你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
查询 CSV 文件
在本文中,你将学习如何使用 Azure Synapse Analytics 中的无服务器 SQL 池来查询单个 CSV 文件。 CSV 文件可有多种不同的格式:
- 带有或不带标题行
- 逗号和制表符分隔的值
- Windows 和 Unix 样式行尾
- 不带引号和带引号的值,以及转义字符
上述所有类型都将在下文中进行介绍。
快速入门示例
OPENROWSET 函数使你能够通过提供文件的 URL 来读取 CSV 文件的内容。
读取 csv 文件
查看 CSV 文件内容的最简单方法是向 OPENROWSET 函数提供文件 URL,指定 csv FORMAT 和 2.0 PARSER_VERSION。 如果该文件可公开查看,或者你的 Microsoft Entra 标识有权访问该文件,则你应该可以使用类似于以下示例所示查询的查询来查看该文件的内容:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
选项 firstrow 用于跳过 CSV 文件的第一行(在本例中表示标头)。 请确保你可以访问此文件。 如果文件受到 SAS 密钥或自定义标识的保护,则你需要为 SQL 登录设置服务器级别的凭据。
重要
如果 CSV 文件包含 UTF-8 字符,请确保使用 UTF-8 数据库排序规则(例如 Latin1_General_100_CI_AS_SC_UTF8)。
文件中的文本编码和排序规则不匹配可能会导致意外的转换错误。
可以使用 T-SQL 语句 alter database current collate Latin1_General_100_CI_AI_SC_UTF8 轻松地更改当前数据库的默认排序规则
数据源使用情况
上面的示例使用文件的完整路径。 作为替代方法,你可以创建一个外部数据源,其中包含指向存储根文件夹的位置:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
创建数据源后,可以在 OPENROWSET 函数中使用该数据源和文件的相对路径:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
如果数据源受到 SAS 密钥或自定义标识的保护,则你可以使用数据库范围的凭据配置数据源。
显式指定架构
OPENROWSET 使你能够使用 WITH 子句显式指定要从文件中读取的列:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
WITH 子句中的数据类型后的数字表示 CSV 文件中的列索引。
重要
如果 CSV 文件包含 UTF-8 字符,请确保为 WITH 子句中的所有列显式指定一些 UTF-8 排序规则(例如 Latin1_General_100_CI_AS_SC_UTF8),或在数据库级别设置一些 UTF-8 排序规则。
文件中的文本编码和排序规则不匹配可能会导致意外的转换错误。
可以使用 T-SQL 语句 轻松地更改当前数据库的默认排序规则alter database current collate Latin1_General_100_CI_AI_SC_UTF8 可以使用以下定义轻松设置列类型的排序规则:geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
以下部分介绍如何查询各种类型的 CSV 文件。
先决条件
第一步是创建将在其中创建表的数据库。 然后通过对该数据库执行安装脚本来初始化这些对象。 此安装脚本将创建数据源、数据库范围的凭据以及在这些示例中使用的外部文件格式。
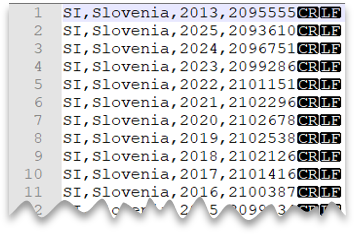
Windows 样式换行符
以下查询展示了如何读取不包含标题行、包含 Windows 样式换行符和逗号分隔列的 CSV 文件。
文件预览:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
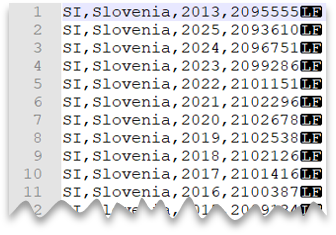
Unix 样式换行符
以下查询展示了如何读取不包含标题行、包含 Unix 样式换行符和逗号分隔列的文件。 请注意文件位置,相较其他示例中有何不同。
文件预览:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
