本教程使用 Azure 机器学习设计器构建预测性机器学习模型。 该模型基于 Azure Synapse 中存储的数据。 本教程的场景是预测客户是否有可能购买自行车,这样自行车店 Adventure Works 就可以策划一个针对性的营销活动。
先决条件
要逐步完成本教程,需要以下各项:
- 随 AdventureWorksDW 示例数据预先加载的 SQL 池。 若要预配此 SQL 池,请参阅创建 SQL 池并选择加载示例数据。 如果你已有数据仓库但没有示例数据,则可手动加载示例数据。
- 一个 Azure 机器学习工作区。 按照此教程创建一个新工作区。
获取数据
所用数据位于 AdventureWorksDW 的 dbo.vTargetMail 视图中。 为了在本教程中使用数据存储,需要先将数据导出到 Azure Data Lake Storage 帐户,因为 Azure Synapse 当前不支持数据集。 可以通过 Azure 数据工厂使用复制活动将数据从数据仓库导出到 Azure Data Lake Storage。 使用以下查询进行导入:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
当数据在 Azure Data Lake Storage 中可用后,使用 Azure 机器学习中的数据存储连接到 Azure 存储服务。 按照以下步骤创建数据存储和相应的数据集:
从 Azure 门户启动 Azure 机器学习工作室或从 Azure 机器学习工作室登录。
在“管理”部分的左窗格中单击“数据存储”,然后单击“新建数据存储”。
为数据存储提供一个名称,选择“Azure Blob 存储”作为类型,提供位置和凭据。 然后单击“创建” 。
接下来,在“资产”部分的左窗格中单击“数据集”。 选择“创建数据集”,并使用选项“从数据存储”。
指定数据集的名称,并选择“表格”作为类型。 然后,单击“下一步”继续操作。
在“选择或创建数据集”部分,选择“以前创建的数据存储”选项。 选择之前创建的数据存储。 单击“下一步”并指定路径和文件设置。 如果文件包含列标题,请确保指定列标题。
最后,单击“创建”以创建数据集。
配置设计器试验
接下来,按照以下步骤进行设计器配置:
单击“创作”部分的左窗格中的“设计器”选项卡。
选择“易用的预生成组件”以生成新管道。
