你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Teradata 迁移的安全性、访问和操作
本文是一个包含七部分的系列教程的第三部分,提供有关如何从 Teradata 迁移到 Azure Synapse Analytics 的指导。 本文重点介绍安全访问操作的最佳做法。
安全注意事项
本文介绍现有旧式 Teradata 环境的连接方法,以及如何以最低的风险、在对用户造成最小影响的情况下将这些连接方法迁移到 Azure Synapse Analytics。
本文假设必须按原样迁移现有连接方法以及用户/角色/权限结构。 如果没有,请使用 Azure 门户创建和管理新的安全体系。
有关 Azure Synapse 安全选项的详细信息,请参阅安全白皮书。
连接和身份验证
Teradata 授权选项
提示
Teradata 和 Azure Synapse 中的身份验证都可以“在数据库中”进行,或通过外部方法进行。
Teradata 支持多种连接和授权机制。 有效的机制值为:
TD1:选择 Teradata 1 作为身份验证机制。 必须指定用户名和密码。
TD2:选择 Teradata 2 作为身份验证机制。 必须指定用户名和密码。
TDNEGO:根据策略自动选择一种身份验证机制,无需用户参与。
LDAP:选择轻型目录访问协议 (LDAP) 作为身份验证机制。 应用程序将提供用户名和密码。
KRB5:在使用 Windows 服务器的 Windows 客户端上选择 Kerberos (KRB5)。 若要使用 KRB5 登录,用户需要提供域、用户名和密码。 通过将用户名设置为
MyUserName@MyDomain来指定域。NTLM:在使用 Windows 服务器的 Windows 客户端上选择 NTLM。 应用程序将提供用户名和密码。
Kerberos (KRB5)、Kerberos 兼容性 (KRB5C)、NT LAN Manager (NTLM) 和 NT LAN Manager 兼容性 (NTLMC) 仅适用于 Windows。
Azure Synapse 授权选项
Azure Synapse 支持两个基本连接和授权选项:
SQL 身份验证:SQL 身份验证通过包括数据库标识符、用户 ID 和密码以及其他可选参数的数据库连接进行。 这在功能上等同于 Teradata TD1、TD2 和默认连接。
Microsoft Entra 身份验证:通过 Microsoft Entra 身份验证,可以在一个位置集中管理数据库用户和其他 Microsoft 服务的标识。 集中 ID 管理提供单一位置用于管理 SQL 数据仓库用户,并简化权限管理。 Microsoft Entra ID 还支持连接到 LDAP 和 Kerberos 服务 – 例如,如果要在迁移数据库后保留现有的 LDAP 目录,可以使用 Microsoft Entra ID 连接到这些目录。
用户、角色和权限
概述
提示
全方位的规划对于成功完成迁移项目至关重要。
Teradata 和 Azure Synapse 都通过用户、角色和权限的组合来实现数据库访问控制。 两者都使用标准 SQL CREATE USER 和 CREATE ROLE 语句来定义用户和角色,使用 GRANT 和 REVOKE 语句来为这些用户和/或角色分配或删除权限。
提示
建议将迁移过程自动化,以减少使用的时间和错误范围。
从概念上讲,这两个数据库是相似的,现有用户 ID、角色和权限的迁移可以在一定程度上自动化。 此类数据的迁移方式是从 Teradata 系统目录表中提取现有的旧用户和角色信息,并生成要在 Azure Synapse 中运行的匹配等效 CREATE USER 和 CREATE ROLE 语句,以重新创建相同的用户/角色层次结构。
