数据统一最佳做法
在设置规则以将数据统一到客户配置文件时,请考虑以下最佳做法:
平衡统一与完全匹配的时间。 尝试捕获每个可能的匹配项会导致出现很多规则,而且统一需要很长时间。
应渐进地添加规则并跟踪结果。 删除不会改进匹配结果的规则。
对每个表进行重复数据删除,以使用单独一行表示每个客户。
使用规范化来标准化数据输入的变化形式,如 Street、St、St.、st。
策略性地使用模糊匹配来纠正拼写错误和错误,如 bob@contoso.com 和 bob@contoso.cm。模糊匹配比精确匹配需要更长的时间。 始终测试以查看在模糊匹配上花费的额外时间是否额外提高了匹配率。
使用完全匹配缩小匹配范围。 确保每个具有模糊条件的规则都至少有一个完全匹配条件。
不要匹配包含大量重复数据的列。 确保模糊匹配的列没有频繁重复的值,如窗体的默认值“Firstname”。
统一性能
每个规则运行都需要时间。 将每个表与另外的每个表进行比较或尝试捕获每个可能的记录匹配项等模式可能会导致较长的统一处理时间。 这还会在将每个表与基表进行比较的计划中返回很少的匹配项(如果有更多的匹配项)。
最好的方法是从一组您知道需要的基本规则开始,如将每个表与主表进行比较。 您的主要表应是具有最完整和最准确数据的表。 此表应排在“匹配规则统一”步骤的最前面。
逐渐添加多个规则,查看更改运行所需的时间以及结果是否有所改善。 转到设置>系统>状态,然后选择匹配查看每次统一运行的重复数据删除和匹配所花费的时间。
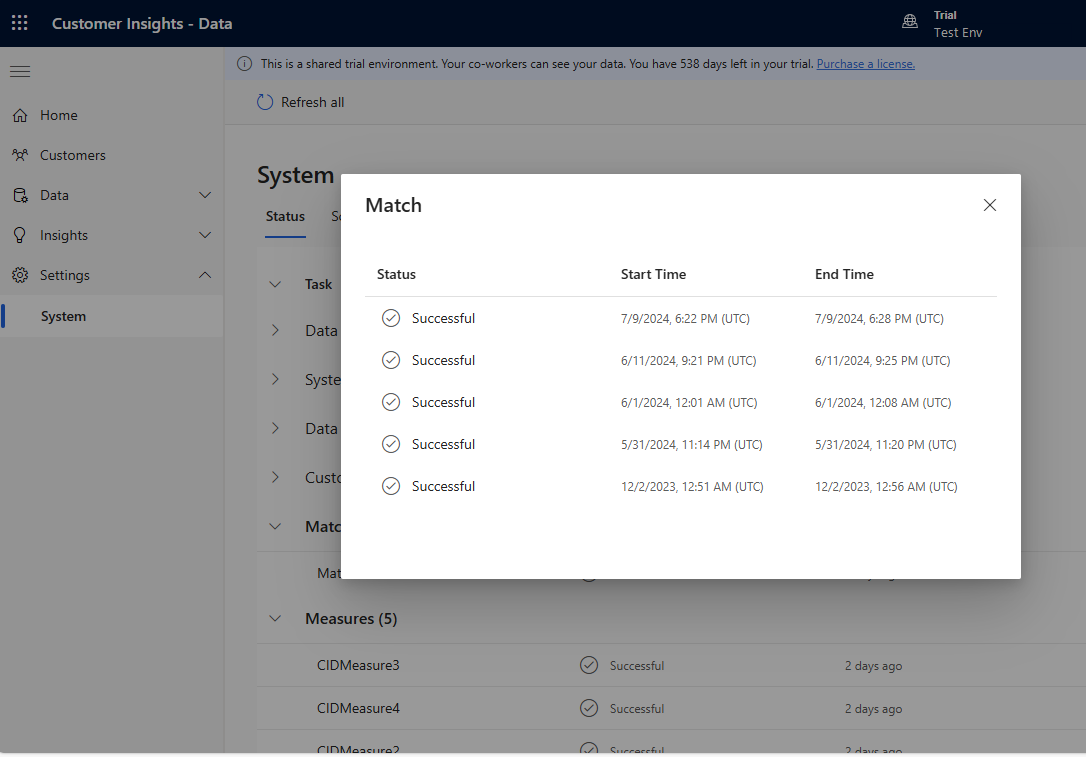
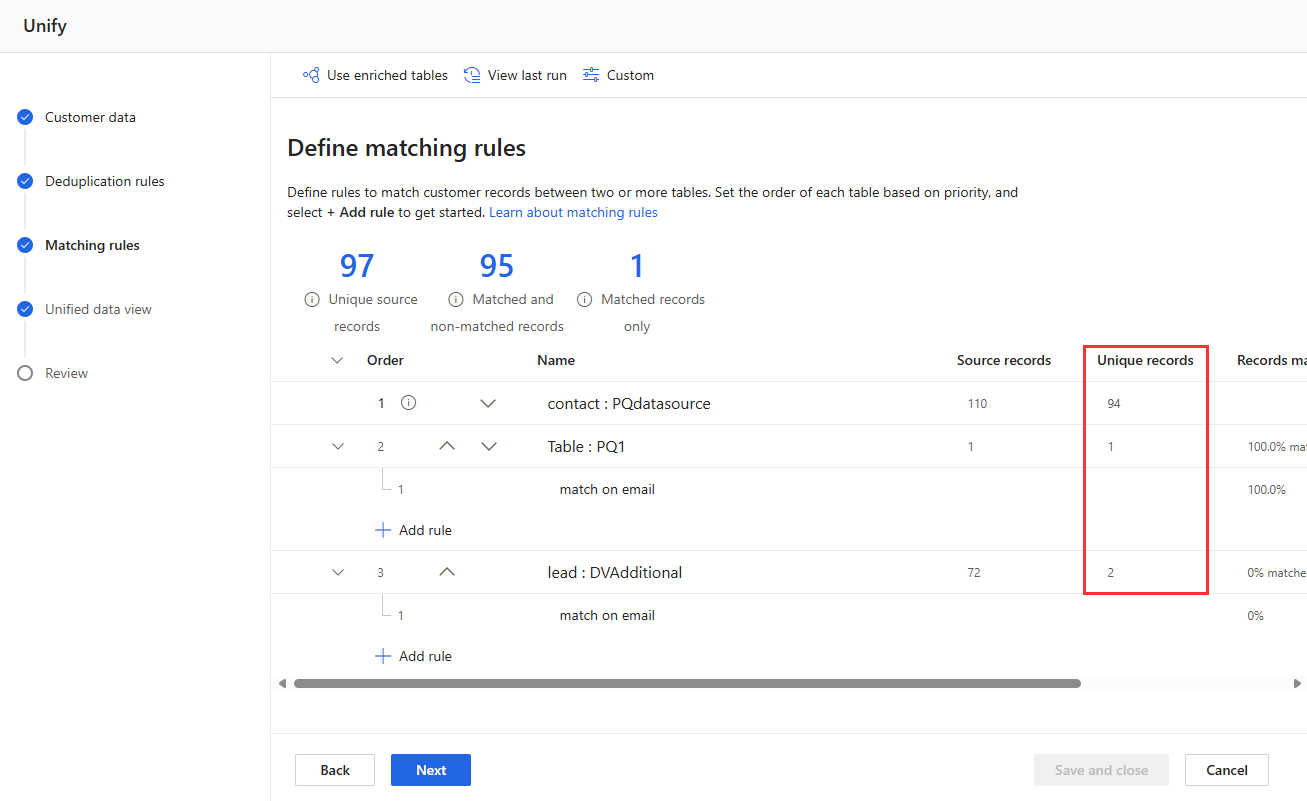
在重复数据删除规则和匹配规则页面上查看规则统计信息,看看唯一记录的数量是否发生变化。 如果新规则与某些记录匹配,并且唯一记录计数未改变,先前的规则将标识这些匹配项。
客户数据
在客户数据步骤中:
排除匹配规则不需要的列或您不希望包含在最终客户配置文件中的列。
查看智能映射选择的列说明。
并非所有列都需要映射。 映射电子邮件和地址字段等常见列可让 Customer Insights 简化下游流程,但对您的业务具有唯一 ID 或用途的列可以不映射。
删除重复项
使用重复数据删除规则删除表中的重复客户记录,让每个表中的单独一行代表一个客户。 好的规则可识别唯一客户。
在这个简单示例中,记录 1、2 和 3 共用电子邮件或电话号码,代表同一个人。
| ID | 客户 | 手机 | |
|---|---|---|---|
| 1 | 人员 1 | (425) 555-1111 | AAA@A.com |
| 2 | 人员 1 | (425) 555-1111 | BBB@B.com |
| 3 | 人员 1 | (425) 555-2222 | BBB@B.com |
| 4 | 人员 2 | (206) 555-9999 | Person2@contoso.com |
我们不想只在姓名上匹配,因为这会将不同的人与同一个姓名匹配。
使用与记录 1 和 2 匹配的“姓名”和“电话”创建规则 1。
使用与记录 2 和 3 匹配的“姓名”和“电子邮件”创建规则 2。
规则 1 和规则 2 的组合创建单个匹配组,因为它们共用记录 2。
您可以决定唯一标识客户的规则和条件的数量。 获得准确的规则取决于可用于匹配的数据、数据质量以及您希望重复数据删除过程达到的详尽程度。
标准化
使用规范化对数据进行标准化,以改善匹配效果。 规范化在大型数据集上表现良好。
标准化数据仅用于比较目的,以更有效地匹配客户记录。 它不会更改最终统一客户配置文件输出中的数据。
完全匹配
使用精度来确定两个字符串要多接近才能被视为匹配项。 默认精度设置要求达到完全匹配的要求。 任何其他值都支持该条件的模糊匹配。
精度可以设置为低(30% 匹配)、中(60% 匹配)和高(80% 匹配)。 或者,您可以以 1% 的增量自定义和设置精度。
精确匹配条件
精确匹配条件将先运行,以获取模糊匹配项的较小值集。 要达到预期结果,精确匹配条件应该具有合理程度的唯一性。 例如,如果所有客户都居住在同一个国家/地区,那么与该国家/地区完全匹配无助于缩小范围。
