Microsoft Fabric 数据工厂中的带分隔符的文本格式
本文概述了如何在 Microsoft Fabric 中数据工厂的数据管道中配置带分隔符的文本格式。
支持的功能
以下活动和连接器支持使用带分隔符的文本格式作为源和目标。
复制活动中的带分隔符的文本格式
若要配置带分隔符的文本格式,请在数据管道复制活动的源或目标中选择连接,然后在“文件格式”下拉列表中选择“DelimitedText”。 选择“设置”以进一步配置此格式。
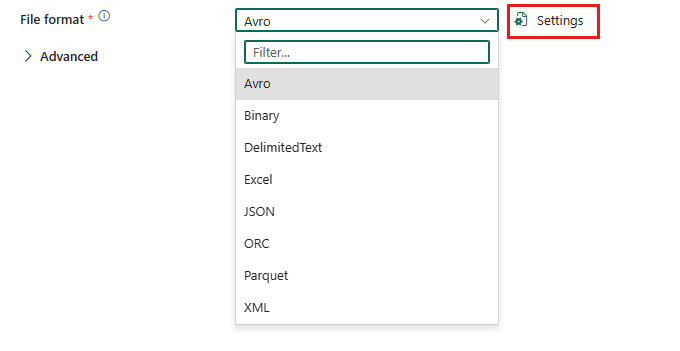
作为源的带分隔符的文本格式
在“文件格式”部分中选择“设置”后,弹出的“文件格式设置”对话框中会显示以下属性。
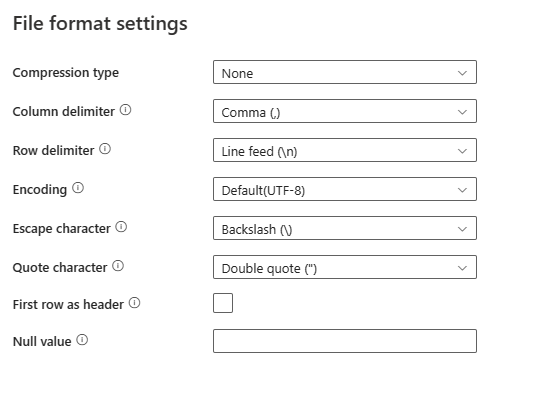
压缩类型:用于读取带分隔符的文本文件的压缩编解码器。 可以从下拉列表中选择“无”、“bzip2”、“gzip”、“deflate”、“ZipDeflate”、“TarGzip”或“tar”类型。
如果选择“ZipDeflate”作为压缩类型,则“将 zip 文件名保留为文件夹”将显示在“源”选项卡的“高级”设置”下。
- 将 zip 文件名保留为文件夹:指示是否在复制过程中以文件夹结构形式保留源 zip 文件名。
- 如果选中此框(默认),则服务会将解压缩的文件写入
<specified file path>/<folder named as source zip file>/。 - 如果未选中此框,则服务会将解压缩的文件直接写入
<specified file path>。 请确保不同的源 zip 文件中没有重复的文件名,以避免产生冲突或出现意外行为。
- 如果选中此框(默认),则服务会将解压缩的文件写入
如果选择“TarGzip/tar”作为压缩类型,则“将压缩文件名保留为文件夹”将显示在“源”选项卡的“高级”设置”下。
- 将压缩文件名保留为文件夹:指示是否在复制过程中以文件夹结构形式保留源压缩文件名。
- 如果选中此框(默认),则服务会将解压缩的文件写入
<specified file path>/<folder named as source compressed file>/。 - 如果未选中此框,则服务会将解压缩的文件直接写入
<specified file path>。 请确保不同的源 zip 文件中没有重复的文件名,以避免产生冲突或出现意外行为。
- 如果选中此框(默认),则服务会将解压缩的文件写入
- 将 zip 文件名保留为文件夹:指示是否在复制过程中以文件夹结构形式保留源 zip 文件名。
压缩级别:选择压缩类型时指定压缩比。 可以从“最佳”或“最快”中进行选择。
- 最快:尽快完成压缩操作,不过,无法以最佳方式压缩生成的文件。
- 最佳:以最佳方式完成压缩操作,不过,需要耗费更长的时间。 有关详细信息,请参阅压缩级别主题。
列分隔符:用于分隔文件中的列的字符。 默认值为逗号 (
,)。行分隔符:指定用于分隔文件中的行的字符。 只能使用一个字符。 默认值为换行符
\n。编码:用于读取/写入测试文件的编码类型。 默认值为 UTF-8。
转义字符:用于转义括住值中的引号的单个字符。 默认值为反斜杠
\。 将转义字符定义为空字符串时,“引号字符”也必须设置为空字符串。在这种情况下,应确保所有列值都不包含分隔符。引号字符:当列包含列分隔符时,用于括住列值的单个字符。 默认值为双引号
"。 将“引号字符”定义为空字符串时,它表示不使用引号字符且不用引号括住列值,而是使用转义字符来转义列分隔符及其本身。将第一行用作标头:指定是否要将第一行视为/设为包含列名称的标头行。 允许的值为已选择和未选择(默认)。 当“将第一行用作标头”处于未选择状态时,请注意,UI 数据预览和查找活动输出会自动以 Prop_{n} 格式(从 0 开始)生成列名称,复制活动需要使用从源到目标的显式映射,并按序号(从 1 开始)定位各个列。
Null 值:指定 null 值的字符串表示形式。 默认值为空字符串。
在“源”选项卡的“高级”设置下,将显示其他带分隔符文本格式的相关属性。
作为目标的带分隔符的文本格式
在“文件格式”部分中选择“设置”后,弹出的“文件格式设置”对话框中会显示以下属性。
