在 Microsoft Fabric 中使用 PREDICT 进行机器学习模型评分
Microsoft Fabric 允许用户通过可缩放的 PREDICT 函数来操作机器学习模型。 此函数支持任何计算引擎中的批处理评分。 用户可直接从 Microsoft Fabric 笔记本或给定 ML 模型的项页生成批量预测。
在在本文中,了解如何通过自己编写代码或使用引导式 UI 体验(可为你处理批量评分)来应用 PREDICT。
先决条件
获取 Microsoft Fabric 订阅。 或者注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左下侧的体验切换器切换到 Fabric。
限制
- 对于这组有限的 ML 模型风格,目前支持 PREDICT 函数风格:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- Sklearn
- Spark
- statsmodels
- TensorFlow
- XGBoost
- PREDICT 要求你将 ML 模型保存为 MLflow 格式,并填充其签名
- PREDICT 不支持具有多张量输入或输出的 ML 模型
从笔记本调用 PREDICT
PREDICT 支持 Microsoft Fabric 注册表中的 MLflow 打包模型。 如果工作区中已存在一个已训练和注册的 ML 模型,则可跳到步骤 2。 如果没有,步骤 1 提供了示例代码来指导你训练示例逻辑回归模型。 可以使用此模型在过程结束时生成批量预测。
训练 ML 模型并将其注册到 MLflow。 下一示例代码使用 MLflow API 创建机器学习试验,然后为 scikit-learn 逻辑回归模型启动 MLflow 运行。 然后,模型版本将存储和注册到 Microsoft Fabric 注册表中。 访问“如何使用 scikit-learn 训练 ML 模型”资源,了解有关训练模型和跟踪自己的试验的详细信息。