在右侧的设置窗格中,指定管道的名称。
另外,请使用设置按钮选择以前预配的群集作为整个试验的目标计算群集。 关闭“设置”窗格。
导入数据
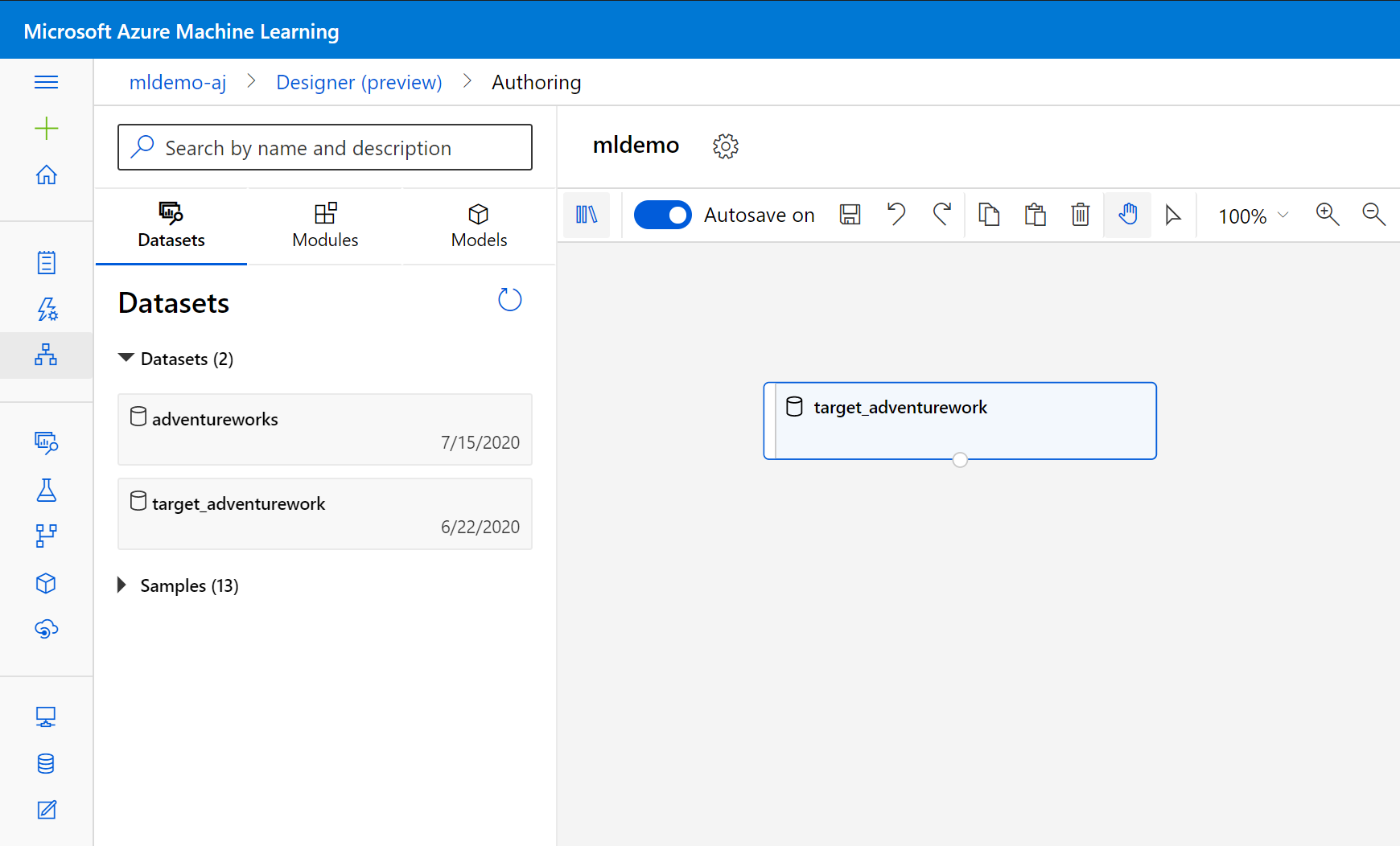
在搜索框下的左窗格中选择“数据集”子选项卡。
将之前创建的数据集拖动到画布中。
清理数据
若要清理数据,请删除与模型无关的列。 请遵循以下步骤进行配置:
在左窗格中选择“组件”子选项卡。
将“数据转换”<“操作”下的“选择数据集中的列”组件拖放到画布中。 将此组件连接到“数据集”组件。
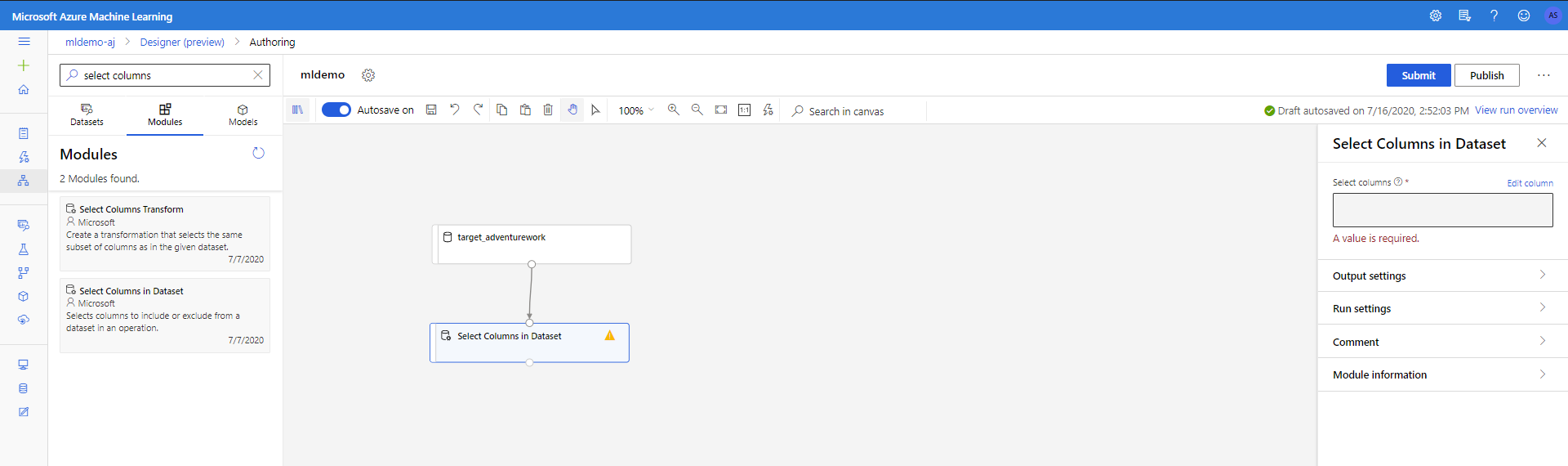
单击组件以打开“属性”窗格。 单击“编辑”列以指定要删除哪些列。
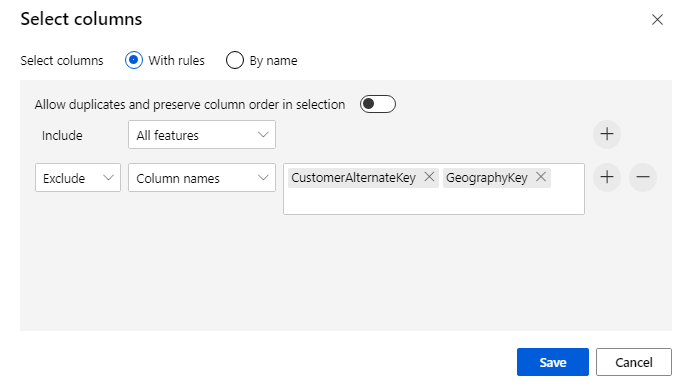
排除两个列:CustomerAlternateKey 和 GeographyKey。 单击“保存”

构建模型
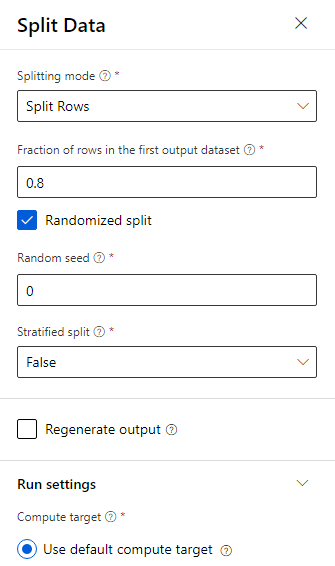
数据按 80-20 的比例进行拆分:80% 用于训练机器学习模型,20% 用于测试该模型。 此二元分类问题中使用了“双类”算法。
