使用笔记本将数据加载到湖屋中
在本教程中,你将了解如何使用笔记本读/写 Fabric 湖屋中的数据。 Fabric 支持 Spark API 和 Pandas API,以为实现此目标。
使用 Apache Spark API 加载数据
在笔记本的代码单元格中,使用以下代码示例从源读取数据,并将其加载到湖屋的文件、表或这两个部分中。
若要指定要从中读取的位置,可以使用相对路径(如果数据来自当前笔记本的默认湖屋)。 或者,如果数据来自其他湖屋,则可以使用绝对 Azure Blob File System (ABFS) 路径。 可以从数据的关联菜单中复制此路径。
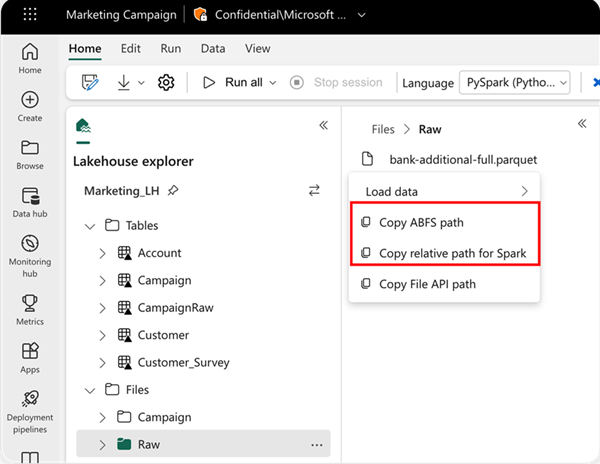
复制 ABFS 路径:此选项将返回文件的绝对路径。
复制 Spark 的相对路径:此选项将返回默认湖屋中文件的相对路径。
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
使用 Pandas API 加载数据
为了支持 Pandas API,默认湖屋会自动装载到笔记本。 装入点为“/lakehouse/default/”。 可以使用此装入点从/向默认湖屋读取/写入数据。 关联菜单中的“复制文件 API 路径”选项会从该装入点返回文件 API 路径。 从“复制 ABFS 路径”选项返回的路径也适用于 Pandas API。
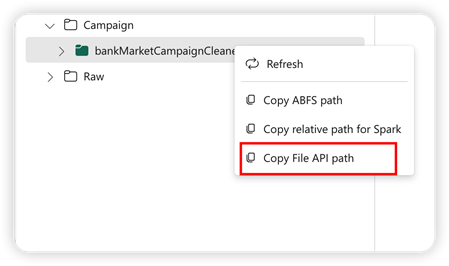
复制文件 API 路径:此选项将返回默认湖屋的装入点下的路径。
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
提示
对于 Spark API,请使用“复制 ABFS 路径”或“复制 Spark 的相对路径”选项来获取文件的路径。 对于 Pandas API,请使用“复制 ABFS 路径”或“复制文件 API 路径”选项来获取文件的路径。
让代码使用 Spark API 或 Pandas API 的最快方法是使用“加载数据”选项并选择要使用的 API。 该代码会在笔记本的新代码单元格中自动生成。