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )以 Spark 数据帧的形式加载测试数据。 若要使用上一步中训练的 ML 模型生成批量预测,需要 Spark 数据帧形式的测试数据。 在以下代码中,将
test变量值替换为自己的数据。# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))创建
MLFlowTransformer对象以加载 ML 模型进行推理。 若要创建MLFlowTransformer对象以生成批预测,必须执行以下操作:- 指定需要作为模型输入的
test数据帧列(在本例中为所有这些列) - 为新输出列选择一个名称(在本例中为
predictions) - 提供用于生成这些预测的正确模型名称和模型版本。
如果使用自己的 ML 模型,请替换输入列、输出列名称、模型名称和模型版本的值。
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- 指定需要作为模型输入的
使用 PREDICT 函数生成预测。 若要调用 PREDICT 函数,使用转换器 API、Spark SQL API 或 PySpark 用户定义函数 (UDF)。 以下各节演示如何使用调用 PREDICT 函数的不同方法,利用前面步骤中定义的测试数据和 ML 模型生成批量预测。
使用转换器 API 的 PREDICT
此代码使用转换器 API 调用 PREDICT 函数。 如果使用自己的 ML 模型,请替换模型和测试数据的值。
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
使用 Spark SQL API 的 PREDICT
此代码使用 Spark SQL API 调用 PREDICT 函数。 如果使用自己的 ML 模型,请将 model_name、model_version 和 features 的值替换为自己的模型名称、模型版本和特征列。
注意