压缩类型:用于写入带分隔符的文本文件的压缩编解码器。 可以从下拉列表中选择“无”、“bzip2”、“gzip”、“deflate”、“ZipDeflate”、“TarGzip”或“tar”类型。
压缩级别:选择压缩类型时指定压缩比。 可以从“最佳”或“最快”中进行选择。
- 最快:尽快完成压缩操作,不过,无法以最佳方式压缩生成的文件。
- 最佳:以最佳方式完成压缩操作,不过,需要耗费更长的时间。 有关详细信息,请参阅压缩级别主题。
列分隔符:用于分隔文件中的列的字符。 默认值为逗号 (
,)。行分隔符:用于分隔文件中的行的字符。 只能使用一个字符。 默认值为换行符
\n。编码:用于写入测试文件的编码类型。 默认值为 UTF-8。
转义字符:用于转义括住值中的引号的单个字符。 默认值为反斜杠
\。 将转义字符定义为空字符串时,“引号字符”也必须设置为空字符串。在这种情况下,应确保所有列值都不包含分隔符。引号字符:当列包含列分隔符时,用于括住列值的单个字符。 默认值为双引号
"。 将“引号字符”定义为空字符串时,它表示不使用引号字符且不用引号括住列值,而是使用转义字符来转义列分隔符及其本身。将第一行用作标头:指定是否要将第一行视为/设为包含列名称的标头行。 允许的值为已选择和未选择(默认)。 当“将第一行用作标头”处于未选择状态时,请注意,UI 数据预览和查找活动输出会自动以 Prop_{n} 格式(从 0 开始)生成列名称,复制活动需要使用从源到目标的显式映射,并按序号(从 1 开始)定位各个列。
Null 值:指定 null 值的字符串表示形式。 默认值为空字符串。
在“目标”选项卡的“高级”设置下,将显示带分隔符的文本格式的其他相关属性。
括住所有文本:将所有值放在引号中。
文件扩展名:用来为输出文件命名的扩展名,例如
.csv、.txt。每个文件的最大行数:在将数据写入到文件夹时,可选择写入多个文件,并指定每个文件的最大行数。
文件名前缀:配置“每个文件的最大行数”时适用。 在将数据写入多个文件时,指定文件名前缀,生成的模式为
<fileNamePrefix>_00000.<fileExtension>。 如果未指定,将自动生成文件名前缀。 如果源是基于文件的存储或已启用分区选项的数据存储,则此属性不适用。
表摘要
带分隔符的文本作为源
使用带分隔符的文本格式时,复制活动“源”部分支持以下属性。
| 名称 | 说明 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 文件格式 | 要使用的文件格式。 | DelimitedText | 是 | 类型(在 datasetSettings 下):DelimitedText |
| 压缩类型 | 用于读取带分隔符的文本文件的压缩编解码器。 | 从下列项中进行选择: 无 bzip2 gzip deflate ZipDeflate TarGzip tar |
否 | 类型(在 compression 下):bzip2 gzip deflate ZipDeflate TarGzip tar |
| 将 zip 文件名保留为文件夹 | 指示是否在复制过程中以文件夹结构形式保留源 zip 文件名。 选择“ZipDeflate”压缩时适用。 | 已选择或取消选择 | 无 | preserveZipFileNameAsFolder (在 compressionProperties->type 下为 ZipDeflateReadSettings) |
| 将压缩文件名保留为文件夹 | 指示是否在复制过程中以文件夹结构形式保留源压缩文件名。 选择“TarGzip/tar”压缩时适用。 | 已选择或取消选择 | 否 | preserveCompressionFileNameAsFolder (在 compressionProperties->type 下为 TarGZipReadSettings 或 TarReadSettings) |
| 压缩级别 | 压缩率。 允许的值为 Optimal 或 Fastest。 | 最佳或最快 | 无 | 级别(在 compression 下):最快 最佳 |
| 列分隔符 | 用于分隔文件中的列的字符。 | < 所选列分隔符 > 逗号 ,(默认) |
否 | columnDelimiter |
| 行分隔符 | 用于分隔文件中的行的字符。 | < 所选行分隔符 > \r、\n(默认)或 r\n |
无 | rowDelimiter |