将“拆分数据”组件拖到画布中。
在属性窗格中,为“第一个输出数据集中的行的比例”输入 0.8。
将“双类提升决策树”组件拖放到画布中。
将“训练模型”组件拖到画布中。 通过将该组件连接到“双类提升决策树”(ML 算法)组件和“拆分数据”(训练算法时基于的数据)组件来指定输入 。
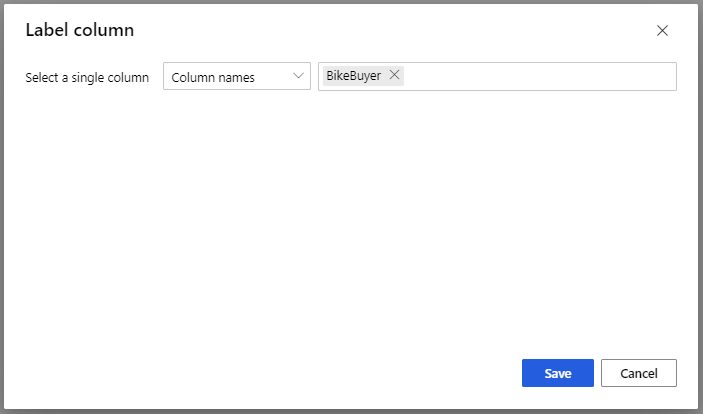
对于“训练模型”模块,请在“属性”窗格的“标签列”选项中选择“编辑列”。 选择“BikeBuyer”列作为要预测的列,然后选择“保存”。
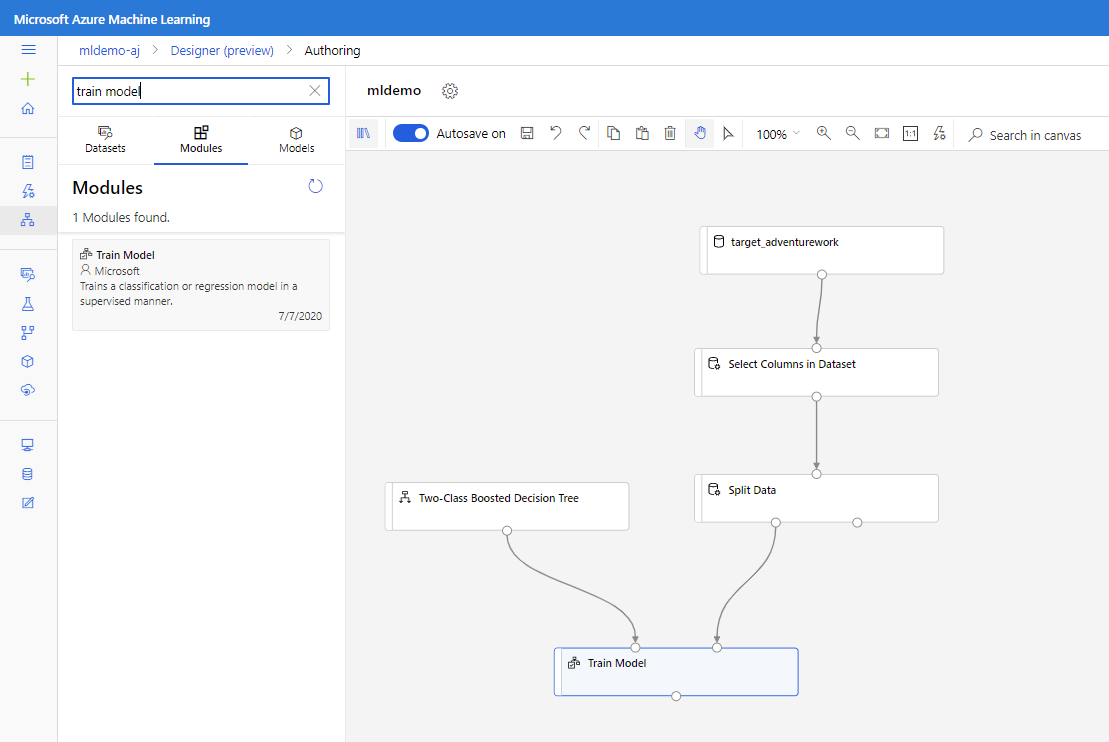
为模型评分
现在,测试模型在使用测试数据时表现如何。 将比较两个不同的算法,看哪一个算法的表现更佳。 请遵循以下步骤进行配置:
将“评分模型”组件拖放到画布中,并将其连接到“训练模型”和“拆分模型”组件 。
将“双类贝叶斯平均感知器”拖到试验画布中。 我们将比较此算法与双类提升决策树的表现。
复制“训练模型”和“评分模型”组件并将其粘贴在画布中。
将“评估模型”组件拖放到画布以比较两种算法。