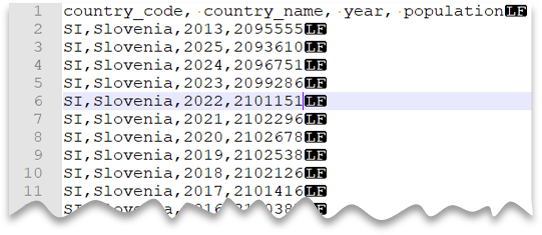
标题行
以下查询展示了如何读取带标题行、带 Unix 样式换行符和逗号分隔列的文件。 请注意文件位置,相较其他示例中有何不同。
文件预览:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
HEADER_ROW = TRUE 选项将导致从文件的标题行读取列名。 当你不熟悉文件内容时,非常适合使用它进行浏览。 为获得最佳性能,请参阅最佳做法中的“使用适当的数据类型”部分。 此外,还可以详细了解 OPENROWSET 语法。
自定义引证字符
以下查询展示了如何读取包含标题行、包含 Unix 样式换行符、逗号分隔列和引证值的文件。 请注意文件位置,相较其他示例中有何不同。
文件预览:

SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
注意
如果省略 FIELDQUOTE 参数,此查询会返回相同的结果,因为 FIELDQUOTE 的默认值是双引号。
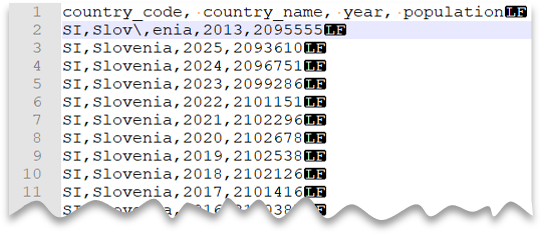
转义字符
以下查询展示了如何读取包含标题行、包含 Unix 样式换行符、逗号分隔列和用于值内字段分隔符(逗号)的转义字符的文件。 请注意文件位置,相较其他示例中有何不同。
文件预览:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
注意
如果未指定 ESCAPECHAR,此查询将失败,因为 "Slov,enia" 中的逗号将被视为字段分隔符,而不是国家/地区名称的一部分。 "Slov,enia" 将被视为两个列。 因此,该特定行将比其他行多一列,并且比 WITH 子句中定义的列数多一列。
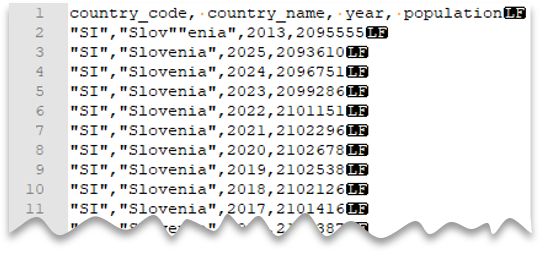
转义引号字符
以下查询展示了如何读取包含标题行、包含 Unix 样式换行符、逗号分隔列和值内转义双引号字符的文件。 请注意文件位置,相较其他示例中有何不同。
文件预览:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
注意
必须使用其他引号字符来转义引号字符。 要让引号字符出现在列值内,必须将值放在引号中。
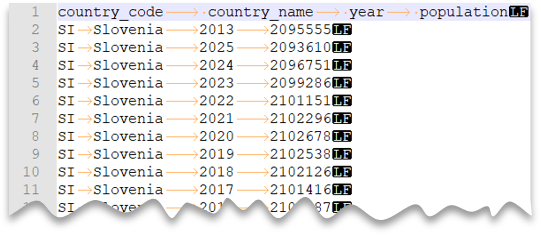
制表符分隔的文件
以下查询展示了如何读取包含标题行、包含 Unix 样式换行符和制表符分隔列的文件。 请注意文件位置,相较其他示例中有何不同。
文件预览:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
返回列的子集
到目前为止,已通过使用 WITH 和列出所有列来指定了 CSV 文件架构。 可以通过对所需的每个列使用序号来仅指定查询中实际要用的列。 这样将忽略不需要使用的列。
下面的查询返回文件中不同国家/地区名称的数量,并且仅指定所需的列:
注意
在下面的查询中查看 WITH 子句,并注意,定义了 [country_name] 列的行的末尾处带有“2”(不带引号)。 这意味着 [country_name] 列是文件中的第二列。 查询将忽略文件中除第二个列以外的所有列。
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
查询可追加文件
查询运行时,不应更改查询中使用的 CSV 文件。 在长时间运行的查询中,SQL 池可能会重试读取、读取部分文件,甚至多次读取文件。 如果对文件内容进行更改,会导致错误的结果。 因此,如果在查询执行过程中检测到任何文件的修改时间发生了更改,SQL 池将导致查询失败。
在某些情况下,建议读取不断追加的文件。 为避免由于不断追加文件而导致查询失败,可以使用 ROWSET_OPTIONS 设置让 OPENROWSET 函数能忽略潜在的不一致读取操作。
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
ALLOW_INCONSISTENT_READS 读取选项将禁用查询生命周期期间的文件修改时间检查,并读取文件中的任何可用内容。 在可追加文件中,不更新现有内容,仅添加新行。 因此,与可更新文件相比,这样做生成错误结果的可能性最低。 使用此选项,可以在不处理错误的情况下读取经常追加的文件。 在大多数情况下,SQL 池将忽略查询执行期间追加到文件中的某些行。
后续步骤
后续文章将介绍如何: