在复制活动中配置 Azure 表存储
本文概述了如何使用数据管道中的复制活动从/向 Azure 表存储复制数据。
支持的配置
有关复制活动下每个选项卡的配置,请分别转到以下各部分。
常规
若要配置“常规”设置选项卡,请参阅“常规”设置指导。
源
转到“源”选项卡以配置复制活动源。 有关详细配置,请参阅以下内容。
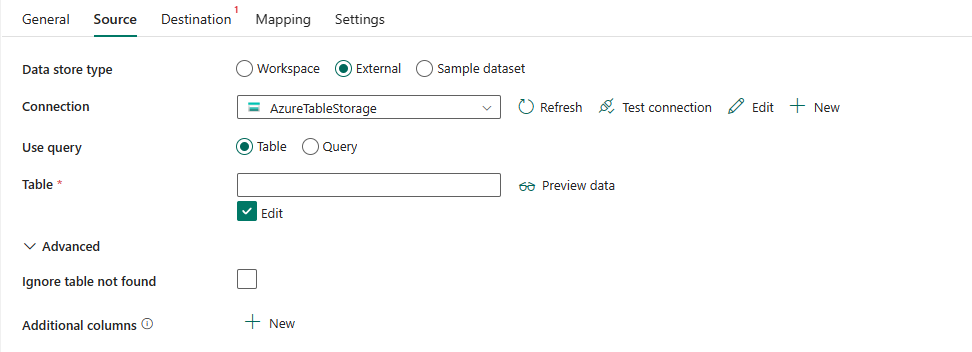
需要以下三个属性:
数据存储类型:选择“外部”。
连接:从连接列表中选择 Azure 表存储连接。 如果不存在连接,则选择“新建”来创建新的 Azure 表存储连接。
使用查询:指定用于读取数据的方式。 选择“表”以从指定表中读取数据,或选择“查询”以使用查询读取数据。
如果选择“表”:

- 表:在 Azure 表存储数据库实例中指定表的名称。 从下拉列表中选择表,或通过选择“编辑”手动输入名称。
如果选择“查询”:
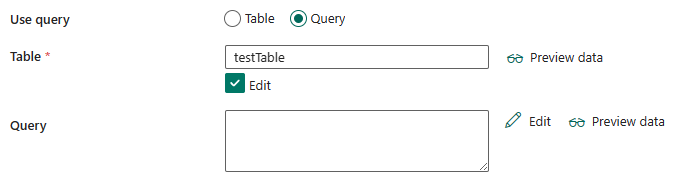
表:在 Azure 表存储数据库实例中指定表的名称。 从下拉列表中选择表,或通过选择“编辑”手动输入名称。
查询:指定自定义表存储查询读取数据。 源查询是 Azure 表存储支持的
$filter查询选项的直接映射,可从本文中详细了解语法。注意
Azure 表服务会强制 Azure 表查询操作在 30 秒后超时。 通过针对查询的设计一文了解如何优化查询。
在“高级”下,可以指定以下字段:
忽略找不到的表:指示是否允许存在忽略表异常。 默认情况下,它处于未选中状态。
其他列:添加其他数据列以存储源文件的相对路径或静态值。 后者支持表达式。
目标
转到“目标”选项卡以配置复制活动目标。 有关详细配置,请参阅以下内容。
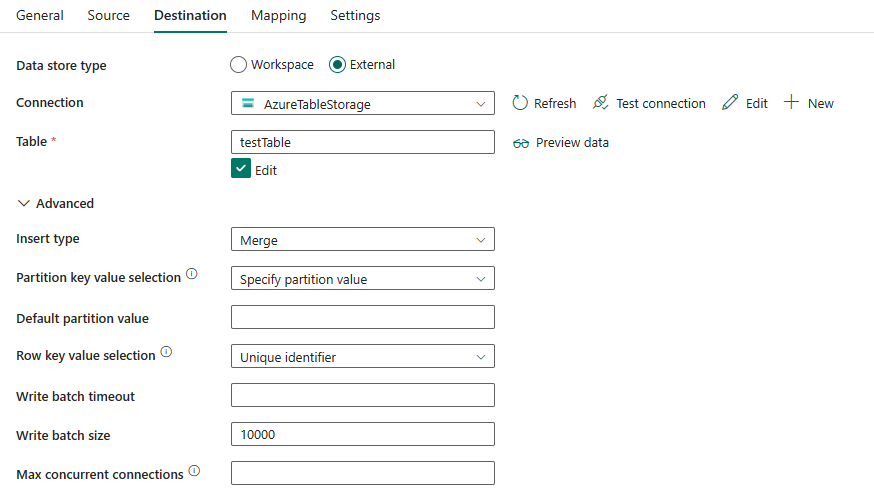
需要以下三个属性:
- 数据存储类型:选择“外部”。
- 连接:从连接列表中选择 Azure 表存储连接。 如果不存在连接,则选择“新建”来创建新的 Azure 表存储连接。
- 表:在 Azure 表存储数据库实例中指定表的名称。 从下拉列表中选择表,或通过选择“编辑”手动输入名称。
在“高级”下,可以指定以下字段:
插入类型:选择要将数据插入 Azure 表的模式。 模式为“合并”和“替换”。 此属性控制输出表中具有匹配的分区键和行键的现有行是否替换或合并其值。 此设置在行级别而不是表级别进行应用。 并且两个选项都不会删除输入中不存在的输出表中的行。 若要了解合并和替换设置的工作原理,请参阅插入或合并实体和插入或替换实体。
分区键值选择:选择“指定分区值”或“使用目标列”。 分区键值可以是固定值,也可以从目标列中获取值。
如果选择“指定分区值”:
- 默认分区值:目标可以使用的默认分区键值。
如果选择“使用目标列”:
- 分区键列:选择要将其列值用作分区键的列的名称。 如果未指定,则使用“AzureTableDefaultPartitionKeyValue”作为分区键。
行键值选择:选择“唯一标识符”或“使用目标列”。 行键值可以是自动生成的唯一标识符,也可以从目标列中获取值。
如果选择“使用目标列”:
- 行键列:选择列名称,使用列值作为行键。 如果未指定,对每一行使用 GUID。
批量写入大小:命中指定的批量写入大小时,将数据插入 Azure 表。 允许的值为 integer(行数)。 默认值为 10,000。
批量写入超时:命中指定的批量写入超时时,将数据插入 Azure 表。 允许的值为 timespan。
最大并发连接:活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接的数量时,才指定具体值
映射
对于“映射”选项卡配置,请参阅“映射”选项卡下的“配置映射”。
设置
