教程:使用矩阵分解和 ML.NET 生成电影推荐器
本教程介绍如何在 .NET 控制台应用程序中生成具有 ML.NET 的电影推荐器。 这些步骤使用 C# 和 Visual Studio 2019。
本教程中,您将学习如何:
- 选择机器学习算法
- 准备并加载数据
- 生成和训练模型
- 评估模型
- 部署和使用模型
可以在 dotnet/samples 存储库中找到本教程的源代码。
机器学习工作流
你将使用以下步骤来完成任务,以及任何其他 ML.NET 任务:
先决条件
选择适当的机器学习任务
有多种方法可以解决推荐问题,例如推荐电影列表或推荐相关产品列表,但在这种情况下,你将预测用户向特定电影提供什么评级(1-5),如果电影高于定义的阈值(评分越高,用户喜欢特定电影的可能性越高),建议该电影。
创建控制台应用程序
创建项目
创建名为“MovieRecommender”的 C# 控制台应用程序。 单击 “下一步” 按钮。
选择 .NET 8 作为要使用的框架。 单击“创建”按钮。
在项目中创建名为 Data 的目录以存储数据集:
在 解决方案资源管理器中,右键单击项目并选择“添加>新文件夹。 键入“Data”并选择 Enter。
安装 Microsoft.ML 和 Microsoft.ML.Recommender NuGet 包:
注意
此示例使用提到的 NuGet 包的最新稳定版本,除非另有说明。
在 解决方案资源管理器中,右键单击项目并选择 管理 NuGet 包。 选择“nuget.org”作为包源,选择“浏览”选项卡,搜索 Microsoft.ML,选择列表中的包,然后选择 安装。 在“预览更改”对话框中选择“确定”按钮,然后在“许可接受”对话框中选择“我接受”按钮,如果您同意列出的软件包许可条款。 对“Microsoft.ML.Recommender”重复这些步骤。
在 Program.cs 文件的顶部添加以下
using指令:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
下载您的数据
下载两个数据集并将其保存到之前创建的 数据 文件夹中:
右键单击 recommendation-ratings-train.csv 并选择“保存链接(或目标)...”。
右键单击 recommendation-ratings-test.csv 并选择“保存链接(或目标)...”。
请确保将 *.csv 文件保存到 Data 文件夹中,或者在其他位置保存后,将 *.csv 文件移动到 Data 文件夹中。
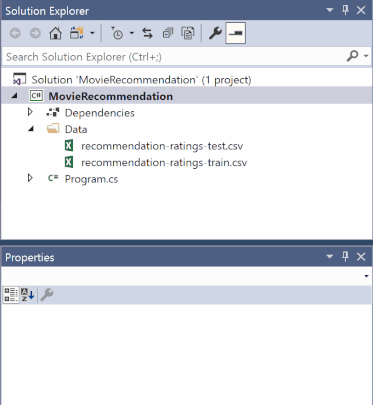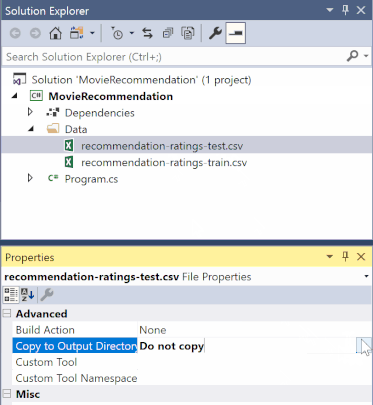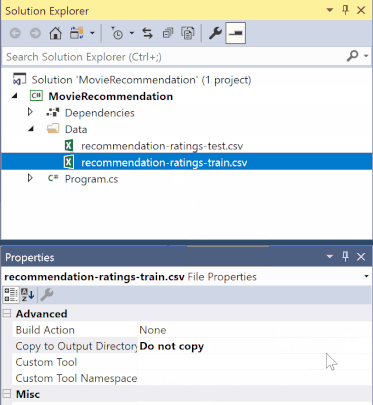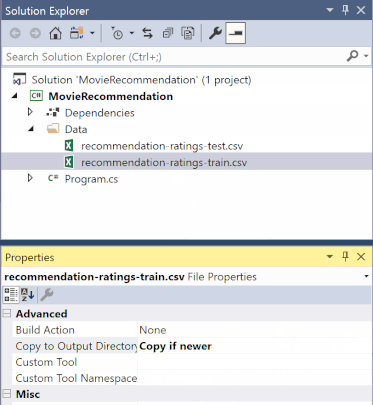
在“解决方案资源管理器”中,右键单击每个 *.csv 文件,然后选择“属性”。 在“高级”下,将“复制到输出目录”的值更改为“如果较新则复制”。
用户在 VS 中选择“较新则复制”的 GIF。
加载数据
ML.NET 过程中的第一步是准备和加载模型训练和测试数据。
建议分级数据拆分为 Train 和 Test 数据集。 Train 数据用于适应模型。 Test 数据用于使用训练的模型进行预测并评估模型性能。 通常情况下,Train 和 Test 数据的分配比例是 80/20。
您的 *.csv 文件中的数据预览如下:
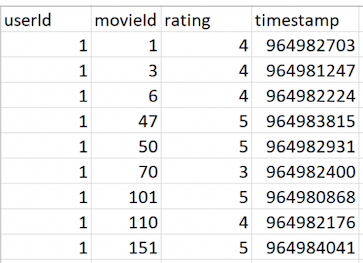
在 *.csv 文件中,有四列:
userIdmovieIdratingtimestamp
在机器学习中,用于进行预测的列称为 特征,返回的预测的列称为 标签。
想要预测影片评分,因此评分列为 Label。 其他三列,userId、movieId 和 timestamp 都用 Features 来预测 Label。
| 功能 | Label |
|---|---|
userId |
rating |
movieId |
|
timestamp |
由你来决定使用哪个 Features 来预测 Label。 你还可以使用排列特征重要性等方法来帮助选择最佳 Features。
在这种情况下,应将 timestamp 列作为 Feature 消除,因为时间戳不会真正影响用户对给定电影进行评分的方式,因此不会对做出更准确的预测做出贡献:
| 功能 | Label |
|---|---|
userId |
rating |
movieId |
接下来,必须为输入类定义数据结构。
向项目添加新类:
在 解决方案资源管理器中,右键单击项目,然后选择“添加 > 新项”。
在“添加新项”对话框中,选择 类,并将 名称 字段更改为 MovieRatingData.cs。 然后选择“添加”。
MovieRatingData.cs 文件将在代码编辑器中打开。 将以下 using 指令添加到 MovieRatingData.cs顶部:
using Microsoft.ML.Data;
