打开 Synapse Studio,转到左侧的“管理”>“链接服务”,单击“新建”以创建新的链接服务。
选择“Azure Database for MySQL”,单击“继续”。
提供链接服务的名称。 记录链接服务的名称,此信息将很快用于配置 Spark。
可以从 Azure 订阅列表中为外部 Hive 元存储选择 Azure Database for MySQL,也可以手动输入信息。
提供“用户名”和“密码”以设置连接。
测试连接以验证用户名和密码。
单击“创建”以创建链接服务。
某些网络安全规则设置可能会阻止从 Spark 池访问外部 Hive 元存储数据库。 在配置 Spark 池之前,在任何 Spark 池笔记本中运行以下代码,测试与外部 Hive 元存储数据库的连接。
此外,还可以从输出结果中获取 Hive 元存储版本。 Hive 元存储版本将用于 Spark 配置。
警告
不要在笔记本中发布包含硬编码密码的测试脚本,因为这可能会给你的 Hive Metastore 带来潜在的安全风险。
Azure SQL 的连接测试代码
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure SQL database > Connection strings > JDBC **/
val url = s"jdbc:sqlserver://{your_servername_here}.database.windows.net:1433;database={your_database_here};user={your_username_here};password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
try {
val connection = DriverManager.getConnection(url)
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
Azure Database for MySQL 的连接测试代码
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure Database for MySQL > Connection strings > JDBC **/
val url = s"jdbc:mysql://{your_servername_here}.mysql.database.azure.com:3306/{your_database_here}?useSSL=true"
try {
val connection = DriverManager.getConnection(url, "{your_username_here}", "{your_password_here}");
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
成功创建到外部 Hive 元存储的链接服务后,需要设置一些 Spark 配置,以使用外部 Hive 元存储。 可以在 Spark 池级别或 Spark 会话级别设置配置。
下面是配置和说明:
注意
Synapse 旨在顺利使用 HDI 中的计算。 但是,HDI 4.0 中的 HMS 3.1 与 OSS HMS 3.1 并不完全兼容。 有关 OSS HMS 3.1 的信息,请查看此处。
| Spark 配置 |
说明 |
spark.sql.hive.metastore.version |
支持的版本: 确保使用前 2 个部分,而不使用第 3 部分 |
spark.sql.hive.metastore.jars |
- 版本 2.3:
/opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/* - 版本 3.1:
/opt/hive-metastore/lib-3.1/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/*
|
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name |
链接服务的名称 |
spark.sql.hive.metastore.sharedPrefixes |
com.mysql.jdbc,com.microsoft.vegas |
创建 Spark 池时,在“其他设置”选项卡下,将以下配置放入文本文件中,然后将其上传到“Apache Spark 配置”部分。 还可以使用现有 Spark 池的上下文菜单,选择“Apache Spark 配置”以添加这些配置。
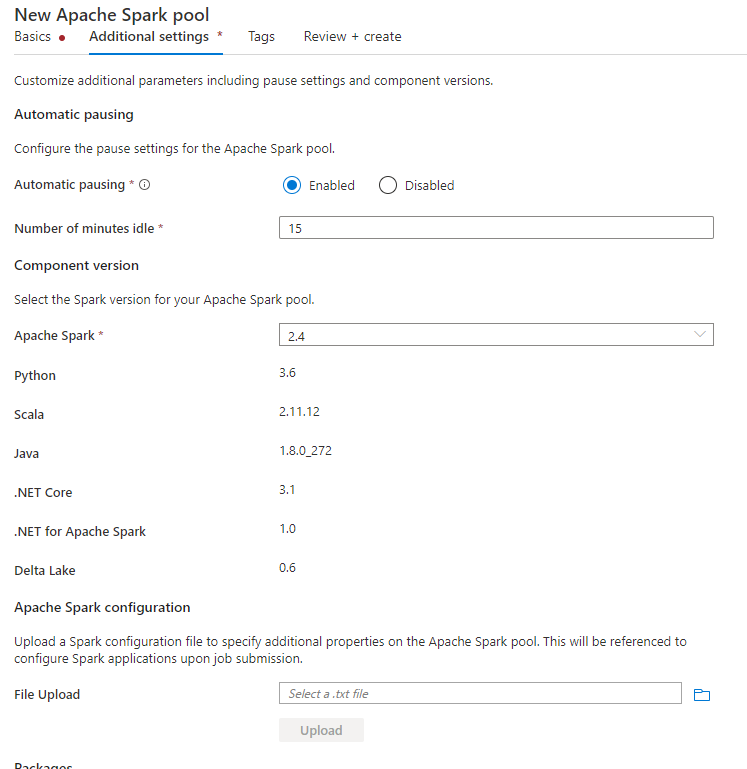
更新元存储版本和链接服务名称,并将以下配置保存在文本文件中以用于 Spark 池配置:
spark.sql.hive.metastore.version <your hms version, Make sure you use the first 2 parts without the 3rd part>
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name <your linked service name>
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.vegas
以下是元存储版本 2.3 的示例,其中链接服务名为 HiveCatalog21:
spark.sql.hive.metastore.version 2.3
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name HiveCatalog21
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.vegas
对于笔记本会话,还可使用 %%configure magic 命令在笔记本中配置 Spark 会话。 代码如下。
%%configure -f
{
"conf":{
"spark.sql.hive.metastore.version":"<your hms version, 2 parts>",
"spark.hadoop.hive.synapse.externalmetastore.linkedservice.name":"<your linked service name>",
"spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*",
"spark.sql.hive.metastore.sharedPrefixes":"com.mysql.jdbc,com.microsoft.vegas"
}
}
对于批处理作业,也可以通过 SparkConf 应用相同的配置。
运行查询以验证连接
完成所有这些设置后,尝试在 Spark 笔记本中运行以下查询来列出目录对象,以检查与外部 Hive 元存储的连接。
spark.sql("show databases").show()
设置存储连接
到 Hive 元存储数据库的链接服务仅提供对 Hive 目录元数据的访问。 要查询现有表,还需要设置与存储 Hive 表的基础数据的存储帐户的连接。
