模块 1:使用数据工厂创建管道
此模块需要 10 分钟时间,内容是使用管道中的复制活动将源存储中的原始数据引入数据 Lakehouse 的 Bronze 表。
模块 1 中的概要步骤如下:
- 创建数据管道。
- 在管道中使用复制活动将示例数据加载到数据湖屋中。
创建数据管道
需要具有活动订阅的 Microsoft Fabric 租户帐户。 创建一个免费帐户。
确保你具有已启用 Microsoft Fabric 的工作区:创建工作区。
登录 Power BI。
选择屏幕左下角的默认 Power BI 图标,然后选择 Fabric。
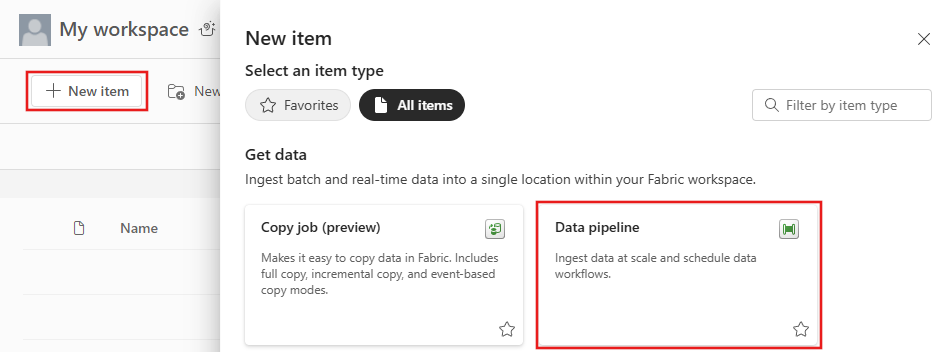
从“工作区”选项卡中选择工作区,然后选择“+ 新建项”,然后选择 数据管道。 提供管道名称。 然后选择“创建”。
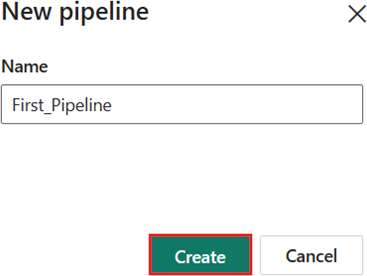
使用管道中的复制活动将示例数据加载到数据湖屋中
步骤 1:使用复制助手配置复制活动。
选择“复制数据助手”打开复制助手工具。
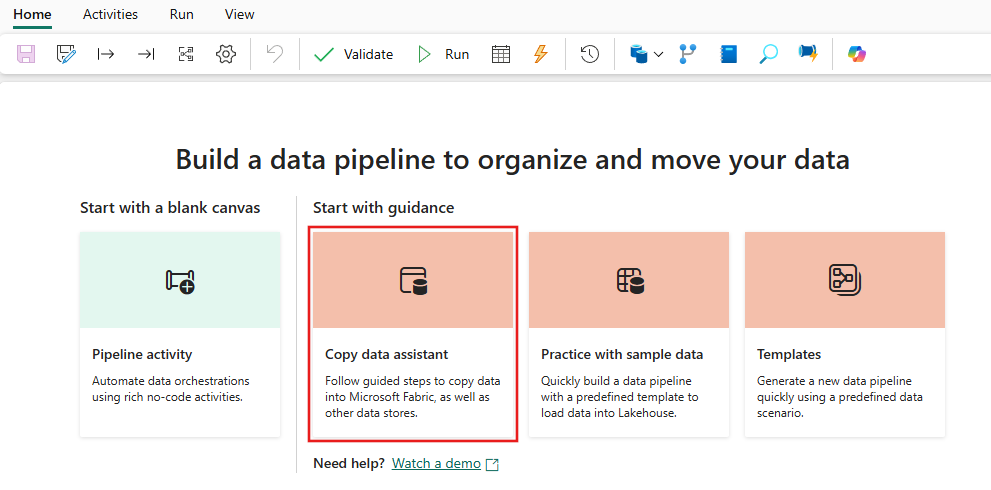
步骤 2:在复制助手中进行配置。
显示了“复制数据”对话框,突出显示了第一步“选择数据源”。 从对话框顶部的选项中选择“示例数据”,然后选择“NYC Taxi - Green”。