通过删除现有类定义并在 MovieRatingData.cs中添加以下代码来创建名为 MovieRating 的类:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating 指定输入数据类。 LoadColumn 属性指定应加载数据集中哪些列(按列索引指定)。 userId 和 movieId 列是你的 Features(你将向模型提供预测 Label 的输入),而评分列是你将预测的 Label 模型的输出)。
创建另一个类 MovieRatingPrediction,通过在 MovieRatingData.cs中的 MovieRating 类后面添加以下代码来表示预测结果:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
在 Program.cs中,将 Console.WriteLine("Hello World!") 替换为以下代码:
MLContext mlContext = new MLContext();
MLContext 类 是所有 ML.NET 操作的起点,初始化 mlContext 创建一个新的 ML.NET 环境,可在模型创建工作流对象之间共享。 从概念上讲,它类似于实体框架中的 DBContext。
在文件的底部,创建一个名为 LoadData()的方法:
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
注意
除非在以下步骤中添加返回语句,否则使用此方法将出错。
初始化数据路径变量,从 *.csv 文件加载数据,并在 LoadData()中添加以下内容作为下一行代码,将 Train 和 Test 数据以 IDataView 对象的形式返回。
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
ML.NET 中的数据表示为 IDataView 接口。 IDataView 是描述表格数据(数字和文本)的灵活高效方法。 可以将数据从文本文件或实时(例如 SQL 数据库或日志文件)加载到 IDataView 对象。
LoadFromTextFile() 用于定义数据架构并读取文件。 它接受数据路径变量并返回 IDataView。 在这种情况下,请提供 Test 和 Train 文件的路径,并指示文本文件标头(以便它可以正确使用列名)和逗号字符数据分隔符(默认分隔符为制表符)。
添加以下代码以调用 LoadData() 方法并返回 Train 和 Test 数据:
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
生成和训练模型
使用以下代码在 LoadData() 方法后面创建 BuildAndTrainModel() 方法:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
注意
除非在以下步骤中添加返回语句,否则使用此方法将出错。
通过将以下代码添加到 BuildAndTrainModel()来定义数据转换:
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
由于 userId 和 movieId 表示用户和电影标题,而不是实际值,因此使用 MapValueToKey() 方法将每个 userId 和每个 movieId 转换为数字键类型 Feature 列(推荐算法接受的格式),并将其添加为新的数据集列:
| userId | movieId | Label | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
选择机器学习算法并将其追加到数据转换定义,方法是在 BuildAndTrainModel()中添加以下内容作为下一行代码:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer 就是推荐训练算法。 矩阵分解 是在需要对用户过去的产品评分数据进行推荐时常用的一种方法,这正是本教程使用的数据集的情况。 当你有不同的数据时,可以使用其他推荐算法(请参阅下面的 其他推荐算法 部分了解更多信息)。
在这种情况下,Matrix Factorization 算法使用一种称为“协作筛选”的方法,该方法假定如果用户 1 在某些问题上与用户 2 有相同的意见,则用户 1 更有可能像用户 2 一样了解不同的问题。
例如,如果用户 1 和用户 2 同样评价电影,则用户 2 更有可能享受用户 1 观看并评价高的电影:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| User 1 | 观看过并喜欢的电影 | 观看和点赞过的影片 | 看过并喜欢的电影 |
| User 2 | 观看和点赞过的影片 | 看过并喜欢的电影 | 没有看过 - 推荐影片 |
Matrix Factorization 训练器有几个 选项,你可以在下面的 算法超参数 部分阅读详细信息。