设置到 Azure Data Lake Storage Gen2 的连接
工作区主存储帐户
如果 Hive 表的基础数据存储在工作区主存储帐户中,则无需进行额外的设置。 只要你在工作区创建过程中遵循存储设置说明,它就会正常工作。
其他 ADLS Gen 2 帐户
如果 Hive 目录的基础数据是存储在另一个 ADLS Gen 2 帐户中,则需要确保运行 Spark 查询的用户在 ADLS Gen2 存储帐户上具有“存储 Blob 数据参与者”角色。
设置与 Blob 存储的连接
如果 Hive 表的基础数据是存储在 Azure Blob 存储帐户中,请按照以下步骤设置连接:
打开 Synapse Studio,转到“数据”>“链接”选项卡 >“添加”按钮>“连接到外部数据”。
选择“Azure Blob 存储”,然后选择“继续”。
提供链接服务的名称。 记录链接服务的名称,此信息将很快用于 Spark 配置。
选择 Azure Blob 存储帐户。 确保身份验证方法是“帐户密钥”。 目前,Spark 池只能通过帐户密钥访问 Blob 存储帐户。
测试连接并选择“创建”。
创建到 Blob 存储帐户的链接服务后,当你运行 Spark 查询时,请确保在笔记本中运行以下 Spark 代码,以获取对 Spark 会话的 Blob 存储帐户的访问权限。 若要详细了解需要这样做的原因,请参阅此处。
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
设置存储连接后,可以查询 Hive 元存储中的现有表。
已知的限制
- Synapse Studio 对象资源管理器将继续显示托管的 Synapse 元存储(而不是外部 HMS)中的对象。
- 使用外部 HMS 时,SQL <-> Spark 同步不起作用。
- 仅支持 Azure SQL 数据库和 Azure Database for MySQL 作为外部 Hive 元存储数据库。 仅支持 SQL 身份验证。
- 目前,Spark 只适用于外部 Hive 表和非事务/非 ACID 托管的 Hive 表。 它不支持 Hive ACID/事务表。
- 不支持 Apache Ranger 集成。
疑难解答
使用存储在 Blob 存储中的数据查询 Hive 表时,看到以下错误
No credentials found for account xxxxx.blob.core.windows.net in the configuration, and its container xxxxx is not accessible using anonymous credentials. Please check if the container exists first. If it is not publicly available, you have to provide account credentials.
通过链接服务对存储帐户使用密钥身份验证时,需要执行额外的步骤来获取 Spark 会话的令牌。 在运行查询之前,运行以下代码来配置 Spark 会话。 在此处详细了解需要这样做的原因。
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
查询存储在 ADLS Gen2 帐户中的表时,看到以下错误
Operation failed: "This request is not authorized to perform this operation using this permission.", 403, HEAD
这可能是因为运行 Spark 查询的用户没有足够的权限来访问基础存储帐户。 确保运行 Spark 查询的用户在 ADLS Gen2 存储帐户中具有“存储 Blob 数据参与者”角色。 这一步可以在创建链接服务后完成。
为了避免更改 HMS 后端架构/版本,系统默认设置以下 Hive 配置:
spark.hadoop.hive.metastore.schema.verification true
spark.hadoop.hive.metastore.schema.verification.record.version false
spark.hadoop.datanucleus.fixedDatastore true
spark.hadoop.datanucleus.schema.autoCreateAll false
如果 HMS 版本为 1.2.1 或 1.2.2,则 Hive 中会出现一个问题,在将 spark.hadoop.hive.metastore.schema.verification 变成 true 时会指出只需要 1.2.0。 我们的建议是,可以将 HMS 版本修改为 1.2.0,或者通过覆盖以下两个配置来解决问题:
spark.hadoop.hive.metastore.schema.verification false
spark.hadoop.hive.synapse.externalmetastore.schema.usedefault false
如果需要迁移 HMS 版本,建议使用 Hive 架构工具。 如果 HMS 已经被 HDInsight 集群使用,那么我们建议使用 HDI 提供的版本。
OSS HMS 3.1 的 HMS 架构更改
Synapse 旨在顺利使用 HDI 中的计算。 但是,HDI 4.0 中的 HMS 3.1 与 OSS HMS 3.1 并不完全兼容。 如果 HDI 未预配,请手动将以下内容应用到 HMS 3.1。
-- HIVE-19416
ALTER TABLE TBLS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
ALTER TABLE PARTITIONS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
如果要与 HDInsight 4.0 中的 Spark 群集共享 Hive 目录,请确保 Synapse Spark 中的属性 spark.hadoop.metastore.catalog.default 与 HDInsight Spark 中的值一致。 HDI Spark 的默认值为 spark,Synapse Spark 的默认值为 hive。
如限制中所述,Synapse Spark 池只支持外部 Hive 表和非事务/ACID 托管表,它目前不支持 Hive ACID/事务表。 在 HDInsight 4.0 Hive 群集中,所有托管表都默认被创建为 ACID/事务表,这就是你在查询这些表时获得空结果的原因。
java.lang.ClassNotFoundException: Class com.microsoft.vegas.vfs.SecureVegasFileSystem not found
可以通过将 /usr/hdp/current/hadoop-client/* 追加到 spark.sql.hive.metastore.jars 来轻松修复此问题。
Eg:
spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/*