分布式数据管理的挑战和解决方案

挑战 #1:如何定义每个微服务的边界
定义微服务边界可能是每位用户遇到的第一项挑战。 每个微服务必须是应用程序的一部分,并且每个微服务应对其带来的优势和挑战具有自治性。 但是,如何识别这些边界?
首先,需要着重关注应用程序的逻辑域模型和相关数据。 尝试识别同一应用程序中数据和不同上下文的分离岛。 每个上下文可能具有不同的业务语言(不同的业务术语)。 应独立定义和管理上下文。 不同上下文中所用的术语和实体可能听起来很相似,但你可能会发现在特定上下文中,用于一个目的的某个业务概念可在另一上下文中用于不同目的,甚至名称也可能会不同。 例如,用户在身份或成员身份上下文中称为用户,在 CRM 上下文中称为客户,在订购上下文中称为购买者等等。
多个应用程序上下文(各上下文具有不同域)之间的边界识别方法,也可用于识别各业务微服务及其相关域模型和数据的边界。 始终尝试最大程度减少这些微服务之间的耦合度。 本指南稍后将在识别每个微服务的域模型边界部分详细介绍此识别方法和域模型设计。
挑战 #2:如何创建从多个微服务中检索数据的查询
第二个挑战是如何实现从多个微服务中检索数据的查询,同时避免从远程客户端应用到微服务的闲聊通信。 例如,某个移动应用中需要显示属于购物篮、目录和用户标识微服务的用户信息的单个屏幕。 还例如,某个复杂报告涉及位于多个微服务中的表。 正确的解决方案取决于查询的复杂程度。 但在任何情况下,如果想要提高系统通信的效率,都需要通过某种方法来聚合信息。 最常用的解决方案如下。
API 网关。 对于来自多个微服务(拥有不同数据库)的简单数据聚合,推荐方法是称为 API 网关的聚合微服务。 但是,实现这种模式需谨慎,因为它可能成为系统中的瓶颈点,并可能违反微服务自治原则。 若要降低这种可能性,可以采用多个细粒度 API 网关,每个网关都着重于系统的垂直“切片”或业务区域。 API 网关模式稍后将在“API 网关”部分中详细介绍。
GraphQL 联合身份验证 如果微服务已在使用 GraphQL,不妨考虑选择 GraphQL 联合身份验证。 通过联合身份验证,可以定义其他服务的“子图”,并将其组合成可充当独立架构的聚合“超级图”。
具有查询/读取表的 CQRS。 用于聚合来自多个微服务的数据的另一个解决方案是具体化视图模式。 此方法将事先(在发生实际查询之前准备非规范化数据)生成一个包含属于多个微服务的数据的只读表。 该表采用满足客户端应用要求的格式。
考虑到移动应用屏幕等。 如果有单个数据库,则可以使用 SQL 查询(用于执行涉及多个表的复杂联接)将该屏幕的数据拉取在一起。 但是,如果有多个数据库,并且每个数据库都都属于不同微服务,则无法查询这些数据库和创建 SQL 联接。 此时,复杂查询则变成了一种挑战。 可以使用 CQRS 方法来满足需求,即在仅用于查询的不同数据库中创建非规范化表。 该表可专门针对复杂查询所需的数据进行设计,应用程序屏幕所需的字段和查询表中的列之间具有一对一关系。 该表还可用于报告。
这种方法不仅解决了原本的问题(如何跨微服务查询和联接),而且相比于复杂联接,它还显著提高了性能,因为你的查询表中已具有应用程序所需的数据。 当然,使用具有查询/读取表的命令和查询责任分离 (CQRS) 意味着需要完成额外的开发工作,并且需要达成最终一致性。 尽管如此,针对协作方案(或竞争方案,这取决于考虑角度)中性能和高可伸缩性的要求,应采用具有多个数据库的 CQRS。
中央数据库的“冷数据”。 对于可能不需要实时数据的复杂报告和查询,常用方法是将“热数据”(来自微服务的事务数据)作为“冷数据”导出到仅用于报告的大型数据库中。 该中央数据库系统可以是基于大数据的系统(如 Hadoop)、基于 Azure SQL 数据仓库的数据仓库,甚至是仅用于报告的单个 SQL 数据库(如果无大小方面的考量)。