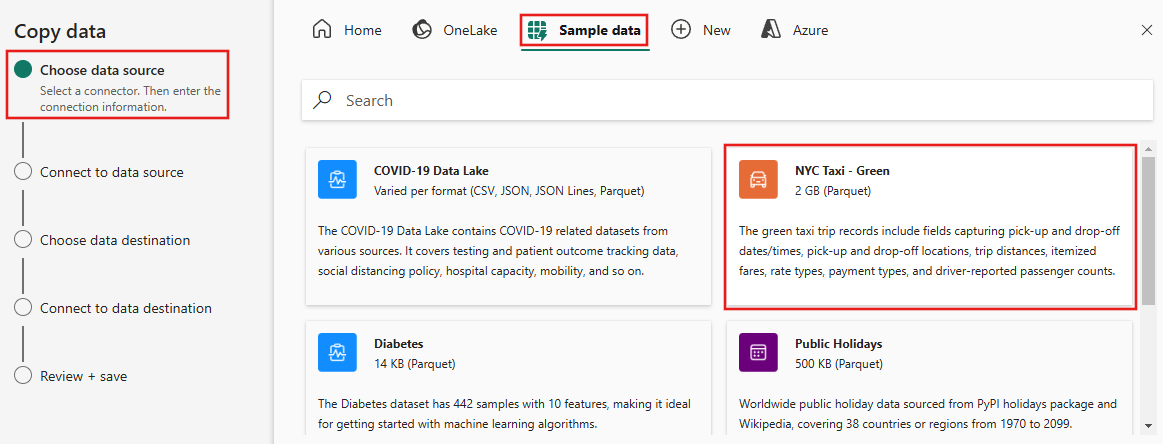
数据源预览接下来显示在 “连接到数据源” 页面上。 查看,然后选择“下一步”。
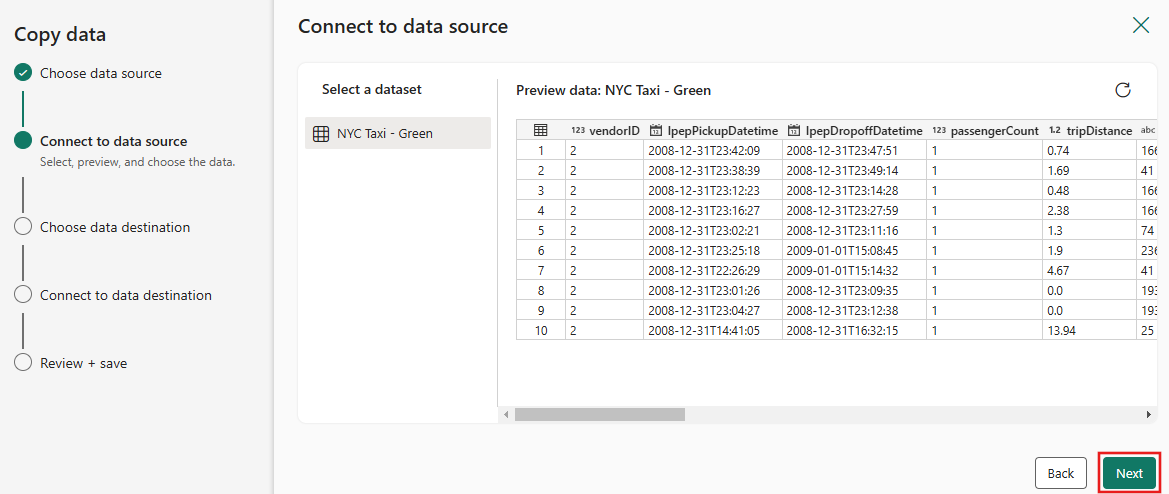
对于复制助手的“选择数据目标”步骤,请选择“湖屋”,然后选择“下一步”。
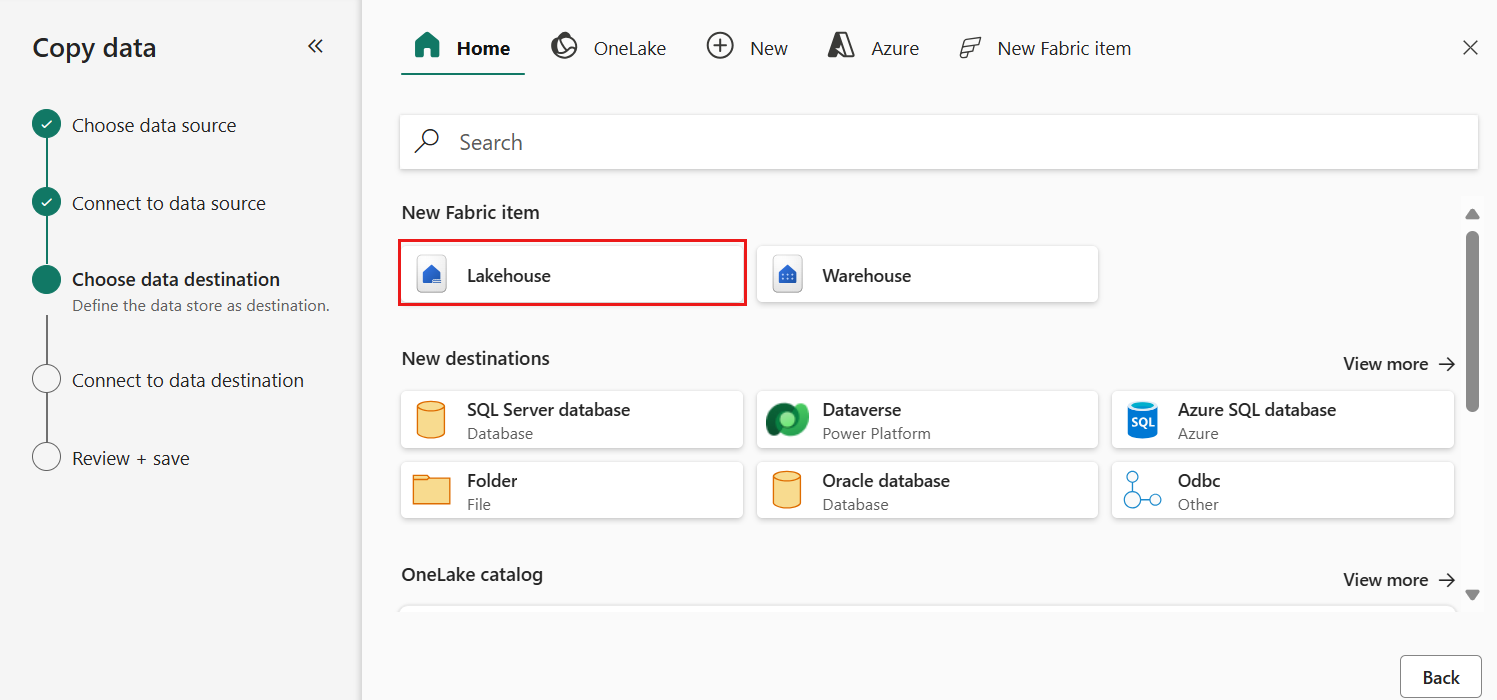
在显示的数据目标配置页上,选择“创建新湖屋”,并输入新湖屋的名称。 然后再次选择 下一步。
