教程:通过 ML.NET 图像分类 API 使用传输学习自动进行视觉检查
了解如何使用转移学习、预先训练的 TensorFlow 模型和 ML.NET 图像分类 API 来训练自定义深度学习模型,以将混凝土表面的图像分类为裂缝或未破解。
本教程介绍如何执行下列操作:
- 了解问题
- 了解 ML.NET 图像分类 API
- 了解预先训练的模型
- 使用传输学习训练自定义 TensorFlow 图像分类模型
- 使用自定义模型对图像进行分类
先决条件
了解问题
图像分类是计算机视觉问题。 图像分类采用图像作为输入,并将其分类为规定的类。 图像分类模型通常使用深度学习和神经网络进行训练。 有关详细信息,请参阅 深度学习与机器学习。
图像分类非常有用的一些场景包括:
- 面部识别
- 情感检测
- 医学诊断
- 路标检测
本教程训练自定义图像分类模型,以对桥面执行自动视觉检查,以识别裂缝损坏的结构。
ML.NET 图像分类 API
ML.NET 提供了各种执行图像分类的方法。 本教程使用图像分类 API 应用传输学习。 图像分类 API 使用 TensorFlow.NET,这是一个为 TensorFlow C++ API 提供 C# 绑定的底层库。
什么是转移学习?
转移学习将从解决一个问题中获得的知识应用于另一个相关问题。
从头开始训练深度学习模型需要设置多个参数、大量的标记训练数据和大量的计算资源(数百个 GPU 小时)。 使用预训练模型和迁移学习,可以简化训练过程。
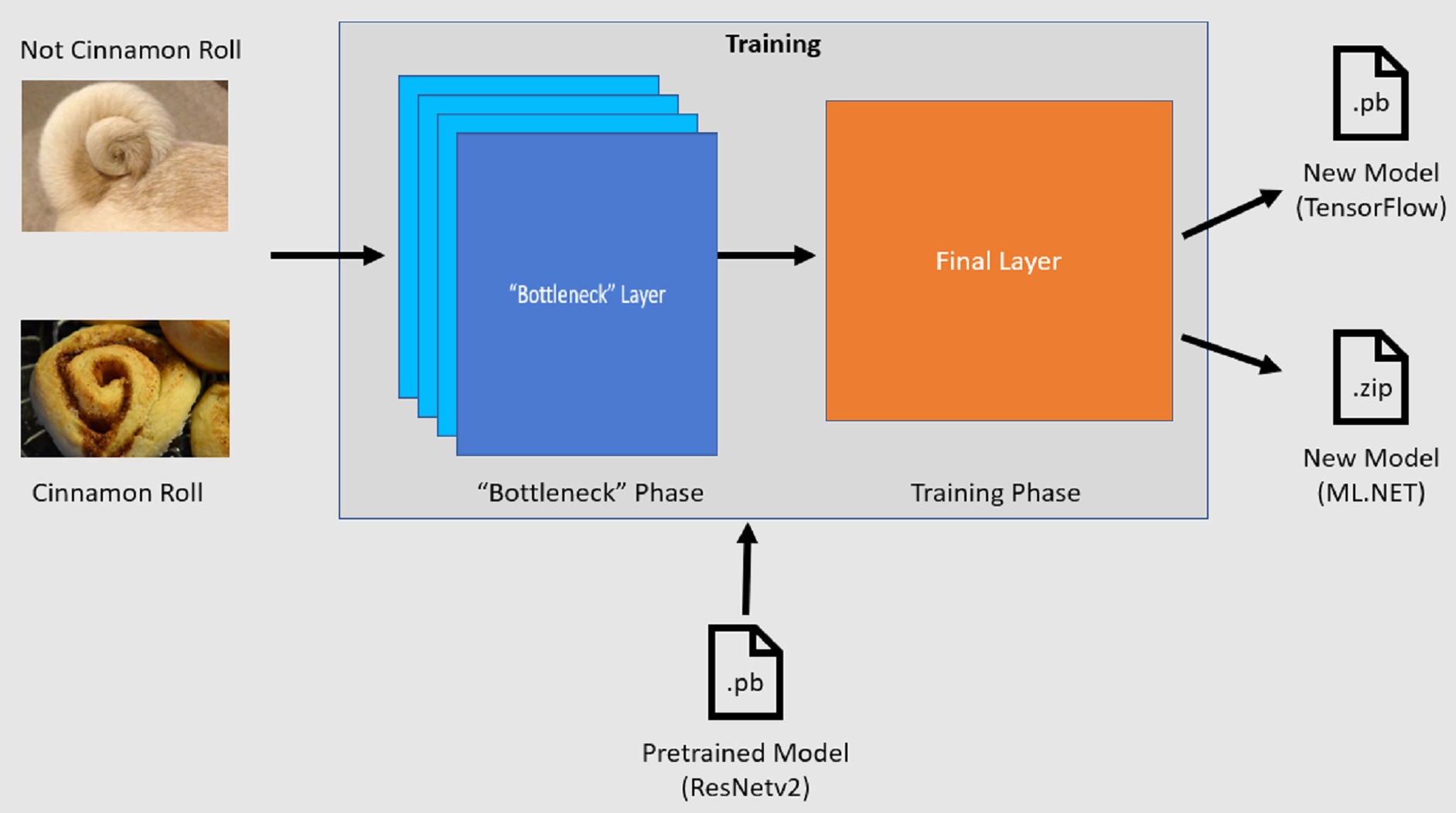
培训过程
图像分类 API 通过加载预先训练的 TensorFlow 模型来启动训练过程。 训练过程由两个步骤组成:
- 瓶颈阶段。
- 训练阶段。
瓶颈阶段
在瓶颈阶段,会加载训练图像集,并将像素值用作预先训练模型冻结层的输入或功能。 冻结层包括神经网络中的所有层,最多包含倒数第二层,非正式地称为瓶颈层。 这些层被称为冻结层,因为这些层中不会出现任何训练并且操作是直通的。 正是在这些冻结层中,较低级别的模式被计算出来,以帮助模型区分不同的类别。 层数越大,此步骤的计算密集型就越大。 幸运的是,由于这是一次性计算,因此在试验不同的参数时,可以在以后的运行中缓存和使用结果。
训练阶段
计算瓶颈阶段的输出值后,它们将用作输入以重新训练模型的最后一层。 此过程是迭代的,针对模型参数指定的次数运行。 在每次运行过程中,都将评估损失和准确度。 然后,进行适当的调整以改进模型,目的是最大程度地减少损失并最大程度地提高准确性。 训练完成后,输出两种模型格式。 其中一个是模型的 .pb 版本,另一个是模型的 .zip ML.NET 序列化版本。 在 ML.NET 支持的环境中工作时,建议使用模型 .zip 版本。 但是,在不支持 ML.NET 的环境中,可以选择使用 .pb 版本。
了解预先训练的模型
本教程中使用的预先训练模型是残差网络 (ResNet) v2 模型的 101 层变体。 原始模型经过训练,将图像分类为一千个类别。 此模型将大小为 224 x 224 的图像作为输入,并输出其训练的每个类的类概率。 此模型的一部分用于使用自定义图像训练新模型,以在两个类之间进行预测。
创建控制台应用程序
现在,你已大致了解了迁移学习和图像分类 API,接下来可以生成应用程序。
创建名为“DeepLearning_ImageClassification_Binary”的 C# 控制台应用程序。 单击 下一步 按钮。
选择 .NET 8 作为要使用的框架,然后选择 创建。
安装 Microsoft.ML NuGet 包:
注意
此示例使用提到的 NuGet 包的最新稳定版本,除非另有说明。
- 在“解决方案资源管理器”中,右键单击项目,然后选择“管理 NuGet 包”。
- 选择“nuget.org”作为包源。
- 选择“浏览”选项卡。
- 选中“包括预发行版”复选框。
- 搜索 Microsoft.ML。
- 选择“安装”按钮。
- 如果同意所列包的许可条款,请选择接受许可对话框中的我接受按钮。
- 请为 Microsoft.ML.Vision、SciSharp.TensorFlow.Redist(版本 2.3.1)和 Microsoft.ML.ImageAnalytics NuGet 包重复这些步骤。
准备和了解数据
注意
本教程使用的数据集来自Maguire, Marc; Dorafshan, Sattar; 和Thomas, Robert J.,《SDNET2018:用于机器学习应用的混凝土裂缝图像数据集》(2018年)。 浏览所有数据集。 论文 48。 https://digitalcommons.usu.edu/all_datasets/48