在 BuildAndTrainModel() 方法中添加以下代码作为下一代码行,使模型适应 Train 数据,并返回经过训练的模型:
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Fit() 方法使用提供的训练数据集来训练您的模型。 技术上讲,它通过数据转换和应用训练过程来执行 Estimator 定义,并返回训练后的模型,即一个 Transformer。
有关 ML.NET 中的模型训练工作流的详细信息,请参阅 什么是 ML.NET 及其工作原理?。
将以下内容添加为调用 LoadData() 方法下面的下一行代码,以调用 BuildAndTrainModel() 方法并返回训练的模型:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
评估模型
训练模型后,使用测试数据评估模型的性能。
使用以下代码在 BuildAndTrainModel() 方法后面创建 EvaluateModel() 方法:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
通过将以下代码添加到 EvaluateModel()来转换 Test 数据:
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Transform() 方法对测试数据集中提供的多个输入行进行预测。
通过在 EvaluateModel() 方法中添加以下内容作为下一行代码来评估模型:
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
设置预测后,Evaluate() 方法会评估模型,该模型将预测值与测试数据集中的实际 Labels 进行比较,并返回模型执行方式的指标。
在 EvaluateModel() 方法中添加以下内容作为下一行代码,以将评估指标打印到控制台:
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
将以下代码添加到调用 BuildAndTrainModel() 方法的下一行,以便调用 EvaluateModel() 方法:
EvaluateModel(mlContext, testDataView, model);
到目前为止,输出应类似于以下文本:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
在此输出中,有 20 次迭代。 在每个迭代中,误差度量值会减少,收敛越来越接近 0。
root of mean squared error(RMS 或 RMSE)用于测量模型预测值与测试数据集观测值之间的差异。 从技术上看,它是误差平方平均值的平方根。 指标越低,模型就越好。
R Squared 指示数据与模型拟合程度。 范围为 0 到 1。 值为 0 表示数据是随机的,否则不能适合模型。 值为 1 表示模型与数据完全匹配。 你希望你的 R Squared 分数尽可能接近 1。
生成成功的模型是一个迭代过程。 此模型的初始质量较低,因为本教程使用小型数据集来提供快速模型训练。 如果对模型质量不满意,可以通过提供更大的训练数据集或为每个算法选择具有不同超参数的不同训练算法来尝试改进它。 有关详细信息,请查看下面的改进模型部分。
使用模型
现在,可以使用训练的模型对新数据进行预测。
使用以下代码在 EvaluateModel() 方法后面创建 UseModelForSinglePrediction() 方法:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
使用 PredictionEngine 通过将以下代码添加到 UseModelForSinglePrediction() 来预测评分:
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine 是一种方便的 API,可用于对单个数据实例执行预测。 PredictionEngine 不是线程安全的。 可以在单线程或原型环境中使用。 为了提高生产环境中的性能和线程安全性,请使用 PredictionEnginePool 服务,该服务可创建 PredictionEngine 对象的 ObjectPool,以便在应用程序中使用。 请参阅本指南,了解如何在 ASP.NET Core Web API中
注意
PredictionEnginePool 服务扩展目前为预览版。
创建一个名为 testInput 的 MovieRating 实例,并通过在 UseModelForSinglePrediction() 方法中添加以下代码作为下一代码行,将其传递给预测引擎:
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Predict() 函数对单个数据列进行预测。
然后,你可以使用 Score或预测评分来确定是否要将电影编号为 10 的电影推荐给用户 6。 Score越高,用户喜欢特定电影的可能性就越大。 在这种情况下,假设你推荐预测评分 > 3.5 的电影。