使用 Spark SQL API 进行预测生成仍要求创建 MLFlowTransformer 对象(如步骤 3 所示)。
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
使用用户定义函数的 PREDICT
此代码使用 PySpark UDF 调用 PREDICT 函数。 如果使用自己的 ML 模型,请替换模型和特征的值。
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
从 ML 模型的项页面生成 PREDICT 代码
从任何 ML 模型的项页中,可选择以下选项之一,以使用 PREDICT 函数启动对特定模型版本的批预测生成:
- 将代码模板复制到笔记本中,并自行自定义参数
- 使用引导 UI 体验生成 PREDICT 代码
使用引导式 UI 体验
引导式 UI 体验将引导你完成以下步骤:
- 选择用于评分的源数据
- 将数据正确映射到 ML 模型输入
- 指定模型输出的目标
- 创建使用 PREDICT 生成和存储预测结果的笔记本
若要使用引导体验,
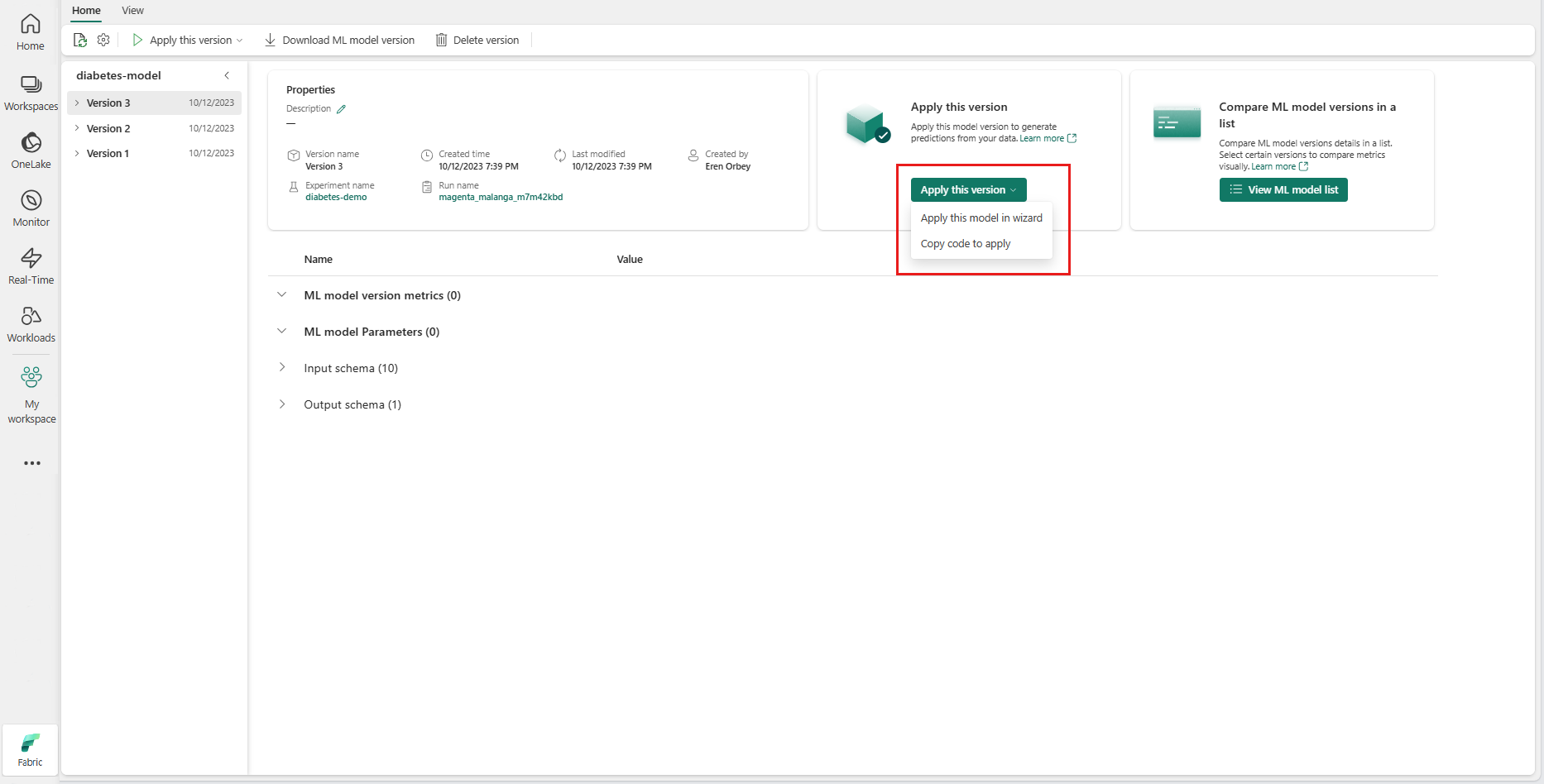
导航到给定 ML 模型版本的项页。
从“应用此版本”下拉列表中,选择“在向导中应用此模型”。
在“选择输入表”步骤中,“应用 ML 模型预测”窗口打开。
从当前工作区中的某个湖屋中选择一个输入表。
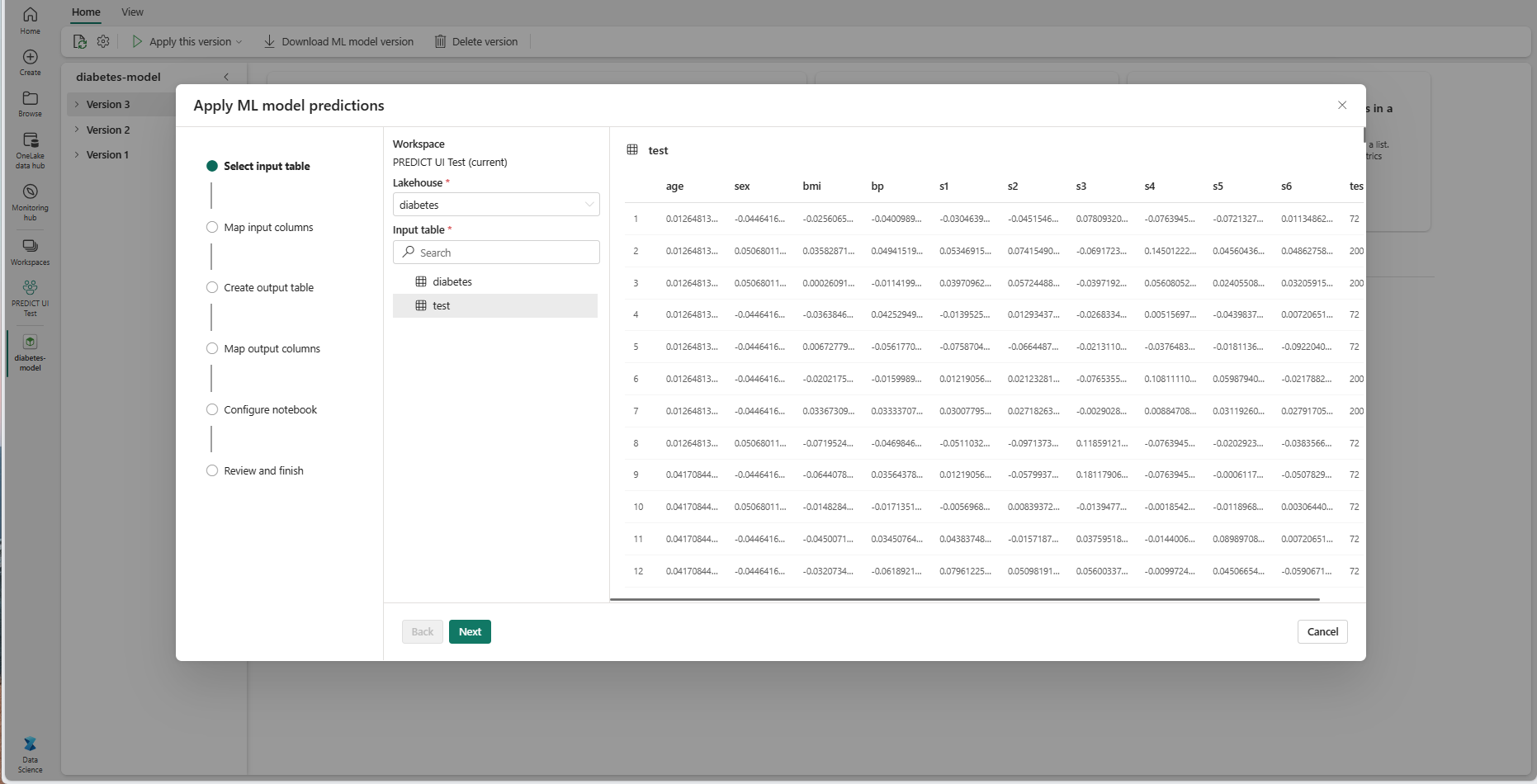
选择“下一步”转到“映射输入列”步骤。
将源表中的列名映射到 ML 模型的输入字段,这些字段从模型的签名中拉取。 必须为模型的所有必填字段提供输入列。 此外,源列数据类型必须与模型的预期数据类型匹配。
提示
如果输入表列的名称与在 ML 模型签名中记录的列名匹配,向导会预填充此映射。
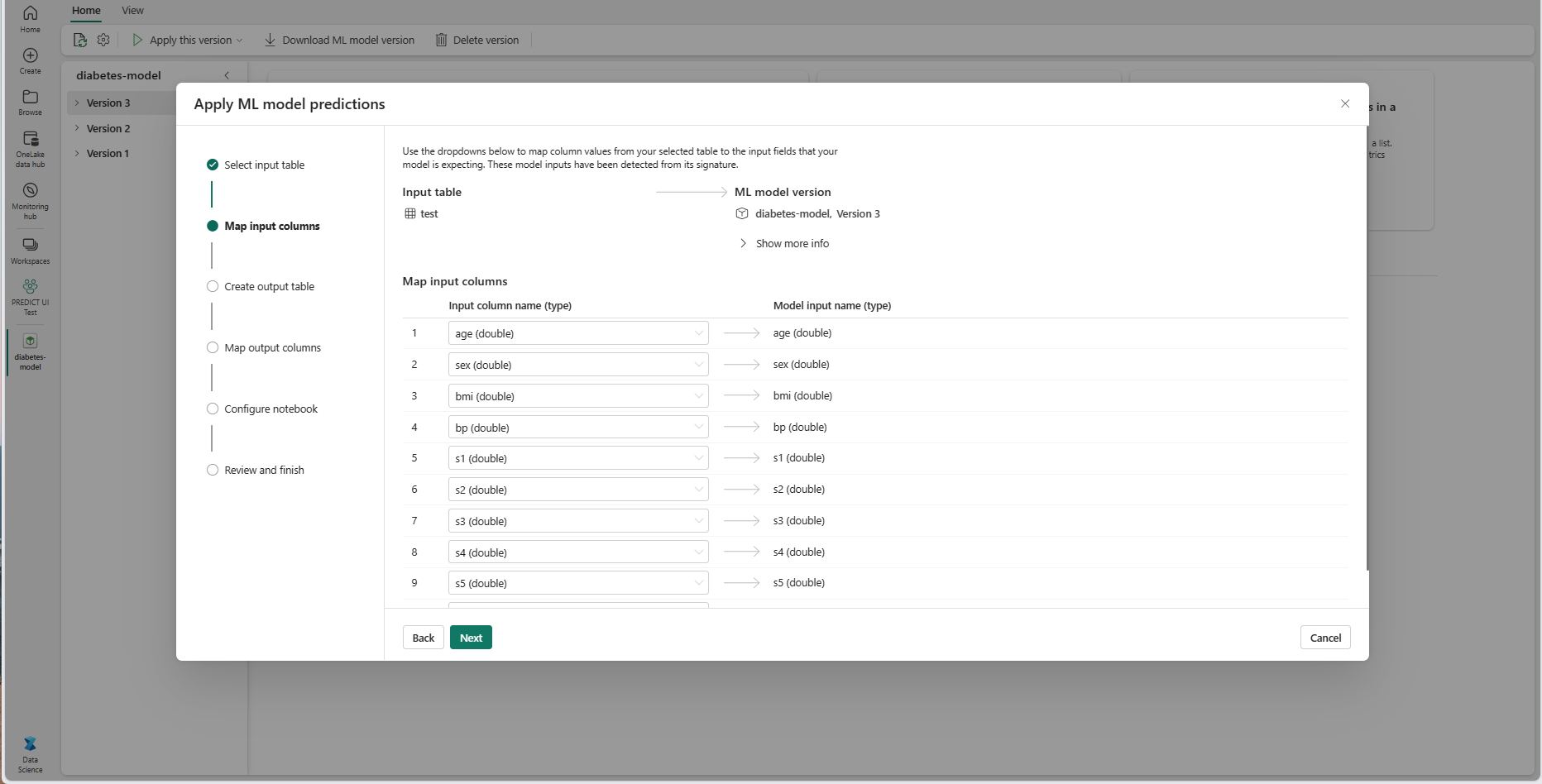
选择“下一步”转到“创建输出表”步骤。