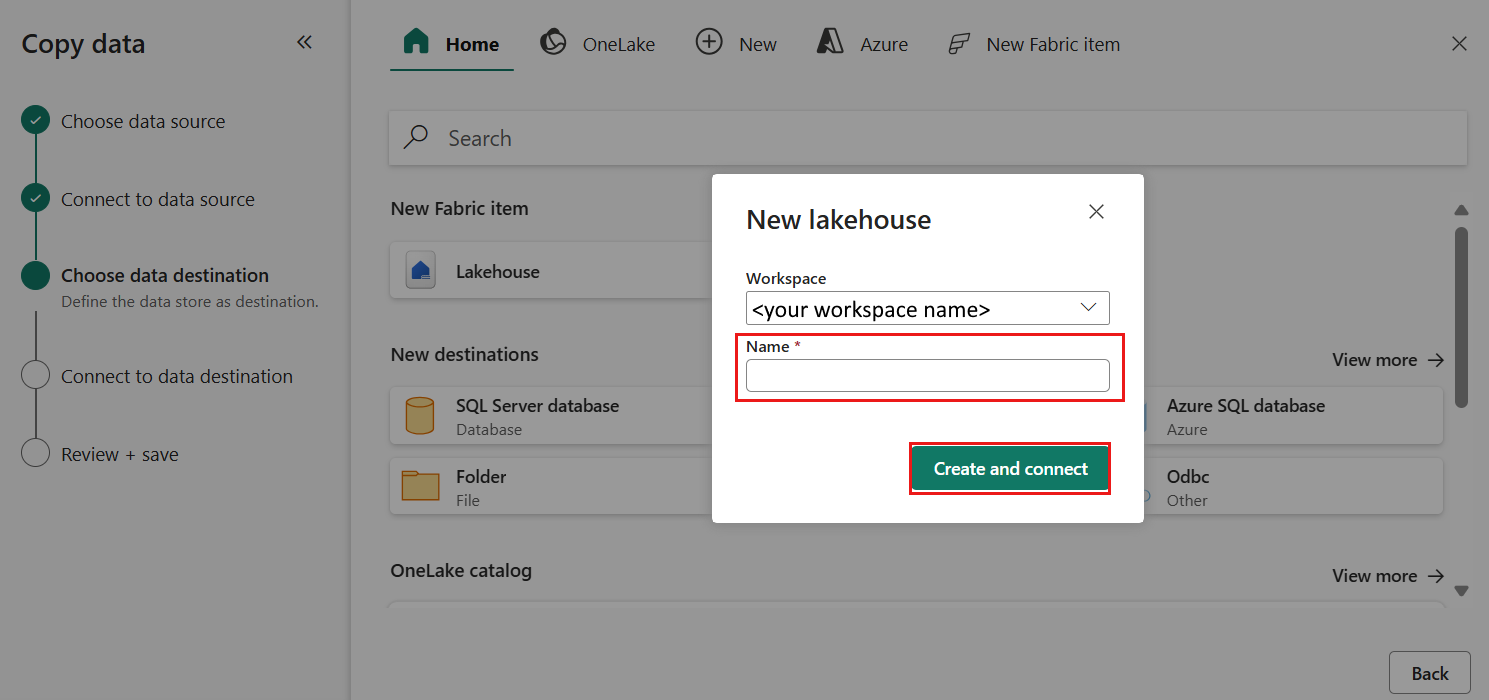
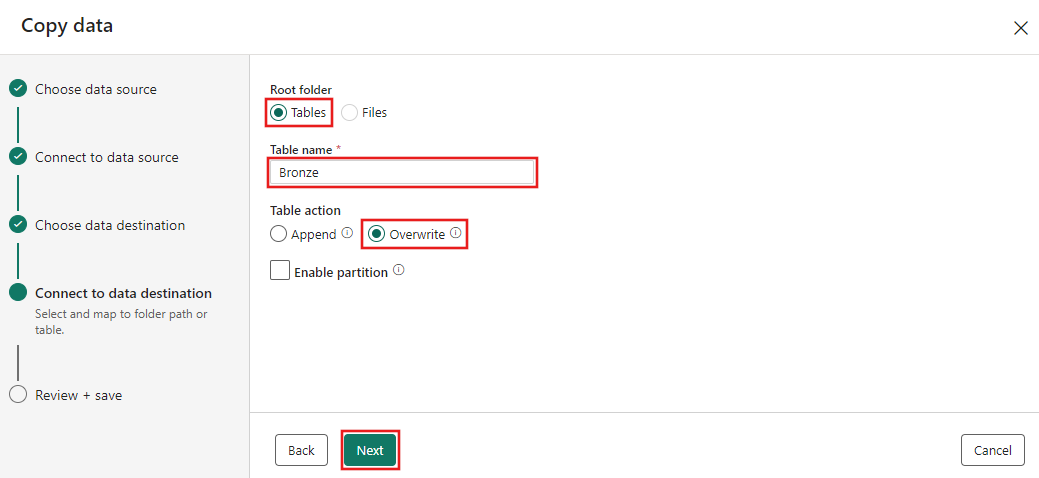
现在,在“选择并映射到文件夹路径或表”页上配置湖屋目标的详细信息。 为“根文件夹”选择“表”,提供表名称,然后选择“覆盖”操作。 请勿选中在你选择了“覆盖”表操作后显示的“启用分区”复选框。
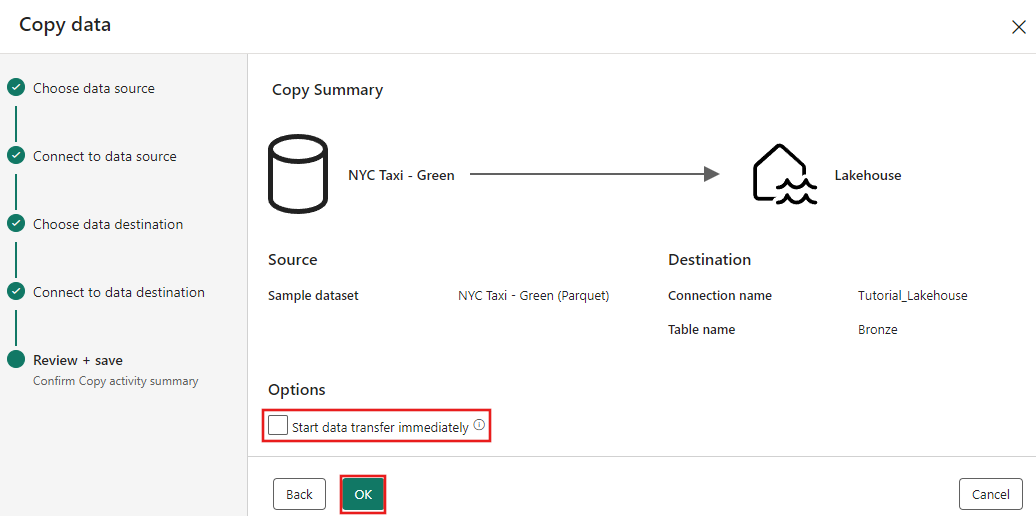
最后,在复制数据助手的“查看 + 保存”页上,查看配置。 在本教程中,请取消选中 “立即开始数据传输” 复选框,因为我们会在下一步骤中手动运行该活动。 然后选择“确定”。