SDNET2018是一个图像数据集,其中包含裂缝和非裂缝混凝土结构(桥牌、墙壁和人行道)的批注。

数据按三个子目录进行组织:
- D 包含桥面图像
- P 包含路面图像
- W 包含墙壁图像
每个子目录都包含另外两个带前缀的子目录:
- C 是用于有裂缝的表面的前缀
- U 是用于无裂缝的表面的前缀
在本教程中,仅使用桥牌图像。
- 下载 数据集 并解压缩。
- 在项目中创建名为“Assets”的目录以保存数据集文件。
- 将 CD 和 UD 子目录从最近解压缩的目录复制到 Assets 目录。
创建输入和输出类
打开 Program.cs 文件,并将现有内容替换为以下
using指令:using Microsoft.ML; using Microsoft.ML.Vision; using static Microsoft.ML.DataOperationsCatalog;创建名为
ImageData的类。 此类用于表示最初加载的数据。class ImageData { public string? ImagePath { get; set; } public string? Label { get; set; } }ImageData包含以下属性:ImagePath是存储映像的完全限定路径。Label是图像所属的类别。 这是要预测的值。
为输入和输出数据创建类。
在
ImageData类下方,在名为ModelInput的新类中定义输入数据的架构。class ModelInput { public byte[]? Image { get; set; } public uint LabelAsKey { get; set; } public string? ImagePath { get; set; } public string? Label { get; set; } }ModelInput包含以下属性:-
Image是图像的byte[]表示形式。 模型预期图像数据为这种类型,以便用于训练。 LabelAsKey是Label的数字表示形式。ImagePath是存储映像的完全限定路径。Label是图像所属的类别。 这是要预测的值。
仅使用
Image和LabelAsKey来训练模型并进行预测。 为了方便访问原始图像文件名和类别,保留ImagePath和Label属性。-
然后,在
ModelInput类下方,在名为ModelOutput的新类中定义输出数据的架构。class ModelOutput { public string? ImagePath { get; set; } public string? Label { get; set; } public string? PredictedLabel { get; set; } }ModelOutput包含以下属性:ImagePath是存储映像的完全限定路径。Label是图像所属的原始类别。 这是要预测的值。PredictedLabel是模型预测的值。
与
ModelInput类似,只有PredictedLabel才能进行预测,因为它包含模型的预测。 为了方便访问原始图像文件名和类别,保留ImagePath和Label属性。
定义路径并初始化变量
在
using指令下,将以下代码添加到:定义资产的位置。
使用 MLContext的新实例初始化
mlContext变量。MLContext 类是所有 ML.NET 操作的起点,初始化 mlContext 将创建一个新的 ML.NET 环境,该环境可在模型创建工作流对象之间共享。 从概念上讲,它类似于实体框架中的
DbContext。
var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var assetsRelativePath = Path.Combine(projectDirectory, "Assets"); MLContext mlContext = new();
加载数据
创建数据加载实用工具方法
这些图像存储在两个子目录中。 在加载数据之前,需要将其格式化为 ImageData 对象列表。 为此,请创建 LoadImagesFromDirectory 方法:
static IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
var files = Directory.GetFiles(folder, "*",
