删除每个表中的重复项以实现数据统一
重复数据删除从源表中查找并删除客户的重复记录,以使每个客户在每个表中都由一行表示。 每个表使用规则分别进行重复删除,以识别给定客户的记录。
每个重复数据删除规则针对每一行运行。 如果第一个规则与第 1 行和第 2 行匹配,规则 2 与第 2 行和第 3 行匹配,则第 1、2 和 3 行将匹配。 找到匹配的行后,将根据合并首选项(最完整、最新或最早)选择获胜者行来表示该客户。 使用高级选项,通过从各个匹配的行中选择字段(如最新的电子邮件,但最完整的地址)来创建获胜者行。
Customer Insights - Data 将自动执行以下操作:
- 删除具有相同主键值的重复记录,选择数据集中的第一行作为获胜者。
- 在表之间匹配行时,使用为表定义的匹配规则删除重复记录。
定义删除重复规则
好的规则可识别唯一客户。 考虑您的数据。 根据电子邮件等字段识别客户可能就足够了。 但是,如果您想要区分共用电子邮件的客户,可以选择有两个条件的规则,对 Email + FirstName 进行匹配。 有关详细信息,请参阅删除重复项最佳做法。
在删除重复项规则页上,选择表并选择添加规则来定义删除重复规则。
小费
如果您在数据源级别扩充了表以帮助改进统一结果,选择页面顶部的使用扩充表。 有关详细信息,请参阅数据源扩充。
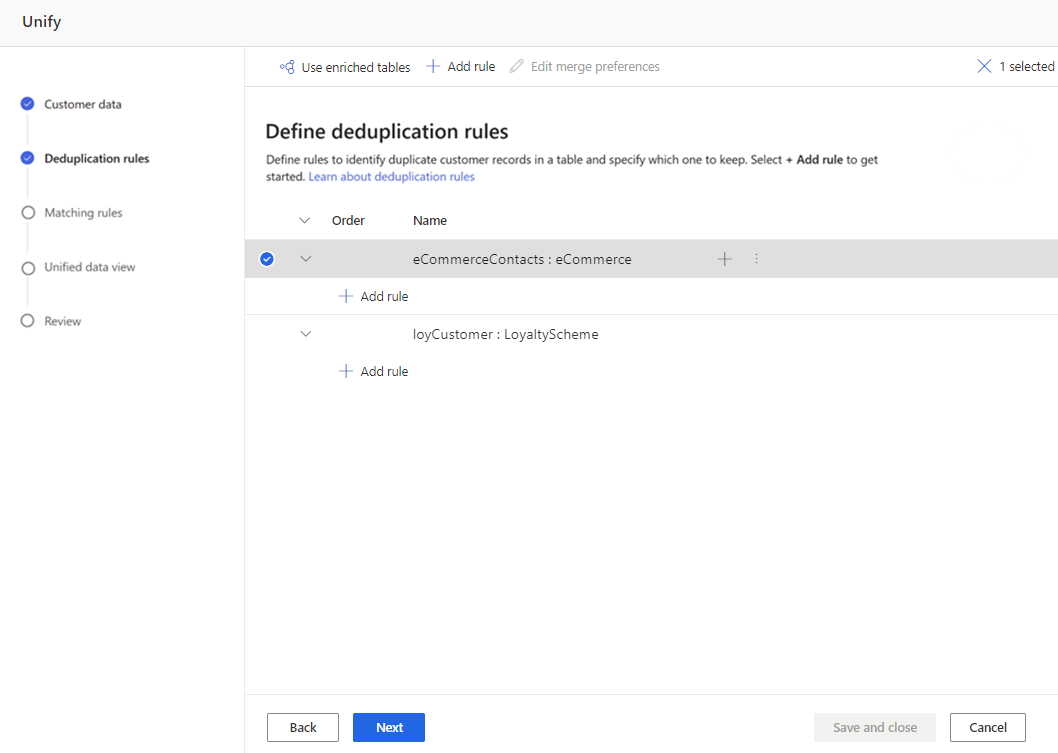
在添加规则窗格中,输入以下信息:
选择字段:从要检查重复项的表的可用字段列表中进行选择。 选择可能为每个客户所特有的字段。 例如,电子邮件地址,或者名称、市/县和电话号码的组合。
标准化:为列选择标准化选项。 标准化只影响匹配步骤,不会更改数据。
标准化 示例 数字 将多个表示数字的 Unicode 符号转换为简单数字。
示例:❽ 和 Ⅷ 均会被标准化为数字 8。
注意:符号必须以 Unicode 点格式编码。代码 删除符号和特殊字符。
示例:!?"#$%&'( )+,.-/:;<=>@^~{}`[ ]文本转小写 将大写字符转换为小写字符。
示例:“THIS Is aN EXamplE”转换为“this is an example”类型 – 电话 将各种格式的电话转换为数字,考虑国家/地区代码和分机号显示方式的变化。 符号和空格将被忽略。 国家/地区代码中的前导“0”数字将被忽略,与 +1 和 +01 匹配。 由字母前缀表示的扩展将被忽略(X 123)。 规范化的国家/地区代码 非常重要 ,因此带有国家/地区代码的手机与没有国家/地区代码的手机不匹配。
示例:+01 425.555.1212 匹配 1 (425) 555-1212
+01 425.555.1212 不匹配 (425) 555-1212类型 - 名称 转换 500 多种常见名称变体和标题。
示例:“debby”->“deborah”“prof”和“professor”->“Prof.”类型 - 地址 转换地址的通用部分
