Fabric 环境中的 Spark 计算配置设置
Microsoft Fabric 数据工程和数据科学体验基于完全托管的 Spark 计算平台运行。 该平台经过设计,可提供无与伦比的速度和效率。 它包括启动池和自定义池。
Fabric 环境包含一组配置,包括多项 Spark 计算属性,用户可通过这些属性在向笔记本和 Spark 作业附加 Spark 会话后配置 Spark 会话。 借助环境,你可以灵活自定义用于运行 Spark 作业的计算配置。 在环境中,计算部分允许用户配置 Spark 会话级别属性,以根据工作负荷要求自定义执行程序的内存大小和核心数量。
工作区管理员可以启用或禁用计算自定义,方法是使用“工作区设置”屏幕的“数据工程/科学”部分中“池”选项卡中的“自定义项目的计算配置”开关。
工作区管理员可以通过启用此设置来委托成员和参与者来更改 Fabric 环境中的默认会话级别计算配置。
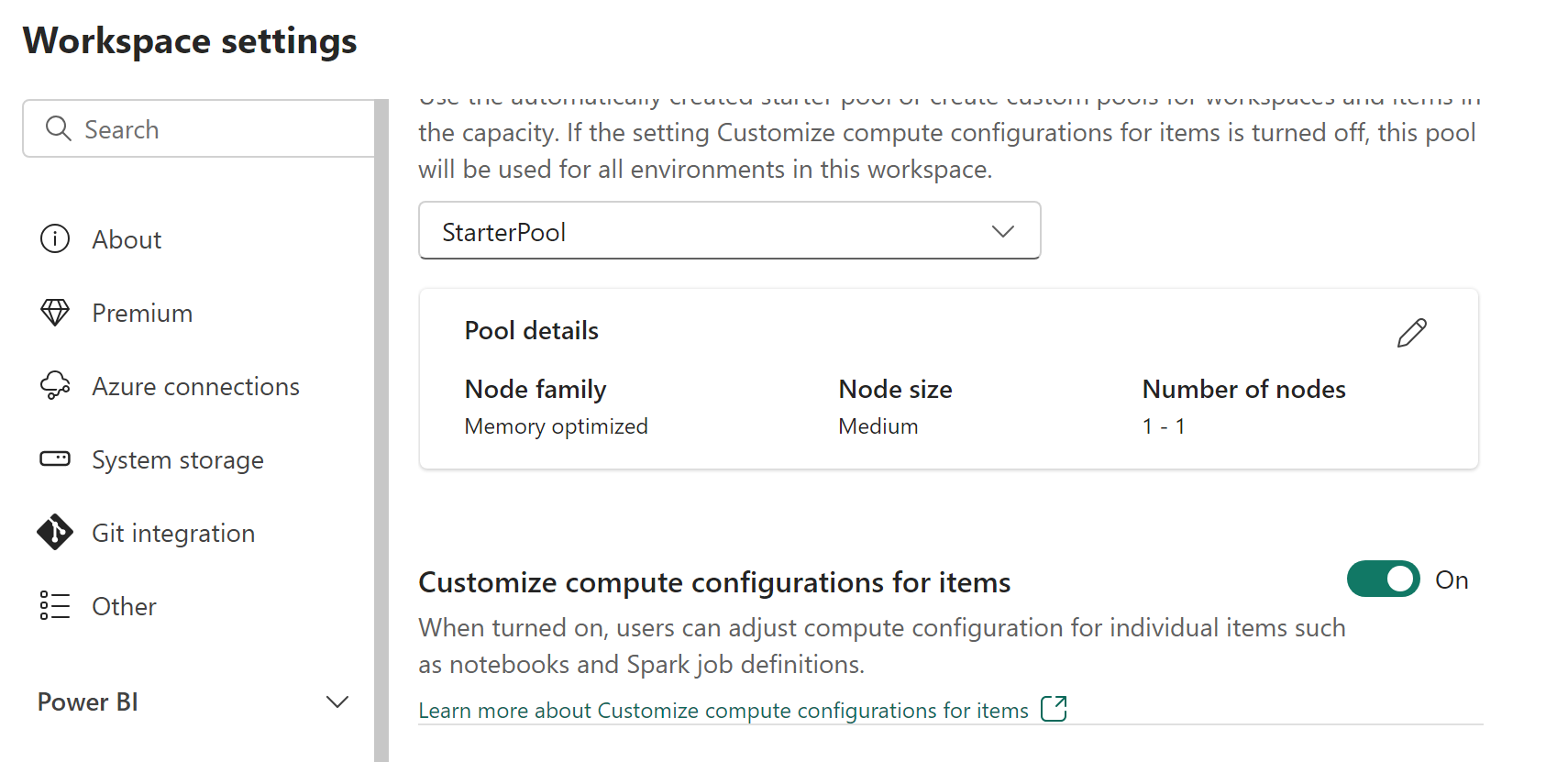
如果工作区管理员在工作区设置中禁用了此选项,则会禁用环境的计算部分,并且工作区的默认池计算配置用于运行 Spark 作业。
自定义环境中的会话级别计算属性
用户可以从 Fabric 工作区中提供的池列表中选择环境的池。 Fabric 工作区管理员创建默认启动池和自定义池。
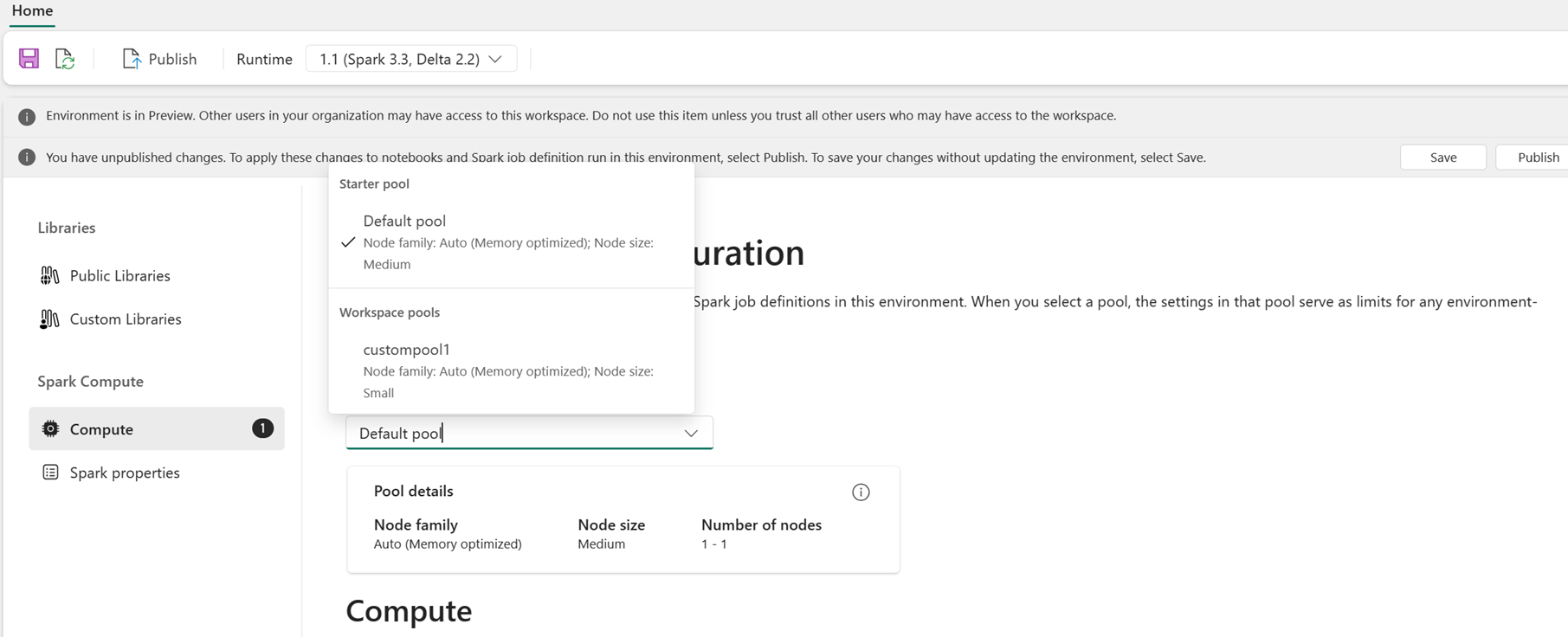