searchOption: SearchOption.AllDirectories);
foreach (var file in files)
{
if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png"))
continue;
var label = Path.GetFileName(file);
if (useFolderNameAsLabel)
label = Directory.GetParent(file)?.Name;
else
{
for (int index = 0; index < label.Length; index++)
{
if (!char.IsLetter(label[index]))
{
label = label[..index];
break;
}
}
}
yield return new ImageData()
{
ImagePath = file,
Label = label
};
}
}
LoadImagesFromDirectory 方法:
- 获取子目录中的所有文件路径。
- 使用
foreach语句循环访问每个文件,并检查是否支持文件扩展名。 图像分类 API 支持 JPEG 和 PNG 格式。 - 获取文件的标签。 如果
useFolderNameAsLabel参数设置为true,则将保存文件的父目录用作标签。 否则,标签应为文件名的前缀或文件名本身。 - 创建
ModelInput的新实例。
准备数据
在创建 MLContext的新实例的行后面添加以下代码。
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);
IDataView imageData = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);
var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey(
inputColumnName: "Label",
outputColumnName: "LabelAsKey")
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: assetsRelativePath,
inputColumnName: "ImagePath"));
IDataView preProcessedData = preprocessingPipeline
.Fit(shuffledData)
.Transform(shuffledData);
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3);
TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);
IDataView trainSet = trainSplit.TrainSet;
IDataView validationSet = validationTestSplit.TrainSet;
IDataView testSet = validationTestSplit.TestSet;
前面的代码:
调用
LoadImagesFromDirectory实用工具方法,以获取初始化mlContext变量后用于训练的图像列表。使用
LoadFromEnumerable方法将图像加载到IDataView。使用
ShuffleRows方法重新组合数据。 数据按从目录读取的顺序加载。 重新组合是为了达到平衡。在训练之前对数据执行一些预处理。 这样做是因为机器学习模型希望输入采用数字格式。 预处理代码创建了一个由
MapValueToKey和LoadRawImageBytes转换组成的EstimatorChain。MapValueToKey转换采用Label列中的分类值,将其转换为数值KeyType值,并将其存储在名为LabelAsKey的新列中。LoadImages采用ImagePath列中的值和imageFolder参数,以加载用于训练的图像。使用
Fit方法将数据应用于preprocessingPipelineEstimatorChain,然后使用Transform方法,该方法返回一个包含预处理数据的IDataView。将数据拆分为训练、验证和测试集。