单击“提交”以设置管道运行。
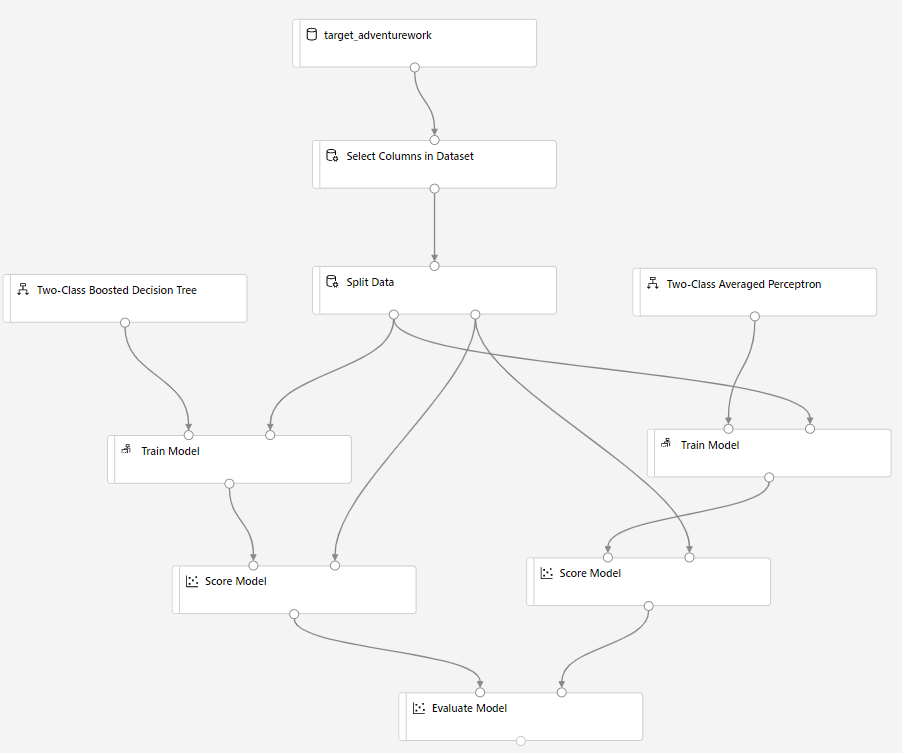
运行完成后,右键单击“评估模型”组件,并单击“可视化评估结果”。
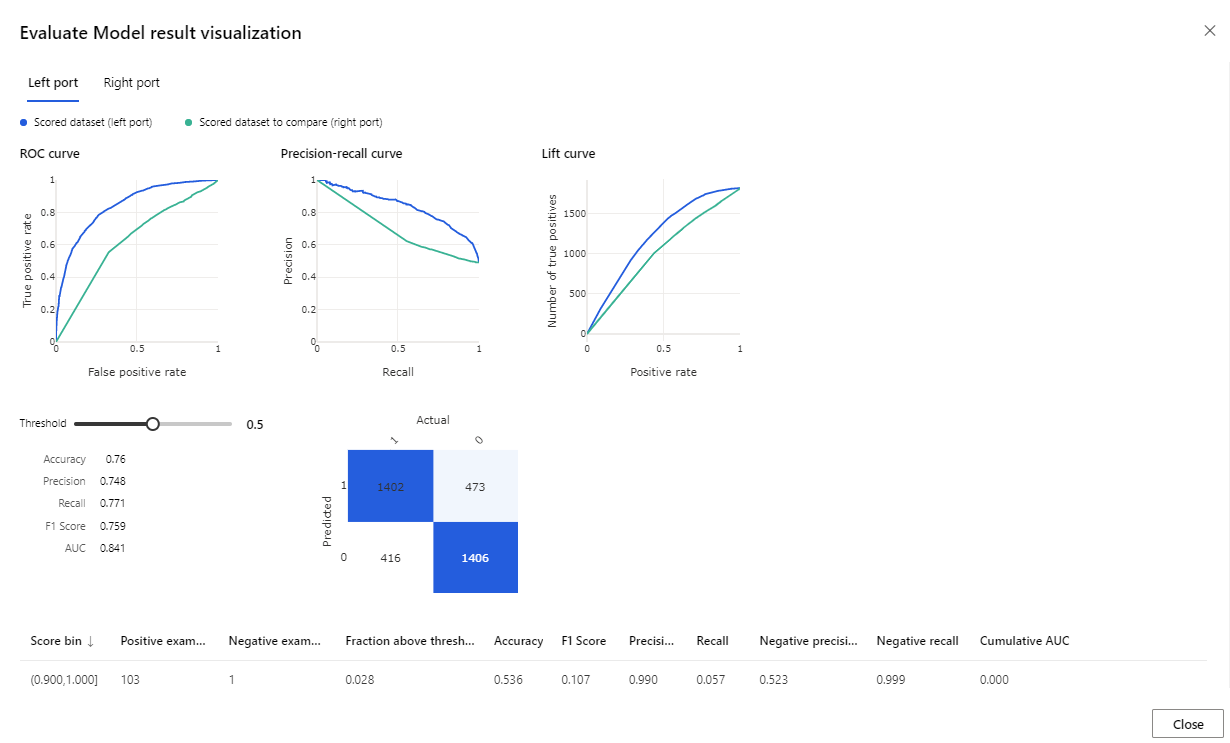

提供的指标包括 ROC 曲线、精度和召回率示意图以及提升曲线。 查看这些指标,可以看到第一个模型的表现优于第二个。 若要查看第一个模型的预测结果,请右键单击“评分模型”组件,并单击“可视化评分的数据集”以查看预测的结果。
你会看到另外两个列已添加到测试数据集。
- 评分概率:客户购买自行车的可能性。
- 评分标签:模型执行的分类 – 自行车的购买者 (1) 或不是购买者 (0)。 标签的概率阈值设置为 50%,并可以调整。
将“BikeBuyer”列(实际列)与“评分标签”列(预测列)进行比较,以查看模型的表现。 接下来,你可以使用此模型针对新客户进行预测。 你可以将此模型发布为 Web 服务或将结果写回 Azure Synapse。
后续步骤
若要详细了解 Azure 机器学习,请参阅 Azure 上的机器学习简介。
若要了解数据仓库中的内置评分,请参阅此文。