使用基于 Azure 机器学习的模型
Dynamics 365 Customer Insights - Data 中的统一数据是构建可生成其他业务见解的机器学习模型的来源。 Customer Insights - Data 与 Azure 机器学习集成,使用您自己的自定义模型。
先决条件
- 对 Customer Insights - Data 的访问权限
- 有效的 Azure Enterprise 订阅
- 统一客户配置文件
- 已配置将表导出到 Azure Blob 存储
设置 Azure 机器学习工作区
有关创建工作区的不同选项,请参阅创建 Azure 机器学习工作区。 为了获得最佳性能,请在地理位置距离 Customer Insights 环境最近的 Azure 区域中创建工作区。
通过 Azure 机器学习工作室访问您的工作区。 可通过多种交互方式与您的工作区进行交互。
使用 Azure 机器学习设计器
Azure 机器学习设计器提供了一个可视区域,可在其中拖放数据集和模块。 如果相应地配置了 Customer Insights - Data,则可以将从设计器创建的批处理管道集成到其中。
使用 Azure 机器学习 SDK
数据科学家和 AI 开发人员使用 Azure 机器学习 SDK 生成机器学习工作流。 当前,使用 SDK 训练的模型无法直接集成。 若要与 Customer Insights - Data 集成,需要使用该模型的批处理推理管道。
与 Customer Insights - Data 集成的批处理管道要求
数据集配置
创建数据集以将 Customer Insights 中的表数据用于批推理管道。 在工作区中注册这些数据集。 当前,我们仅支持采用 .csv 格式的表格数据集。 将与表数据对应的数据集参数化为管道参数。
设计器中的数据集参数
在设计器中,打开在数据集中选择列,然后选择设置为管道参数,可在其中提供参数的名称。
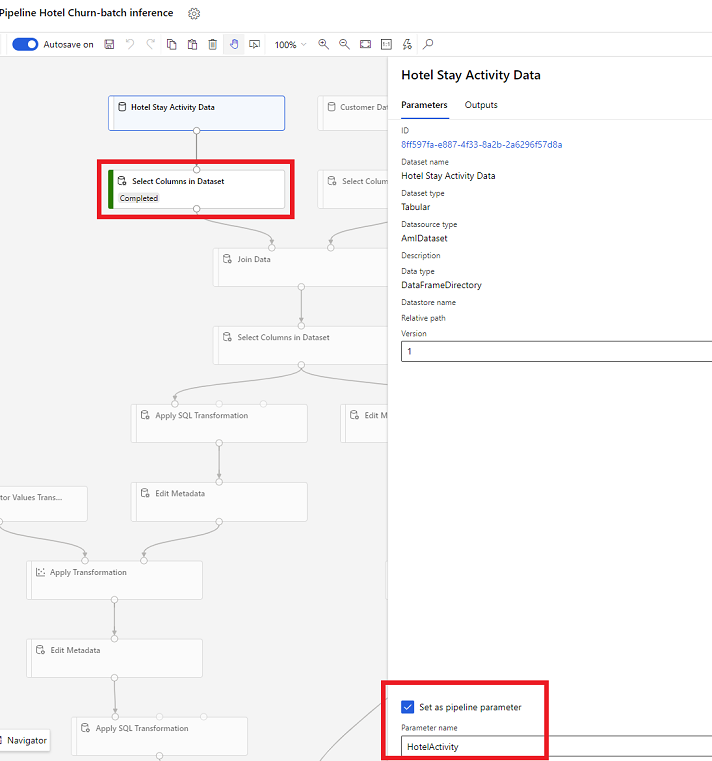
SDK 中的数据集参数 (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
批处理推理管道
在设计器中,使用训练管道创建或更新推理管道。 当前,仅支持批处理推理管道。
使用 SDK,将管道发布到终结点。 当前,Customer Insights - Data 将在机器学习工作区中与批处理管道终结点中的默认管道相集成。
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
导入管道数据
设计器提供导出数据模块,允许将管道的输出导出到 Azure 存储。 当前,模块必须使用数据存储类型 Azure Blob 存储并对数据存储和相对路径进行参数化。 系统会在管道执行期间使用应用程序可访问的数据存储和路径替代这些参数。
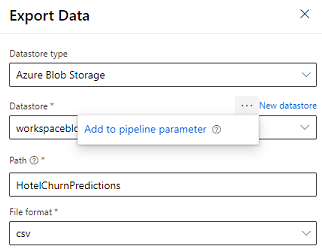
在使用代码编写推理输出时,在工作区中将输出上传到已注册数据存储内的路径。 如果路径和数据存储在管道中进行了参数化,Customer insights 将能够读取和导入推理输出。 当前,支持采用 csv 格式的单个表格输出。 路径必须包含目录和文件名。
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name