| 编码 | 用于读取/写入测试文件的编码类型。 | “UTF-8”(默认)、“不带 BOM 的 UTF-8”、“UTF-16”、“UTF-16BE”、“UTF-32”、“UTF-32BE”、“US-ASCII”、“UTF-7”、“BIG5”、“EUC-JP”、“EUC-KR”、“GB2312”、“GB18030”、“JOHAB”、“SHIFT-JIS”、“CP875”、“CP866”、“IBM00858”、“IBM037”、“IBM273”、“IBM437”、“IBM500”、“IBM737”、“IBM775”、“IBM850”、“IBM852”、“IBM855”、“IBM857”、“IBM860”、“IBM861”、“IBM863”、“IBM864”、“IBM865”、“IBM869”、“IBM870”、“IBM01140”、“IBM01141”、“IBM01142”、“IBM01143”、“IBM01144”、“IBM01145”、“IBM01146”、“IBM01147”、“IBM01148”、“IBM01149”、“ISO-2022-JP”、“ISO-2022-KR”、“ISO-8859-1”、“ISO-8859-2”、“ISO-8859-3”、“ISO-8859-4”、“ISO-8859-5”、“ISO-8859-6”、“ISO-8859-7”、“ISO-8859-8”、“ISO-8859-9”、“ISO-8859-13”、“ISO-8859-15”、“WINDOWS-874”、“WINDOWS-1250”、“WINDOWS-1251”、“WINDOWS-1252”、“WINDOWS-1253”、“WINDOWS-1254”、“WINDOWS-1255”、“WINDOWS-1256”、“WINDOWS-1257”、“WINDOWS-1258” | 无 | encodingName |
| 转义字符 | 用于转义括住值中的引号的单个字符。 将转义字符定义为空字符串时,“引号字符”也必须设置为空字符串。在这种情况下,应确保所有列值都不包含分隔符。 | < 所选转义字符 > 反斜杠 \(默认) |
否 | escapeChar |
| 引号字符 | 当列包含列分隔符时,用于括住列值的单个字符。 将“引号字符”定义为空字符串时,它表示不使用引号字符且不用引号括住列值,而是使用转义字符来转义列分隔符及其本身。 | < 所选引号字符 > 双引号 "(默认) |
否 | quoteChar |
| 将第一行用作标头 | 指定是否要将给定工作表/范围内的第一行视为带有列名的标题行。 | 已选择或未选择 | 否 | firstRowAsHeader: true 或 false(默认) |
| Null 值 | 指定 null 值的字符串表示形式。 默认值为空字符串。 | < null 值的字符串表示形式 > 空字符串(默认) |
否 | nullValue |
带分隔符的文本作为目标
使用带分隔符的文本格式时,复制活动“目标”部分支持以下属性。
| 名称 | 说明 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 文件格式 | 要使用的文件格式。 | DelimitedText | 是 | 类型(在 datasetSettings 下):DelimitedText |
| 压缩类型 | 用于写入带分隔符的文本文件的压缩编解码器。 | 从下列项中进行选择: 无 bzip2 gzip deflate ZipDeflate TarGzip tar |
否 | 类型(在 compression 下):bzip2 gzip deflate ZipDeflate TarGzip tar |
| 将 zip 文件名保留为文件夹 | 指示是否在复制过程中以文件夹结构形式保留源 zip 文件名。 | 已选择或取消选择 | 无 | preserveZipFileNameAsFolder (在 compressionProperties->type 下为 ZipDeflateReadSettings) |
| 将压缩文件名保留为文件夹 | 指示是否在复制过程中以文件夹结构形式保留源压缩文件名。 | 已选择或取消选择 | 否 | preserveCompressionFileNameAsFolder (在 compressionProperties->type 下为 TarGZipReadSettings 或 TarReadSettings) |