在“计算”部分选择池后,可以在所选池的节点大小和限制范围内优化执行程序的核心数和内存大小。
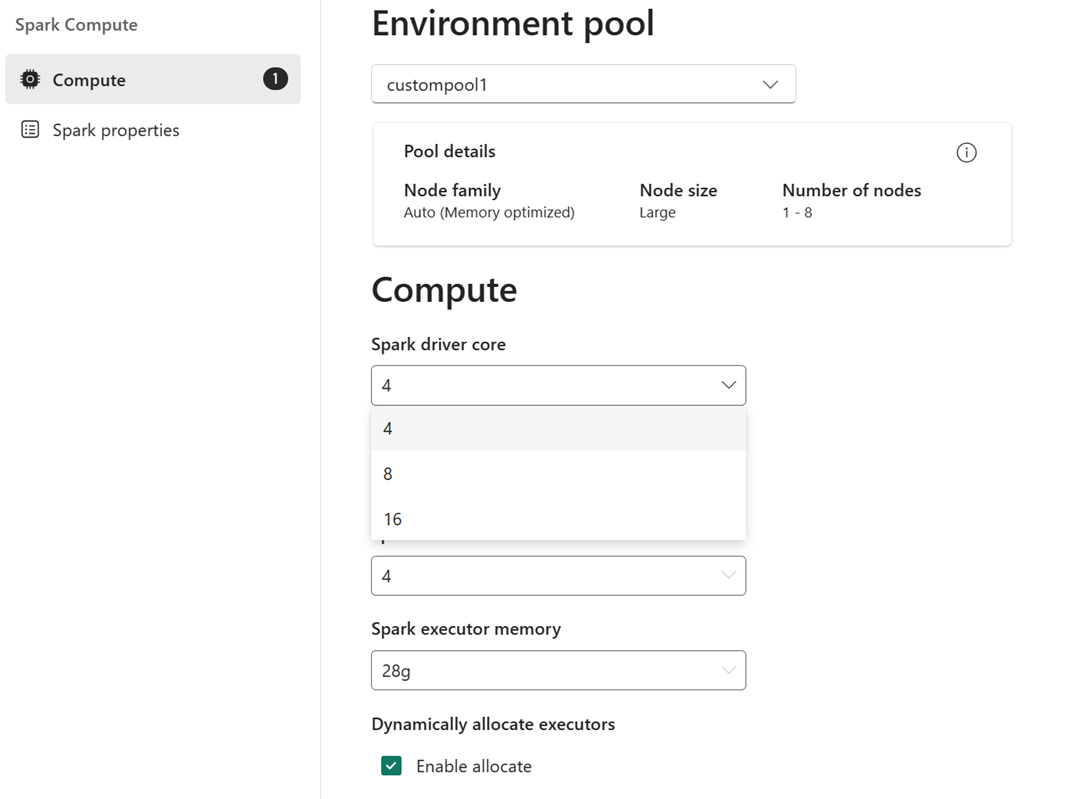
例如:选择节点大小较大(即 16 个 Spark Vcore)的自定义池作为环境池。 然后,可以根据作业级别要求将驱动程序/执行程序核心选为 4、8 或 16。 对于分配给驱动程序和执行程序的内存,可以选择 28 g、56 g 或 112 g,它们全都在大型节点内存限制的范围内。
有关 Spark 计算大小及其核心或内存选项的详细信息,请参阅什么是 Microsoft Fabric 中的 Spark 计算?。