若要训练模型,必须具有训练数据集和验证数据集。 模型在训练集中进行训练。 它对不可见数据的预测能力取决于针对验证集的性能。 根据该性能的结果,模型会调整其所学到的内容,以改进它。 验证集可以来自拆分原始数据集,也可以来自为此目的而保留的其他源。
代码示例执行两种拆分。 首先,预处理的数据被拆分,70 个% 用于训练,其余 30 个% 用于验证。 然后,30 个% 验证集进一步拆分为验证集和测试集,其中 90% 用于验证,10 个% 用于测试。
考虑这些数据分区目的的一种方法是参加考试。 在学习考试时,可以查看笔记、书籍或其他资源,以掌握考试中的概念。 这便是训练集的作用。 然后,可以参加模拟考试来验证知识。 这时验证集便派上了用场。 在参加实际考试之前,你需要检查你是否对概念有很好的把握。 根据这些结果,你可以记下做错的内容或无法充分理解的内容,并在复习以应对实际测试时纳入更改。 最后,进行测试。 这是测试集的用途。 你从未见过考试中的问题,现在利用你从培训和验证中学到的内容来完成手头的任务。
为训练、验证和测试数据分配分区各自的值。
定义训练管道
模型训练由两个步骤组成。 首先,图像分类 API 用于训练模型。 然后,使用 MapKeyToValue 转换将 PredictedLabel 列中的编码标签转换回其原始分类值。
var classifierOptions = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
ValidationSet = validationSet,
Arch = ImageClassificationTrainer.Architecture.ResnetV2101,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
TestOnTrainSet = false,
ReuseTrainSetBottleneckCachedValues = true,
ReuseValidationSetBottleneckCachedValues = true
};
var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
ITransformer trainedModel = trainingPipeline.Fit(trainSet);
前面的代码:
创建一个新变量,用于存储 ImageClassificationTrainer的必需参数和可选参数集。 ImageClassificationTrainer 使用几个可选参数:
FeatureColumnName是用作模型输入的列。-
LabelColumnName是要预测的值的列。 -
ValidationSet是包含验证数据的IDataView。 Arch定义要使用的预训练模型体系结构。 本教程使用 ResNetv2 模型的 101 层变体。MetricsCallback绑定函数以跟踪训练期间的进度。TestOnTrainSet告知模型在不存在验证集时根据训练集测量性能。ReuseTrainSetBottleneckCachedValues告知模型是否在后续运行中使用瓶颈阶段的缓存值。 瓶颈阶段是在第一次执行时需要大量计算的一次性直通计算。 如果训练数据未更改,并且想要使用不同数量的纪元或批大小进行试验,则使用缓存值会显著减少训练模型所需的时间。ReuseValidationSetBottleneckCachedValues类似于ReuseTrainSetBottleneckCachedValues,只不过在这种情况下用于验证数据集。
定义由
mapLabelEstimator和 ImageClassificationTrainer组成的EstimatorChain训练管道。使用
Fit方法训练模型。
使用模型
训练模型后,即可使用它对图像进行分类。
创建名为 OutputPrediction 的新实用工具方法,在控制台中显示预测信息。
static void OutputPrediction(ModelOutput prediction)
{
string? imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
对单个图像进行分类
创建一个名为