请注意,此集中式数据库仅用于不需要实时数据的查询和报告。 作为事实来源的原始更新和事务必须位于微服务数据中。 用于同步数据的方法有两种:使用事件驱动的通信(将在后面部分介绍),或使用其他数据库基础结构导入/导出工具。 如果使用事件驱动通信,该集成进程与之前介绍的针对 CQRS 查询表传播数据的方法类似。
但是,如果应用程序设计需要不断聚合来自多个微服务的信息以进行复杂查询,那么这可能不是个好的设计:一个微服务应尽可能地与其他微服务分离。 (这不包括始终应使用冷数据中央数据库的报告/分析。)此问题通常可能是合并微服务的原因。 需要通过强大的依赖项、内聚和数据聚合在各微服务的发展自治和部署之间取得平衡。
挑战 #3:如何实现微服务之间的一致性
如前所述,每个微服务拥有的数据是该微服务专有的,并且只能通过其本身的微服务 API 访问。 因此,面临的挑战是如何在保持多个微服务的一致性的同时实现端到端的业务进程。
若要分析此问题,请先查看来自 eShopOnContainers 引用应用程序的示例。 目录微服务保存关于所有产品的信息,包括产品价格。 购物篮微服务管理有关用户添加到购物篮中的产品项的时态数据,其中包括产品项在添加到购物篮时的价格。 在目录中更新产品的价格后,还应在保存该相同产品的活动购物篮中更新该价格,且系统可能应当提醒用户,自他们将该特定产品项添加到购物篮以来,其价格已发生变化。
在此应用程序的假设单片版本中,当产品表中的价格发生变化时,目录子系统只需使用 ACID 事务即可更新购物篮表中的当前价格。
但是,在基于微服务的应用程序中,产品表和购物篮表属于其各自的微服务。 如图 4-9 所示,微服务不应在其自己的事务中包含属于另一微服务的表/存储,甚至在直接查询中也不能包含。
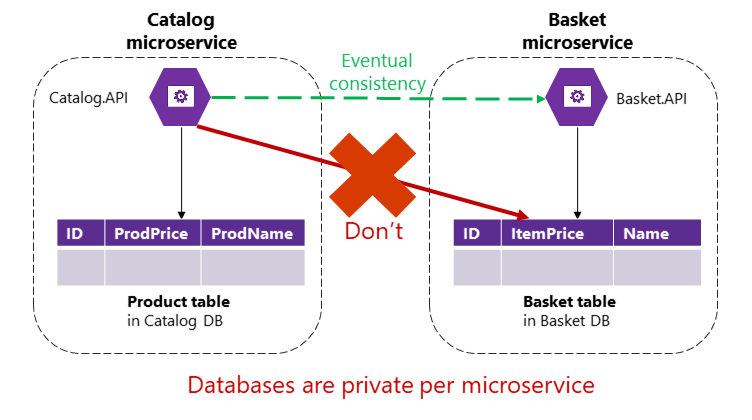
图 4-9. 微服务不能直接访问另一微服务中的表
目录微服务不应直接更新购物篮表,因为购物篮表属于购物篮微服务。 若要更新购物篮微服务,目录微服务可能应当基于异步通信(例如集成事件,即消息和基于事件的通信)使用最终一致性。 这是 eShopOnContainers 引用应用程序跨微服务执行此类一致性的方式。
如 CAP 定理所阐述的,需要选择可用性或 ACID 非常一致性。 大多数基于微服务的方案都需要可用性和高可伸缩性,而不是非常一致性。 任务关键应用程序必须保持最新并且处于运行状态,开发人员可通过用于处理弱或最终一致性的技术来实现非常一致性。 这是大多数基于微服务的体系结构采用的方法。
此外,ACID 式或两阶段提交事务不仅针对微服务原则;大多数 NoSQL 数据库(如 Azure Cosmos DB、MongoDB 等)不支持两阶段提交事务(在分布式数据库方案中十分常见)。 但是,维护服务和数据库的数据一致性至关重要。 此挑战还涉及,当某些数据需要冗余时(例如,需要在目录微服务和购物篮微服务中使用产品名称或说明时),如何在多个微服务之间传播更改。
针对此问题的一个良好解决方案是,在通过事件驱动通信和发布订阅系统形成的微服务之间使用最终一致性。 本指南后面的异步事件驱动通信部分将介绍这些主题。
挑战 #4:如何设计跨微服务边界的通信
跨微服务边界的通信是真正的挑战。 在此上下文中,通信不是指应使用何种协议(HTTP 和 REST、AMQP、消息等)。 相反,它解决了应使用何种通信方式的问题,尤其是应如何耦合微服务。 根据耦合的程度,在故障发生时,该故障对系统的影响将会有很大差异。