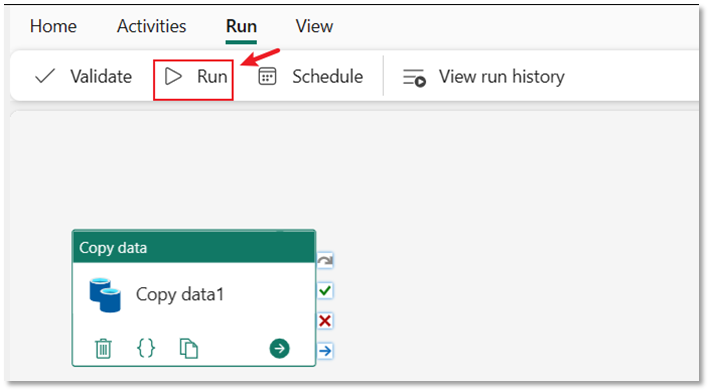
步骤 3:运行并查看复制活动的结果。
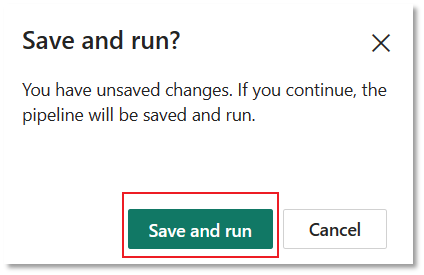
在管道编辑器中选择“运行”选项卡。 然后选择 运行 按钮,接着在提示中选择 保存并运行,以执行复制活动。
可以监视该运行,并在管道画布下方的“输出”选项卡上检查结果。 选择“运行详情”按钮(当鼠标悬停在运行中的管道上时显示的“眼镜”图标)以查看详情。
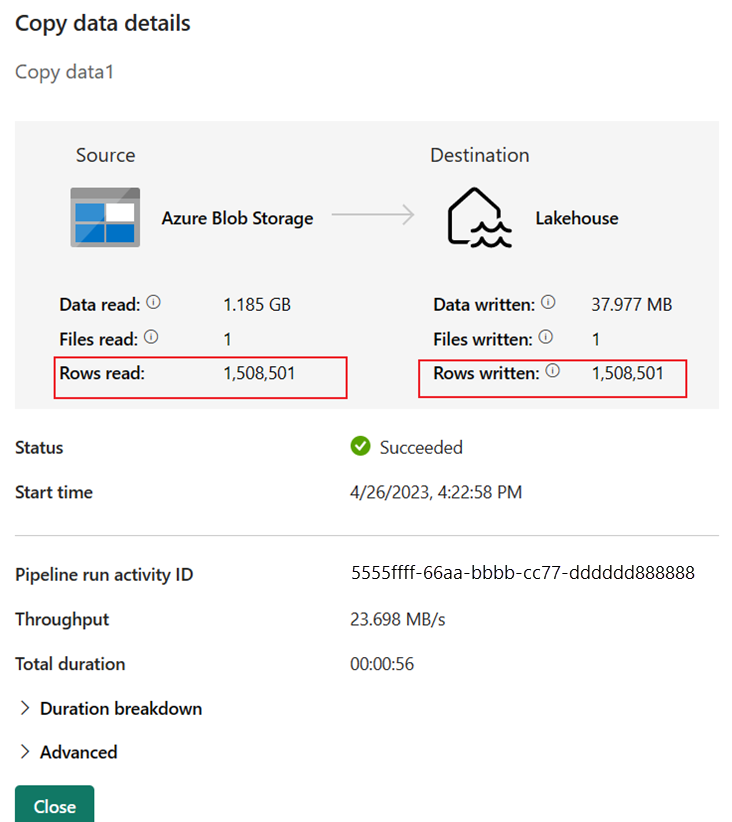
