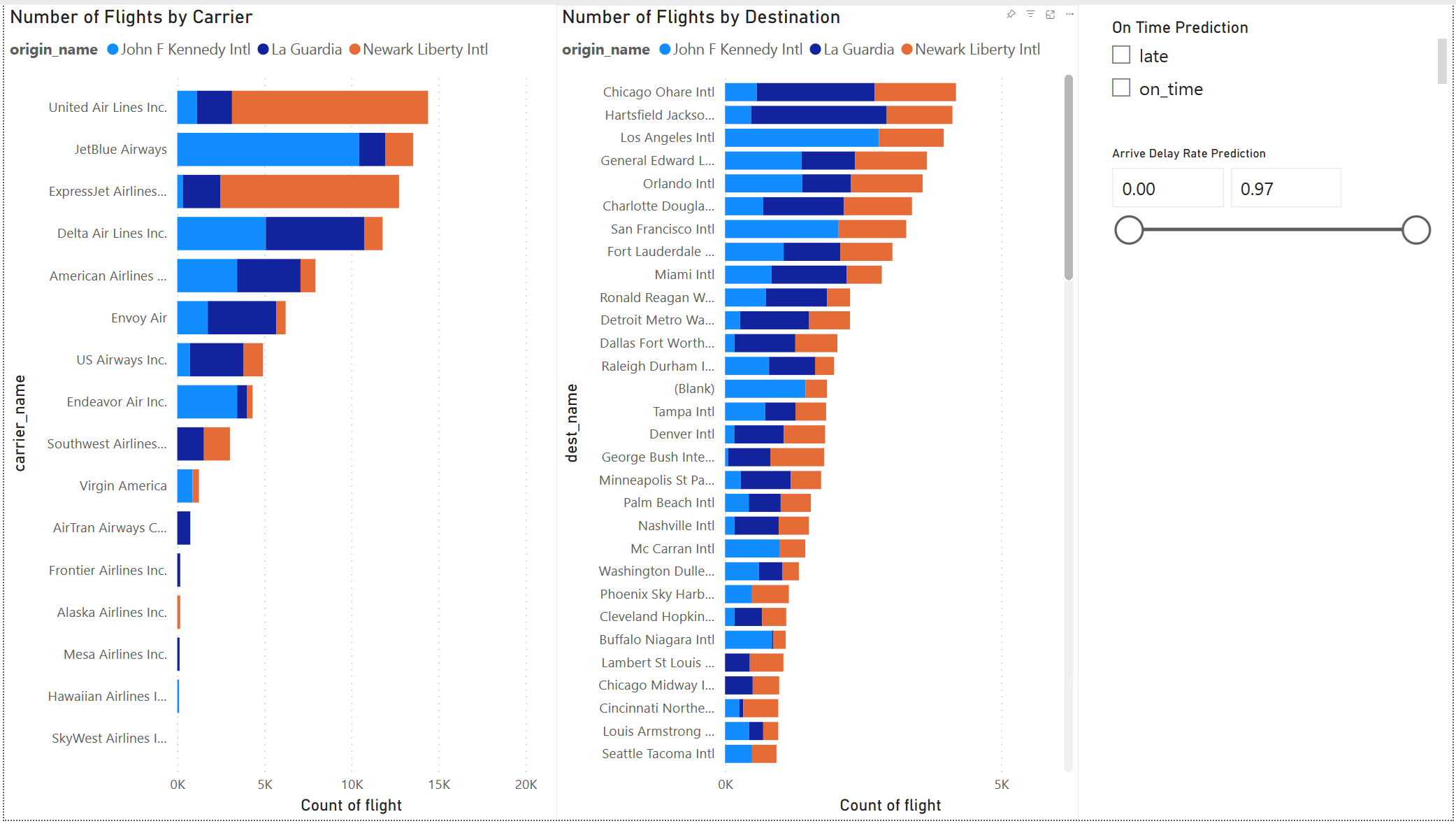
生成 Power BI 报表
模型结果看起来不错。 使用航班延误预测结果生成交互式 Power BI 仪表板。 仪表板显示航空公司的航班数量,以及按目的地列出的航班数。 仪表板可以按延迟预测结果进行筛选。
在预测结果数据集中包含运营商名称和机场名称:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
查看数据:
glimpse(flights_clean)
将数据转换为 Spark 数据帧:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
将数据写入湖屋中的增量表:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
使用增量表创建语义模型。
在左侧,选择“OneLake”
选择附加到你的笔记本的湖屋
选择 打开
选择 新语义模型
为新的语义模型选择 nycflight13,然后选择 确认
你已创建语义模型。 选择“新建报表”
从 数据 中选择或拖动字段,并将可视化效果 窗格拖到报表画布上以生成报表
若要创建本部分开头显示的报表,请使用以下可视化效果和数据:
 堆积条形图,其中包含:
堆积条形图,其中包含:- Y 轴:carrier_name
- X 轴:航班。 为“聚合”选择“计数”
- 图例:origin_name
- 堆积条形图,其中包含:
- Y 轴:dest_name
- X 轴:航班。 为“聚合”选择“计数”
- 图例:origin_name
 切片器具有:
切片器具有:- 字段:_pred_class
- 切片器具有:
- 字段:_pred_late