| 压缩级别 | 压缩率。 允许的值为 Optimal 或 Fastest。 | 最佳或最快 | 无 | 级别(在 compression 下):最快 最佳 |
| 列分隔符 | 用于分隔文件中的列的字符。 | < 所选列分隔符 > 逗号 ,(默认) |
否 | columnDelimiter |
| 行分隔符 | 用于分隔文件中的行的字符。 | < 所选行分隔符 > \r、\n(默认)或 r\n |
无 | rowDelimiter |
| 编码 | 用于读取/写入测试文件的编码类型。 | “UTF-8”(默认)、“不带 BOM 的 UTF-8”、“UTF-16”、“UTF-16BE”、“UTF-32”、“UTF-32BE”、“US-ASCII”、“UTF-7”、“BIG5”、“EUC-JP”、“EUC-KR”、“GB2312”、“GB18030”、“JOHAB”、“SHIFT-JIS”、“CP875”、“CP866”、“IBM00858”、“IBM037”、“IBM273”、“IBM437”、“IBM500”、“IBM737”、“IBM775”、“IBM850”、“IBM852”、“IBM855”、“IBM857”、“IBM860”、“IBM861”、“IBM863”、“IBM864”、“IBM865”、“IBM869”、“IBM870”、“IBM01140”、“IBM01141”、“IBM01142”、“IBM01143”、“IBM01144”、“IBM01145”、“IBM01146”、“IBM01147”、“IBM01148”、“IBM01149”、“ISO-2022-JP”、“ISO-2022-KR”、“ISO-8859-1”、“ISO-8859-2”、“ISO-8859-3”、“ISO-8859-4”、“ISO-8859-5”、“ISO-8859-6”、“ISO-8859-7”、“ISO-8859-8”、“ISO-8859-9”、“ISO-8859-13”、“ISO-8859-15”、“WINDOWS-874”、“WINDOWS-1250”、“WINDOWS-1251”、“WINDOWS-1252”、“WINDOWS-1253”、“WINDOWS-1254”、“WINDOWS-1255”、“WINDOWS-1256”、“WINDOWS-1257”、“WINDOWS-1258” | 无 | encodingName |
| 转义字符 | 用于转义括住值中的引号的单个字符。 将转义字符定义为空字符串时,“引号字符”也必须设置为空字符串。在这种情况下,应确保所有列值都不包含分隔符。 | < 所选转义字符 > 反斜杠 \(默认) |
否 | escapeChar |
| 引号字符 | 当列包含列分隔符时,用于括住列值的单个字符。 将“引号字符”定义为空字符串时,它表示不使用引号字符且不用引号括住列值,而是使用转义字符来转义列分隔符及其本身。 | < 所选引号字符 > 双引号 "(默认) |
否 | quoteChar |
| 将第一行用作标头 | 指定是否要将给定工作表/范围内的第一行视为带有列名的标题行。 | 已选择或未选择 | 否 | firstRowAsHeader: true 或 false(默认) |
| 括住所有文本 | 将所有值放在引号中。 | 已选择(默认)或未选择 | 否 | quoteAllText: true(默认)或 false |
| 文件扩展名 | 用来为输出文件命名的文件扩展名。 | < 文件扩展名 > .txt(默认情况) |
否 | fileExtension |
| 每个文件的最大行数 | 在将数据写入到文件夹时,可选择写入多个文件,并指定每个文件的最大行数。 | < 每个文件的最大行数 > | 否 | maxRowsPerFile |
| 文件名前缀 | 配置“每个文件的最大行数”时适用。 在将数据写入多个文件时,指定文件名前缀,生成的模式为 <fileNamePrefix>_00000.<fileExtension>。 如果未指定,将自动生成文件名前缀。 如果源是基于文件的存储或已启用分区选项的数据存储,则此属性不适用。 |
< 文件名前缀 > | 否 | fileNamePrefix |