在分布式系统(如基于微服务的应用程序)中,由于许多项目不断移动并且许多服务器或主机之间存在分布式服务,因此组件最终将失败。 这可能导致部分故障甚至更大规模的中断,因此需要在设计微服务和跨微服务的通信时,考虑此类分布式系统中的常见风险。
常用方法是实现基于 HTTP (REST) 的微服务,因为该服务具有简便性。 基于 HTTP 的方法是完全可以接受的;这里存在的问题与其使用方法有关。 如果使用 HTTP 请求和响应只是为了与来自客户端应用程序或 API 网关的微服务进行交互,这是可行的。 但如果创建跨微服务的长链同步 HTTP 调用,就好像微服务是单片应用程序中的对象一样进行跨边界通信,则应用程序最终会遇到问题。
例如,假设客户端应用程序对单个微服务(如订购微服务)进行 HTTP API 调用。 如果订购微服务在相同的请求/响应周期内转而使用 HTTP 调用其他微服务,则表示正在创建 HTTP 调用链。 刚开始时,这可能听起来很合理。 但是,如果继续进行,则需要考虑一些重要问题:
阻止和低降低。 由于 HTTP 的同步性质,直到所有内部 HTTP 调用完成后,原始请求才会收到响应。 假设这些调用的数量显著增加,同时某个对微服务的中间 HTTP 调用受到阻止。 这会对性能造成影响,并且随着其他 HTTP 请求的增加,整体可伸缩性将受到的影响将成倍增长。
将微服务与 HTTP 耦合。 业务微服务不应与其他业务微服务耦合。 理想情况下,它们不应“知道”其他微服务的存在。 如果应用程序依赖于如例所示的耦合微服务,那么几乎不可能实现每个微服务的自治。
任一微服务中的失败。 如果实现由 HTTP 调用链接的微服务链,那么任一微服务失败(最终所有微服务都将失败)都将导致整个微服务链的失败。 基于微服务的系统应设计为在部分故障期间也尽可能地继续工作。 即使通过指数退避或断路器机制实现使用重试的客户端逻辑,HTTP 调用链越复杂,实现基于 HTTP 的故障策略也会越复杂。
事实上,如果内部微服务如前文所述通过创建 HTTP 请求链进行通信,那么可能会认为你拥有一个单片应用程序,但是它基于进程之间的 HTTP,而不是进程间的通信机制。
因此,为强化微服务自治并且提升复原能力,应尽可能少地使用跨微服务的请求/响应通信链。 建议只使用异步交互进行微服务之间的通信,方法是使用基于消息和基于事件的异步通信,或(异步)使用独立于原始 HTTP 请求/响应周期的 HTTP 轮询。
异步通信的使用稍后将在本指南的异步微服务集成强化微服务的自治性和基于消息的异步通信部分详细介绍。
其他资源
The CAP Theorem(CAP 定理)
https://en.wikipedia.org/wiki/CAP_theorem数据一致性入门
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler。 CQRS(命令和查询责任分离)
https://martinfowler.com/bliki/CQRS.html具体化视图
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID 与 BASE:数据库事务处理不断变化的 pH
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/补偿事务
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. 面向服务的组合
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/