为当前工作区的所选湖屋中的新表提供名称。 此输出表存储 ML 模型的输入值,且它将预测值追加到该表。 默认情况下,输出表在与输入表相同的湖屋中创建。 可更改目标湖屋。
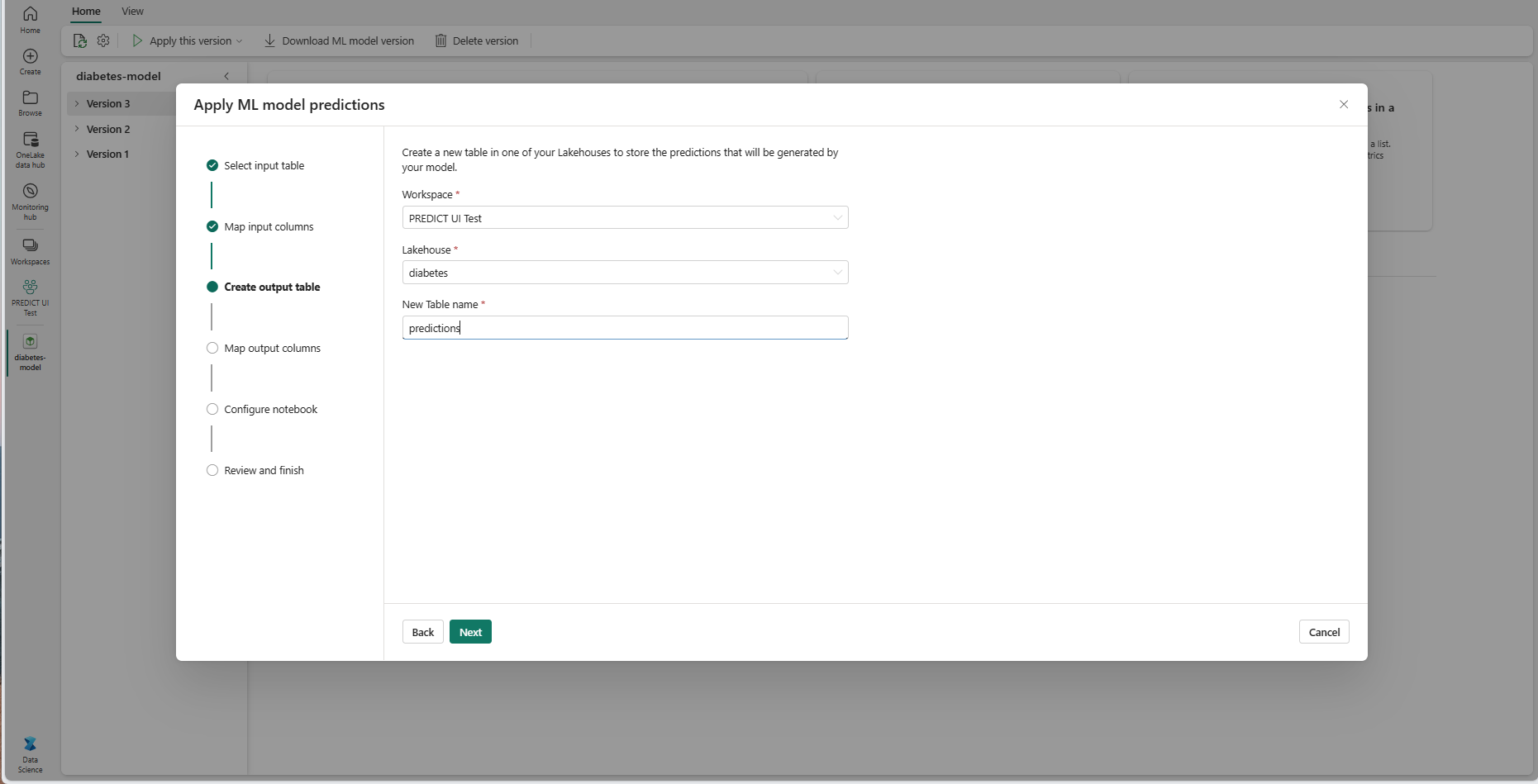
选择“下一步”转到“映射输出列”步骤。
使用提供的文本字段,对存储 ML 模型预测的输出表的列进行命名。
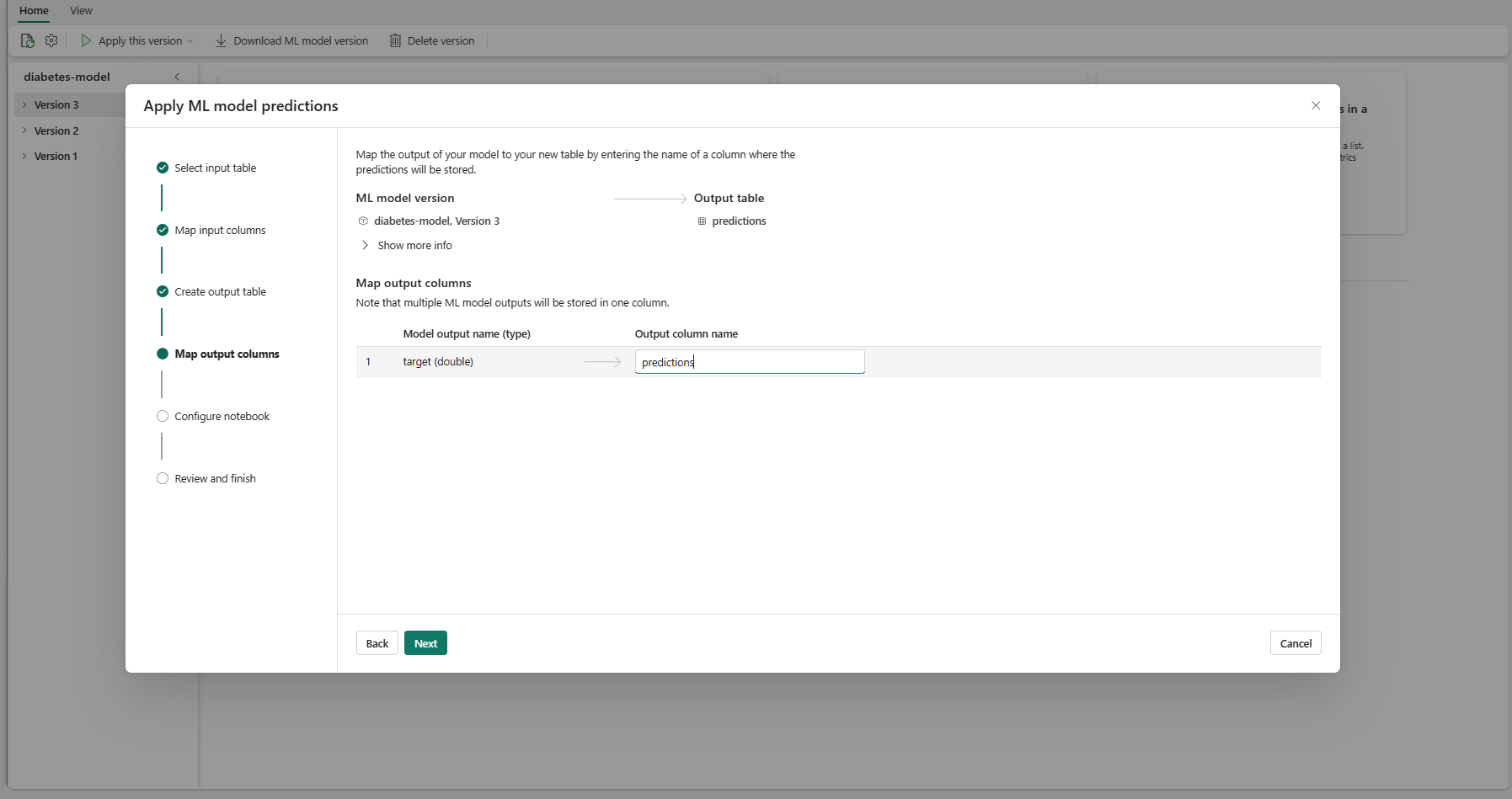
选择 下一步 以转到“配置笔记本”步骤。
为运行生成的 PREDICT 代码的新笔记本提供名称。 向导在此步骤中显示生成的代码的预览。 如需要,可将代码复制到剪贴板,并将其粘贴到现有笔记本中。
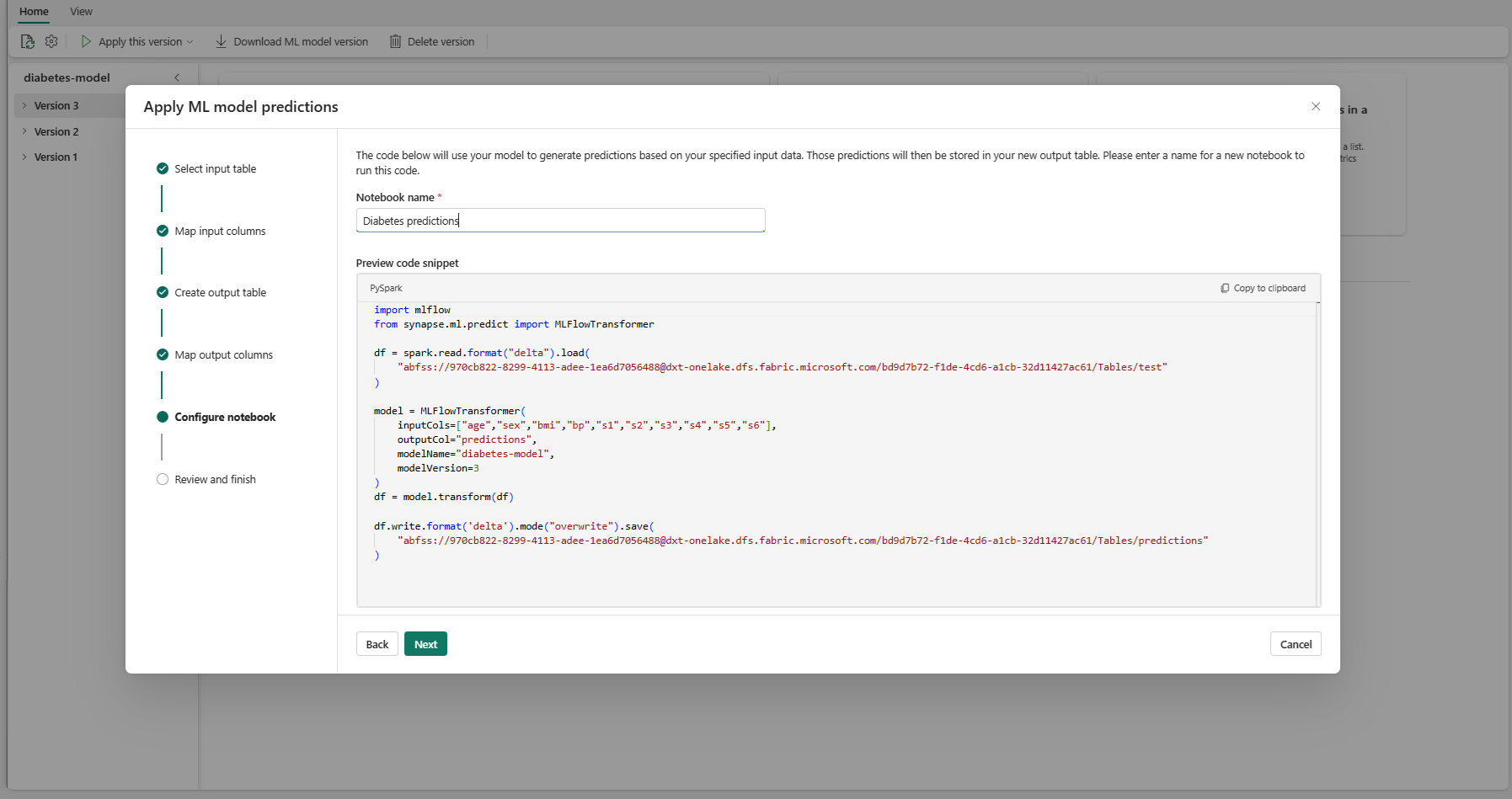
选择“下一步”转到“查看并完成”步骤。
查看摘要页上的详细信息,然后选择“创建笔记本”,将新笔记本及其生成的代码添加到工作区。 你将直接转到该笔记本,可以在其中运行代码来生成和存储预测。
