在复制活动中配置 Azure Database for PostgreSQL
本文概述了如何使用数据管道中的复制活动从/向 Azure Database for PostgreSQL 复制数据。
支持的配置
有关复制活动下每个选项卡的配置,请分别转到以下部分。
常规
请参阅 常规 设置 指南,以配置 常规 设置选项卡。
源
转到“源”选项卡以配置复制活动源。 有关详细配置,请参阅以下内容。
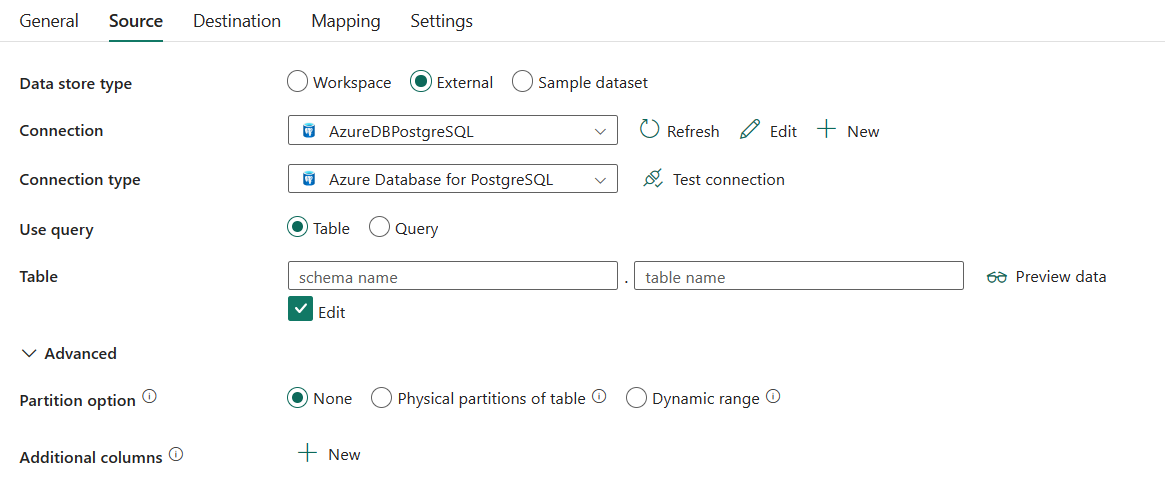
需要以下三个属性:
- 连接:从连接列表中选择 Azure Database for PostgreSQL 连接。 如果不存在连接,请创建新的 Azure Database for PostgreSQL 连接。
- 连接类型:选择“Azure Database for PostgreSQL”。
- 使用查询:选择 表 从指定表读取数据,或选择 查询 使用查询读取数据。
如果选择“表”:
表:从下拉列表中选择该表,或选择 手动输入 以读取数据。

如果选择“查询”:
查询:指定要读取数据的自定义 SQL 查询。 例如:
SELECT * FROM mytable或SELECT * FROM "MyTable"。注意
在 PostgreSQL 中,如果实体名称未加引号,则视为不区分大小写。
显示“使用查询 - 查询”的

在“高级”下,可以指定以下字段:
查询超时(分钟):指定在终止尝试执行命令并生成错误之前等待时间,默认值为 120 分钟。 如果为此属性设置了参数,则允许的值是时间跨度,例如“02:00:00”(120 分钟)。 有关详细信息,请参阅 CommandTimeout。
分区选项:指定用于从 Azure Database for PostgreSQL 加载数据的数据分区选项。 启用分区选项(即,不是“无”)时,从 Azure Database for PostgreSQL 并发加载数据的并行度由“复制活动设置”选项卡中的“复制并行度”控制。
如果选择无,则表示不使用分区。
如果选择“表的物理分区”:
分区名称:指定需要复制的物理分区的列表。
如果使用查询来检索源数据,请在 WHERE 子句中添加
?AdfTabularPartitionName。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。
如果选择“动态范围”:
分区列名称:以整数类型、日期类型或日期/时间类型(
int、smallint、bigint、date、timestamp without time zone、timestamp with time zone或time without time zone)指定源列的名称,范围分区将使用它进行并行复制。 如果未指定,系统会自动检测表的主键并将其用作分区列。如果使用查询来检索源数据,请在 WHERE 子句中绑定
?AdfRangePartitionColumnName。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。分区上限:指定要从中复制数据的分区列的最大值。
如果使用查询来检索源数据,请在 WHERE 子句中插入
?AdfRangePartitionUpbound。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。 .分区下限:指定要复制数据的分区列的最小值。
如果使用查询来检索源数据,请在 WHERE 子句中加入
?AdfRangePartitionLowbound。 有关示例,请参阅从 Azure Database for PostgreSQL 进行并行复制一节。
其他列:添加其他数据列以存储源文件的相对路径或静态值。 后者支持表达式。
目的地
转到“目标”选项卡,配置复制活动目标。 有关详细配置,请参阅以下内容。
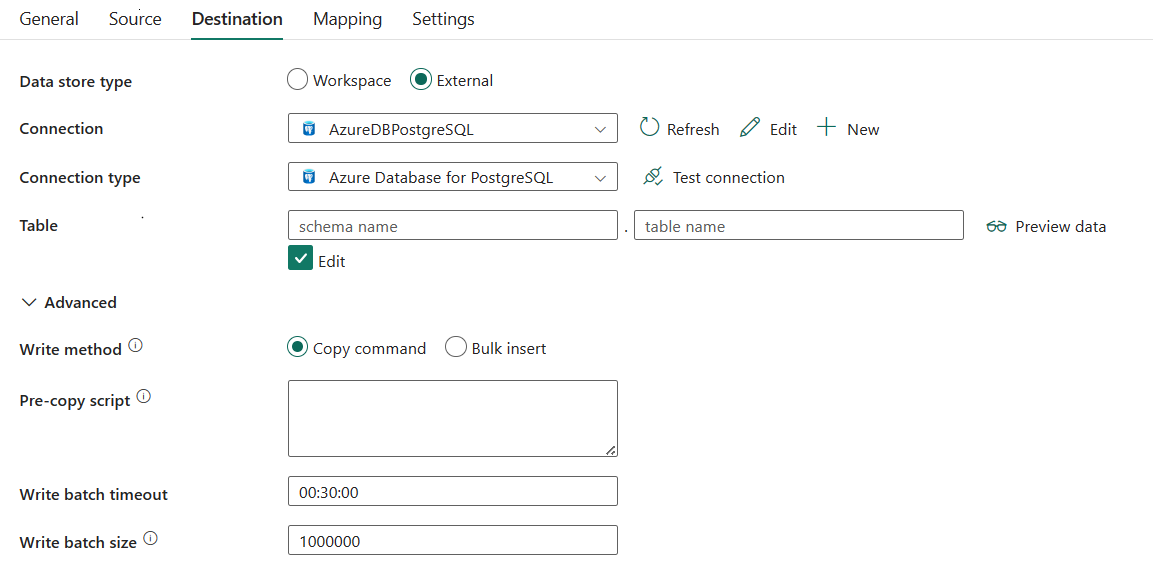
需要以下三个属性:
- 连接:从连接列表中选择 Azure Database for PostgreSQL 连接。 如果不存在连接,请创建新的 Azure Database for PostgreSQL 连接。
- 连接类型:选择“Azure Database for PostgreSQL”。
- 表:从下拉列表中选择表或选择“手动输入”以输入表来写入数据。
在“高级”下,可以指定以下字段:
写入方法:选择用于将数据写入 Azure Database for PostgreSQL 的方法。 选择“复制命令”(默认,性能更好)或“大容量插入”。
预复制脚本:在每次运行中将数据写入 Azure Database for PostgreSQL 之前,请为复制活动指定要执行的 SQL 查询。 可以使用此属性来清理预加载的数据。
写入批超时:指定超时前等待批插入操作完成的时间。允许的值为 timespan。 默认值为 00:30:00 (30 分钟)。
写入批大小:指定每批加载到 Azure Database for PostgreSQL 中的行数。 允许的值是表示行数的整数。 默认值为 1,000,000。
映射
对于“映射”选项卡配置,请参阅在“映射”选项卡下配置映射。
设置
对于“设置”选项卡配置,请转到在“设置”选项卡下配置其他设置。
从 Azure Database for PostgreSQL 进行并行复制
复制活动中的 Azure Database for PostgreSQL 连接器提供内置的数据分区,用于并行复制数据。 可以在复制活动的 源 选项卡上找到数据分区选项。
启用分区复制时,复制活动针对 Azure Database for PostgreSQL 源运行并行查询,以便按分区加载数据。 并行度由复制活动设置选项卡中的 复制并行度 控制。例如,如果将 复制并行度 设置为 4,则服务会根据指定的分区选项和设置同时生成并运行四个查询,并且每个查询从 Azure Database for PostgreSQL 检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 Azure Database for PostgreSQL 加载大量数据时。 下面是针对不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议以多个文件的形式写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 场景 | 建议的设置 |
|---|---|
| 从包含物理分区的大型表进行完整加载。 | 分区选项:表的物理分区。 在执行期间,服务会自动检测物理分区,并按分区复制数据。 |
| 对没有物理分区的大型表进行完全加载,同时使用整数列进行数据分区。 | 分区选项:动态范围。 分区列:指定用于对数据进行分区的列。 如果没有特别指定,则默认使用主键列。 |
| 使用具有物理分区的自定义查询加载大量数据。 | 分区选项:表的物理分区。 查询: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>。分区名称:指定要从中复制数据的分区名称。 如果未指定,该服务会自动检测在 PostgreSQL 数据集中指定的表的物理分区。 在执行期间,服务会将 ?AdfTabularPartitionName 替换为实际的分区名称,并发送到 Azure Database for PostgreSQL。 |
| 使用自定义查询(不含物理分区)加载大量数据,同时使用整数列进行数据分区。 | 分区选项:动态范围。 查询: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 可以针对具有整数或日期/日期时间数据类型的列进行分区。 分区上限 和 分区下限:指定是否要根据分区列进行筛选,以便仅检索下限和上限之间的数据。 在执行期间,服务会将 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound和 ?AdfRangePartitionLowbound 替换为每个分区的实际列名和值范围,并发送到 Azure Database for PostgreSQL。 例如,如果将分区列“ID”设置为 1,上限设置为 80,并行复制设置为 4,则服务按 4 个分区检索数据。 它们的 ID 分别介于 [1,20]、[21、40]、[41、60] 和 [61, 80]之间。 |
使用分区选项加载数据的最佳做法:
- 选择独特的列作为分区列(如主键或唯一键)以避免数据倾斜。
- 如果表具有内置分区,请使用分区选项“表的物理分区”以获得更好的性能。
表摘要
下表包含有关 Azure Database for PostgreSQL 中的复制活动的详细信息。
源信息
| 名字 | 描述 | 值 | 必需 | JSON 脚本属性 |
|---|---|---|---|---|