运行详细信息显示读取和写入的行数为 1,508,501。
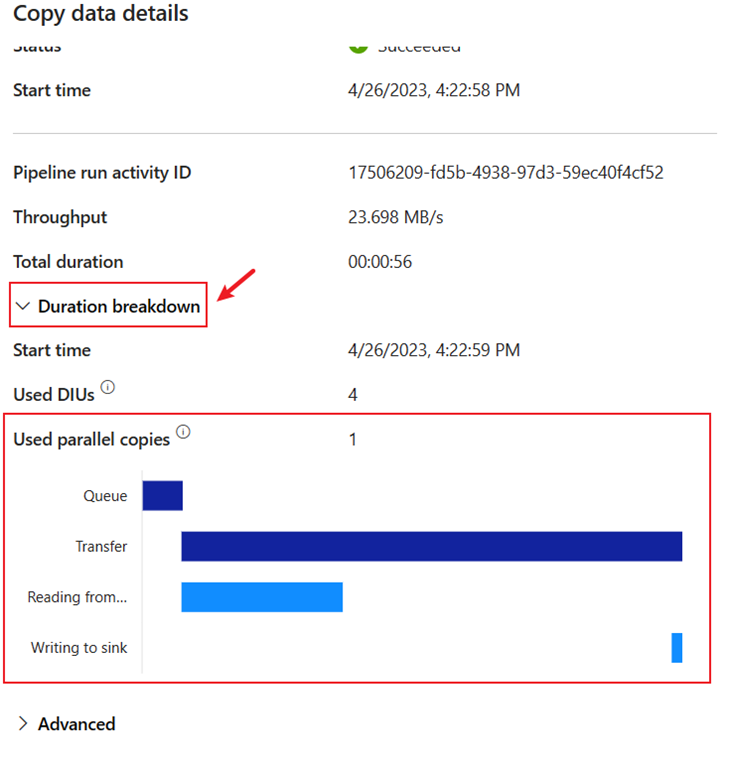
展开“持续时间明细”部分,查看复制活动的每个阶段的持续时间。 查看复制的详细信息后,选择“关闭”。
相关内容
在本端到端教程的第一个模块中,您学习了如何在 Microsoft Fabric 中使用 Data Factory 完成首次数据集成:
- 创建数据管道。
- 将复制活动添加到管道。
- 使用示例数据并创建数据 Lakehouse 以将数据存储到新表。
- 运行管道并查看其详细信息和持续时间明细。
现在,请继续到下一部分以创建您的数据流。