对于“设置”选项卡配置,请转到“设置”选项卡下的“配置其他设置”。
表摘要
下表包含有关 Azure 表存储中复制活动的详细信息。
源信息
| 名称 | 描述 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 数据存储类型 | 你的数据存储类型。 | 外部 | 是 | / |
| Connection | 与源数据存储的连接。 | < Azure 表存储连接> | 是 | 连接 |
| 使用查询 | 读取数据的方式。 应用“表”以从指定表中读取数据,或应用“查询”以使用查询读取数据。 | • 表 • 查询 |
是 | / |
| 表 | Azure 表存储数据库实例中表的名称。 | < 表名称 > | 是 | tableName |
| 查询 | 指定自定义表存储查询读取数据。 源查询是 Azure 表存储支持的 $filter 查询选项的直接映射,可从本文中详细了解语法。 |
< 你的查询 > | 否 | azureTableSourceQuery |
| 忽略找不到的表 | 指示是否允许存在忽略表异常。 | 选中或未选中(默认) | 否 | azureTableSourceIgnoreTableNotFound: true 或 false(默认) |
| 其他列 | 添加其他数据列以存储源文件的相对路径或静态值。 后者支持表达式。 | • 姓名 • 值 |
否 | additionalColumns: • 名称 • 值 |
目标信息
| 名称 | 描述 | 值 | 必选 | JSON 脚本属性 |
|---|---|---|---|---|
| 数据存储类型 | 你的数据存储类型。 | 外部 | 是 | / |
| Connection | 与目标数据存储的连接。 | < Azure 表存储连接> | 是 | 连接 |
| 表 | Azure 表存储数据库实例中表的名称。 | < 表名称 > | 是 | tableName |
| 插入类型 | 将数据插入 Azure 表的模式。 此属性控制输出表中具有匹配的分区键和行键的现有行是否替换或合并其值。 | • 合并 • 替换 |
否 | azureTableInsertType: • merge • replace |
| 分区键值选择 | 分区键值可以是固定值,也可以从目标列中获取值。 | • 指定分区值 • 使用目标列 |
否 | / |
| 默认分区值 | 目标可以使用的默认分区键值 | < 默认分区值 > | 否 | azureTableDefaultPartitionKeyValue |
| 分区键列 | 列的名称,使用该列的值作为分区键。 如果未指定,则使用“AzureTableDefaultPartitionKeyValue”作为分区键。 | < 分区键列 > | 否 | azureTablePartitionKeyName |
| 行键值选择 | 行键值可以是自动生成的唯一标识符,也可以从目标列中获取值。 | • 唯一标识符 • 使用目标列 |
否 | / |
| 行键列 | 列名称,使用该列的值作为行键。 如果未指定,对每一行使用 GUID。 | < 行键列 > | 否 | azureTableRowKeyName |
| 写入批大小 | 命中批量写入大小时将数据插入 Azure 表。 | 整数 (默认值为 10,000) |
否 | writeBatchSize |
| 写入批处理超时 | 命中批量写入超时时,将数据插入 Azure 表 | timespan | 否 | writeBatchTimeout |
| 最大并发连接数 | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | < 最大并发连接数 > | 否 | maxConcurrentConnections |