若要打印结果,请在 UseModelForSinglePrediction() 方法中添加以下内容作为下一行代码:
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
在调用 EvaluateModel() 方法后,添加以下内容作为下一行代码以调用 UseModelForSinglePrediction() 方法:
UseModelForSinglePrediction(mlContext, model);
此方法的输出应类似于以下文本:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
保存模型
若要使用模型在最终用户应用程序中进行预测,必须先保存模型。
使用以下代码在 UseModelForSinglePrediction() 方法后面创建 SaveModel() 方法:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
通过在 SaveModel() 方法中添加以下代码来保存训练的模型:
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
此方法将训练的模型保存到 .zip 文件(位于“数据”文件夹中),然后可用于其他 .NET 应用程序进行预测。
在调用 UseModelForSinglePrediction() 方法后,添加以下内容作为下一行代码以调用 SaveModel() 方法:
SaveModel(mlContext, trainingDataView.Schema, model);
使用已保存的模型
保存已训练的模型后,可以在不同的环境中使用该模型。 请参阅 保存和加载训练的模型,了解如何在应用中操作训练的机器学习模型。
结果
执行上述步骤后,运行控制台应用(Ctrl + F5)。 您从以上单个预测得出的结果应如下所示。 你可能会看到警告或处理消息,但为了清楚起见,这些消息已从以下结果中删除。
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
祝贺! 现在,你已成功构建了用于推荐电影的机器学习模型。 可以在 dotnet/samples 存储库中找到本教程的源代码。
改进模型
有多种方法可以改进模型的性能,以便获得更准确的预测。
数据
为每个用户和电影 ID 添加具有足够样本的更多训练数据有助于提高推荐模型的质量。
交叉验证 是一种评估模型的技术,可将数据随机拆分为子集(而不是像在本教程中一样从数据集中提取测试数据),并采用某些组作为训练数据和某些组作为测试数据。 从模型质量方面看,该方法优于进行训练-测试拆分。
功能
在本教程中,仅使用数据集提供的三个 Features(user id、movie id和 rating)。
虽然这是一个良好的开端,但实际上你可能希望添加其他属性或 Features(例如,年龄、性别、地理位置等),如果它们包含在数据集中。 添加更相关的 Features 可以帮助提高建议模型的性能。
如果你不确定哪个 Features 可能与机器学习任务最相关,还可以使用 ML.NET 提供的特征贡献计算 (FCC) 和排列特征重要性来发现最有影响力的 Features。
算法超参数
虽然 ML.NET 提供良好的默认训练算法,但可以通过更改算法 超参数进一步微调性能。
对于 Matrix Factorization,可以试验超参数,例如 NumberOfIterations 和 ApproximationRank,以查看这是否提供了更好的结果。
例如,在本教程中,算法选项包括:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
其他建议算法
具有协作筛选的矩阵分解算法只是执行电影建议的一种方法。 在许多情况下,你可能没有可用的分级数据,并且只有可供用户使用的电影历史记录。 在其他情况下,你可能不仅仅拥有用户的评分数据。
| 算法 | 场景 | 示例 |
|---|---|---|
| 一类矩阵分解 | 如果只有 userId 和 movieId,请使用此选项。 这种建议风格基于共同购买方案,或经常一起购买的产品,这意味着它将根据自己的采购订单历史记录向客户推荐一组产品。 | >试试看 |
| 场感知分解机 | 当你拥有除 userId、productId 和评级以外的更多功能(例如产品说明或产品价格)时,请使用此选项提出建议。 此方法还使用协作筛选方法。 | >尝试一下 |
新用户场景
协作筛选中的一个常见问题是冷启动问题,即有一个新用户没有以前的数据来从中提取推理。 此问题通常通过要求新用户创建个人资料来解决,例如,为他们过去看到的电影评分。 虽然此方法给用户带来了一些负担,但它为没有分级历史记录的新用户提供了一些起始数据。
资源
本教程中使用的数据派生自 MovieLens 数据集。
后续步骤
在本教程中,您已经学习了如何:
- 选择机器学习算法
- 准备并加载数据
- 生成和训练模型
- 评估模型
- 部署和使用模型
转到下一教程,了解详细信息