示例:“street”->“st”和“northwest”->“nw”类型 - 组织 删除大约 50 个公司名称“干扰词”,如“co”、“corp”、“corporation”和“ltd”。 Unicode 转 ASCII 将 Unicode 字符转换为同等 ASCII 字母
示例:字符“à”、“á”、“â”、“À”、“Á”、“”、“Ô、“Ä”、“Ⓐ”和“A”全部转换为“a”。空白 删除所有空格 别名映射 允许您上载字符串对的自定义列表,然后可以使用该列表来指示应始终被视为完全匹配的字符串。
当您有您认为应该匹配的特定数据示例,但使用其他标准化模式之一无法匹配时,使用别名映射。
示例:Scott 和 Scooter,或 MSFT 和 Microsoft。自定义绕过 允许您上载字符串的自定义列表,然后可以使用该列表来指示永远不应匹配的字符串。
当您有数据具有应忽略的通用值(如虚拟电话号码或虚拟电子邮件)时,自定义绕过非常有用。
示例:Never match the phone 555-1212, or test@contoso.com
精度:设置精度级别。 精度用于精确匹配和模糊匹配,并确定两个字符串需要多接近才能被视为匹配。
- 基本:从低 (30%)、中 (60%)、高 (80%) 和精确 (100%) 中选择。 选择精确以仅匹配 100% 匹配的记录。
- 自定义:设置记录需要匹配的百分比。 系统将只匹配传递此阈值的记录。
名称:规则的名称。
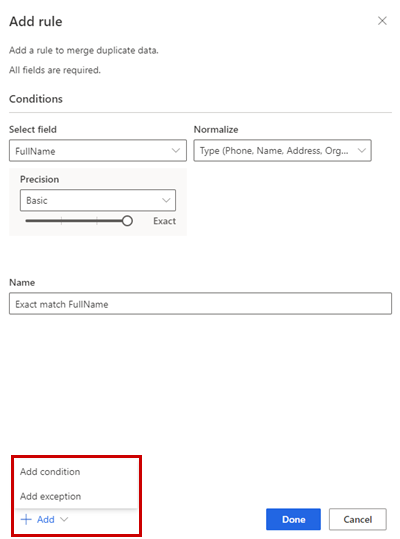
或者,也可以选择添加>添加条件向规则添加更多条件。 条件与逻辑 AND 运算符相连,因此仅在满足所有条件时才会执行。
或者,也可以选择添加>添加异常以向规则中添加异常。 异常用于解决个别情况下的误报和漏报。
选择完成以创建规则。
(可选)添加更多规则。

选择合并首选项
在运行规则并识别客户的重复记录时,将根据合并策略选择“获胜者行”。 获胜者行代表下一个统一步骤(在表之间匹配记录)中的客户。 在“匹配规则”统一步骤中,将使用非获胜者(“备用”)行中的数据将其他表中的记录与获胜者行进行匹配。 此方法允许以前的电话号码等信息帮助识别匹配的记录,从而改善匹配结果。 获胜者行可以被配置为找到的重复记录中最完整、最近或最早的记录。
选择表,然后选择编辑合并首选项。 合并首选项窗格将显示。
选择以下三个选项之一,以确定在发现重复项时要保留的记录:
- 最多填充:将包含最多填充列的记录标识为胜出记录。 这是默认的合并选项。
- 最常使用:根据最常使用标识入选记录。 需要日期或数字字段以定义近期性。
- 最不常用:根据最不常用标识入选记录。 需要日期或数字字段以定义近期性。
如果存在同等项,获胜者记录是具有 MAX(PK) 或较大主键值的记录。
(可选)要对表的各个列定义合并首选项,可以选择窗格底部的高级。 例如,您可以选择保留来自不同记录的最新电子邮件和最完整地址。 展开表以查看其所有列并定义用于各个列的选项。 如果您选择基于新近度的选项,您还需要指定定义新近度的日期/时间字段。
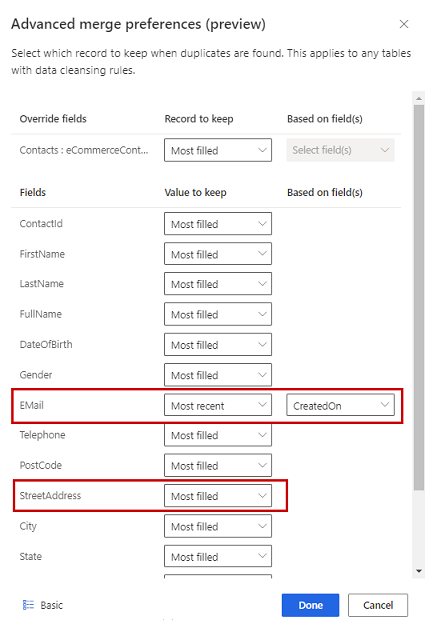
选择完成以应用合并首选项。
定义删除重复规则和合并首选项后,选择下一步。