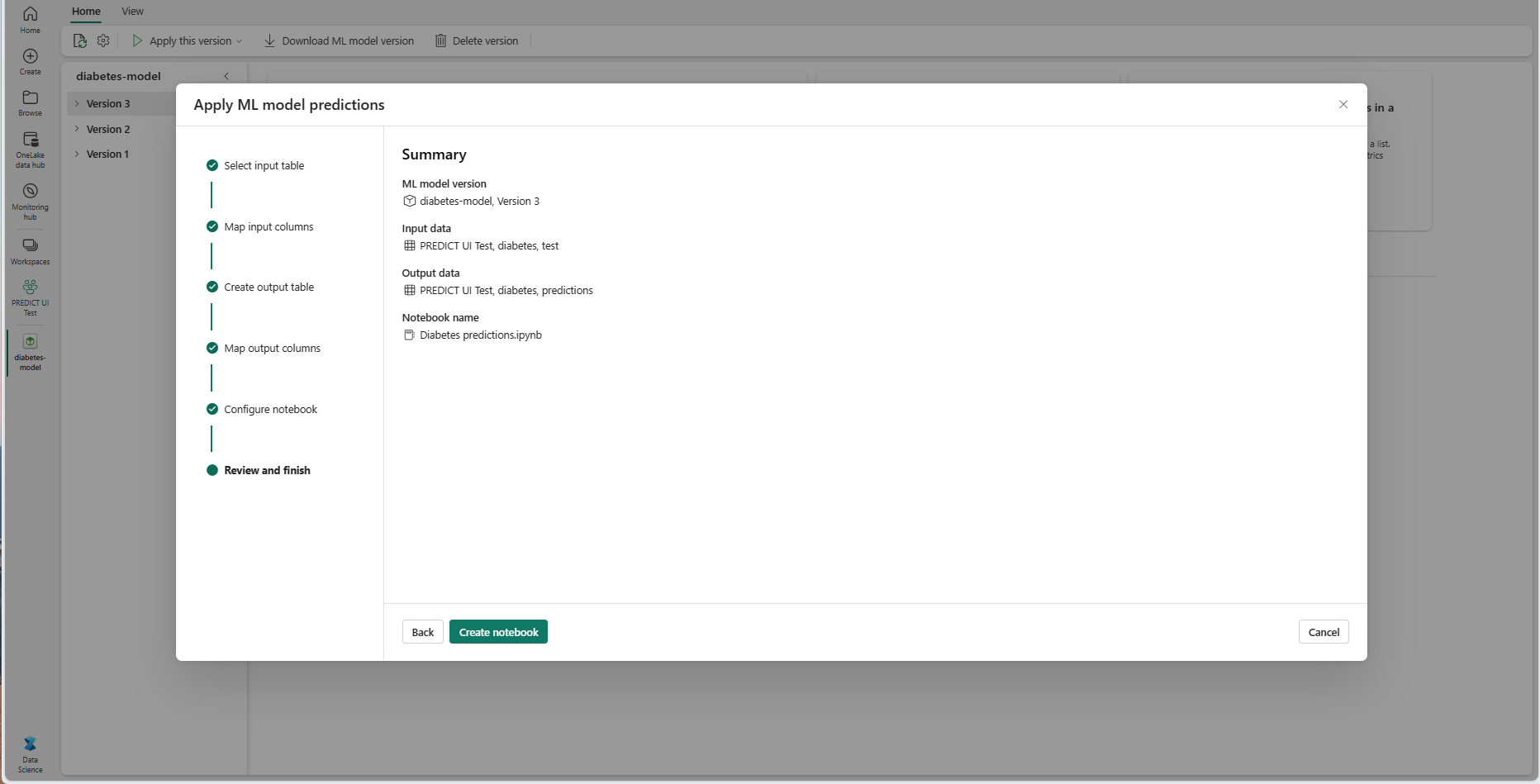







使用可自定义的代码模板
若要使用代码模板生成批量预测,请执行以下操作:
- 转到给定 ML 模型版本的项页面。
- 从“应用此版本”下拉列表中选择“复制要应用的代码”。 通过选择,可以复制可自定义的代码模板。
可以将此代码模板粘贴到笔记本中,以使用 ML 模型生成批量预测。 若要成功运行代码模板,必须手动替换以下值:
<INPUT_TABLE>:向 ML 模型提供输入的表的文件路径<INPUT_COLS>:输入表中要输入 ML 模型的列名数组<OUTPUT_COLS>:输出表中存储预测的新列的名称<MODEL_NAME>:用于生成预测的 ML 模型的名称<MODEL_VERSION>:用于生成预测的 ML 模型的版本<OUTPUT_TABLE>:存储预测的表的文件路径

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)