全名、电子邮件、电话或地址字段这样的列具有良好的唯一性,是用作精确匹配的理想列。
确保用于完全匹配条件的列没有任何频繁重复的值,如窗体捕获的默认值“名字”。 Customer Insights 可以分析数据列,提供对重复次数最多的值的见解。 您可以对 Azure Data Lake(使用 Common Data Model 或 Delta 格式)连接和 Synapse 启用数据分析。 数据分析会在数据源下次刷新时运行。 有关详细信息,请转到数据分析。
模糊匹配
使用模糊匹配来匹配接近但由于拼写错误或其他小变化而没有完全匹配的字符串。 应策略地使用模糊匹配,它比完全匹配要慢。 确保在任何具有模糊条件的规则中至少有一个完全匹配条件。
模糊匹配并非是要捕获 Suzzie 和 Suzanne 这样的名称变体。 使用规范化模式类型:名称或自定义别名匹配可以更好地捕获这些变体,这时,客户可以输入他们想要视为匹配项的名称变体列表。
您可以向规则添加条件,如匹配 FirstName 和 Phone。 给定规则中的条件是“AND”条件。 每个条件必须匹配,才能匹配行。 单独的规则是“OR”条件。 如果规则 1 与行不匹配,会将行与规则 2 进行比较。
备注
只有字符串数据类型列可以使用模糊匹配。 对于具有其他数据类型(如整数、双倍数或日期时间)的列,精度字段是只读的,设置为完全匹配。
模糊匹配计算
模糊匹配通过计算两个字符串之间的编辑距离分数来确定。 如果分数达到或超过精度阈值,字符串将被视为匹配项。
编辑距离是通过添加、删除或更改字符将一个字符串转换为另一个字符串所需的编辑次数。
例如,当我们删除字符 e 和 o 时,字符串“robert2020@hotmail.com”和“robrt2020@hotmail.cm”的编辑距离为二。 要计算编辑距离分数,使用以下公式:(基本字符串长度 – 编辑距离)/基本字符串长度。
| 基本字符串 | 比较字符串 | 分数 |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 - 2)/20 = 0.9 |