ClassifySingleImage的方法,用于生成和输出单个图像预测。static void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel); ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data, reuseRowObject: true).First(); ModelOutput prediction = predictionEngine.Predict(image); Console.WriteLine("Classifying single image"); OutputPrediction(prediction); }ClassifySingleImage方法:- 在
ClassifySingleImage方法中创建PredictionEngine。PredictionEngine是一种方便的 API,可用于传入并针对单个数据实例执行预测。 - 若要访问单个
ModelInput实例,请使用CreateEnumerable方法将dataIDataView转换为IEnumerable,然后获取第一个观察结果。 - 使用
Predict方法对图像进行分类。 - 使用
OutputPrediction方法将预测输出到控制台。
- 在
在使用图像测试集调用
Fit方法后再调用ClassifySingleImage。ClassifySingleImage(mlContext, testSet, trainedModel);
对多个图像进行分类
创建一个名为
ClassifyImages的方法,用于生成和输出多个图像预测。static void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { IDataView predictionData = trainedModel.Transform(data); IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10); Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); } }ClassifyImages方法:- 使用
Transform方法创建包含预测的IDataView。 - 使用
CreateEnumerable方法将predictionDataIDataView转换为IEnumerable,以循环访问预测,然后获取前 10 个观察值。 - 循环访问并输出预测的原始标签和预测标签。
- 使用
在使用图像测试集调用
ClassifySingleImage()方法后再调用ClassifyImages。ClassifyImages(mlContext, testSet, trainedModel);
运行应用程序
运行控制台应用。 输出应类似于以下输出。
注意
你可能会看到警告或处理消息;为了清楚起见,这些消息已从以下结果中删除。 为了简洁起见,输出已简化。
瓶颈阶段
图像名称的值没有打印出来,因为图像作为 byte[] 被加载,因此没有可显示的图像名称。
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
训练阶段
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
对图像输出进行分类
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
检查 7001-220.jpg 图像后,可以验证它是否未破解,正如模型预测的那样。
用于预测 的
祝贺! 现已成功构建用于对图像进行分类的深度学习模型。
改进模型
如果对模型的结果不满意,可以尝试通过尝试以下一些方法来提高其性能:
- 更多数据:模型学习的示例越多,性能就越好。 下载完整的 SDNET2018 数据集 并将其用于训练。
- 增强数据:向数据添加多样性的常见技术是通过拍摄图像并应用不同的转换(旋转、翻转、移动、裁剪)来增强数据。 这将为模型添加更多不同的示例来学习。
- 训练时间较长:训练的时间越长,模型就越优化。 增加时期数可能会提高模型的性能。
- 试验超参数:除了本教程中使用的参数外,还可以优化其他参数以提高性能。 更改学习速率(确定每个时期后对模型进行的更新数量)可能会提高性能。
- 使用不同的模型体系结构:根据数据的外观,可以最好地了解其特征的模型可能会有所不同。 如果对模型的性能不满意,请尝试更改体系结构。
后续步骤
在本教程中,你学习了如何使用迁移学习、预先训练的图像分类 TensorFlow 模型及 ML.NET 图像分类 API,将混凝土表面的图像分类为裂缝或未裂缝。
请继续学习下一篇教程,了解详细信息。
另请参阅
- 示例:使用 ML.NET 和 TensorFlow 训练深度学习图像分类模型