| 连接 | 与源数据存储的连接。 | < your Azure Database for PostgreSQL connection > | 是的 | 连接 |
| 连接类型 | 你的源连接类型。 | Azure Database for PostgreSQL | 是的 | / |
| 使用查询 | 读取数据的方式。 应用“表”以从指定表中读取数据,或应用“查询”以使用查询读取数据。 | • 表 • 查询 |
是的 | • typeProperties(在 typeProperties ->source 下)- 架构 - 表 • 查询 |
| 查询超时(分钟) | 终止尝试执行命令并生成错误之前的等待时间,默认值为 120 分钟。 如果为此属性设置了参数,则允许的值是时间跨度,例如“02:00:00”(120 分钟)。 有关详细信息,请参阅 CommandTimeout。 | 时间跨度 | 不 | queryTimeout |
| 分区名称 | 需要复制的物理分区的列表。 如果使用查询来检索源数据,请在 WHERE 子句中插入 ?AdfTabularPartitionName。 |
< your partition names > | 不 | partitionNames |
| 分区列名称 | 整数类型、日期类型或日期/时间类型(int、smallint、bigint、date、timestamp without time zone、timestamp with time zone 或 time without time zone)源列的名称,范围分区将使用它进行并行复制。 如果未指定,系统会自动检测表的主键并将其用作分区列。 |
< your partition column names > | 不 | partitionColumnName |
| 分区上限 | 要从中复制数据的分区列的最大值。如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionUpbound。 |
< your partition upper bound > | 不 | partitionUpperBound |
| 分区下限 | 要从中复制数据的分区列的最小值。如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionLowbound。 |
< your partition lower bound > | 不 | partitionLowerBound |
| 其他列 | 添加其他数据列以存储源文件的相对路径或静态值。 后者支持表达式。 | •名字 •价值 |
不 | additionalColumns: •名字 •价值 |
目的地信息
| 名字 | 描述 | 值 | 必需 | JSON 脚本属性 |
|---|---|---|---|---|
| 连接 | 与目标数据存储的连接。 | < your Azure Database for PostgreSQL connection > | 是的 | 连接 |
| 连接类型 | 您的目的地连接类型。 | Azure Database for PostgreSQL | 是的 | / |
| 表 | 要写入数据的目标数据表。 | <目标表的名称> | 是的 | typeProperties(在 typeProperties ->sink 下):- 架构 - 表 |
| Write 方法 | 用于将数据写入 Azure Database for PostgreSQL 的方法。 | • 复制命令(默认值) • Bulk insert |
不 | writeMethod: • CopyCommand • BulkInsert |
| 预复制脚本 | 每次运行时将数据写入 Azure Database for PostgreSQL 之前,要执行的复制活动的 SQL 查询。 可以使用此属性来清理预加载的数据。 | < your pre-copy script > | 不 | preCopyScript |
| 写入批处理超时 | 超时前等待批插入操作完成的时间。 | 时间跨度 (默认值为 00:30:00 - 30 分钟) |
不 | writeBatchTimeout |
| 写入批大小 | 每批加载到 Azure Database for PostgreSQL 中的行数。 | 整数 (默认值为 1,000,000) |
不 | writeBatchSize |