提取数据后,使用 Teradata 系统目录表生成等效的 GRANT 语句以分配权限(如果存在等效的权限)。 下图显示了如何使用现有元数据生成所需的 SQL。
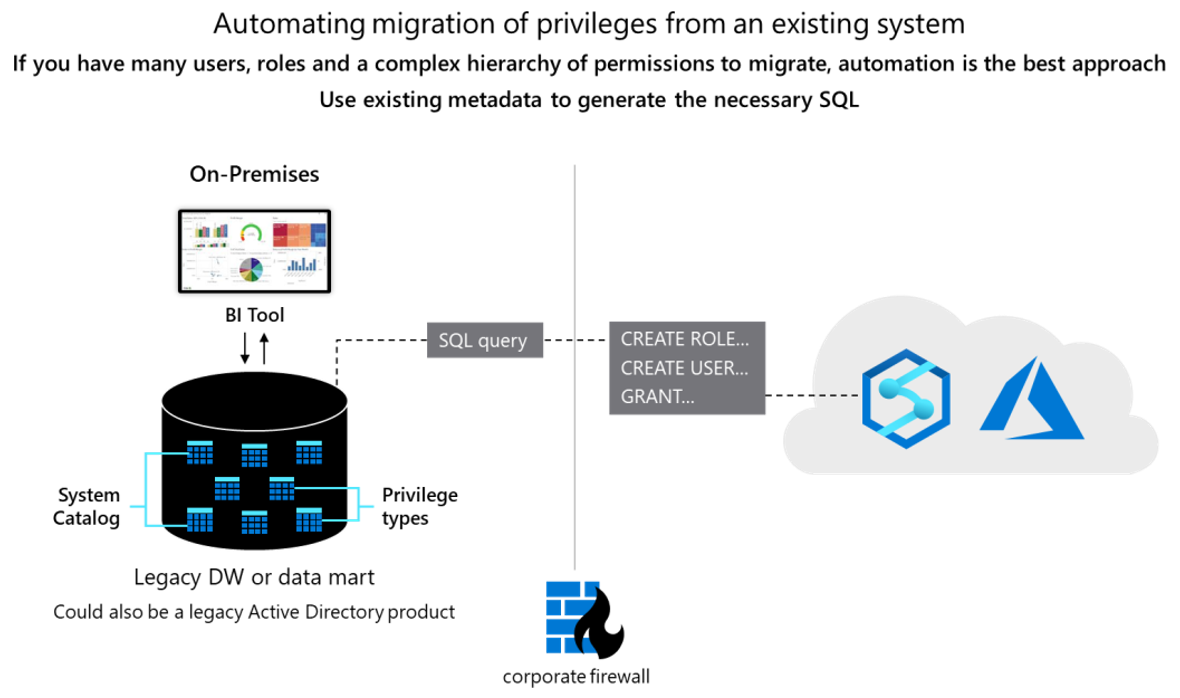
用户和角色
提示
迁移数据仓库不仅需要表、视图和 SQL 语句。
可以在系统目录表 DBC.USERS(或 DBC.DATABASES)和 DBC.ROLEMEMBERS 中找到有关 Teradata 系统中当前用户和角色的信息。 查询这些表(如果用户对这些表拥有 SELECT 访问权限)以获取系统中当前定义的用户和角色列表。 下面是用于对单个用户执行此操作的查询示例:
/***SQL to find all users***/
SELECT
DatabaseName AS UserName
FROM DBC.Databases
WHERE dbkind = 'u';
/***SQL to find all roles***/
SELECT A.ROLENAME, A.GRANTEE, A.GRANTOR,
A.DefaultRole,
A.WithAdmin,
B.DATABASENAME,
B.TABLENAME,
B.COLUMNNAME,
B.GRANTORNAME,
B.AccessRight
FROM DBC.ROLEMEMBERS A
JOIN DBC.ALLROLERIGHTS B
ON A.ROLENAME = B.ROLENAME
GROUP BY 1,2,3,4,5,6,7
ORDER BY 2,1,6;
这些示例通过在 SELECT 语句中包含相应的文本作为字面量来修改 SELECT 语句以生成一个结果集,该结果集是一系列 CREATE USER 和 CREATE ROLE 语句。
无法检索现有密码,因此需要实现一种方案以在 Azure Synapse 上分配新的初始密码。
权限
提示
基本数据库操作(例如 DML 和 DDL)具有等效的 Azure Synapse 权限。
在 Teradata 系统中,系统表 DBC.ALLRIGHTS 和 DBC.ALLROLERIGHTS 保留用户和角色的访问权限。 查询这些表(如果用户对这些表拥有 SELECT 访问权限)以获取系统中当前定义的访问权限列表。 下面是针对单个用户的查询示例:
/**SQL for AccessRights held by a USER***/
SELECT UserName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantAuthority, GrantorName, AllnessFlag, CreatorName, CreateTimeStamp
FROM DBC.ALLRIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE UserName='UserXYZ'
Order By 2,3,4,5;
/**SQL for AccessRights held by a ROLE***/
SELECT RoleName, DatabaseName,TableName,ColumnName,
CASE WHEN Abbv.AccessRight IS NOT NULL THEN Abbv.Description ELSE
ALRTS.AccessRight
END AS AccessRight, GrantorName, CreateTimeStamp
FROM DBC.ALLROLERIGHTS ALRTS LEFT OUTER JOIN AccessRightsAbbv
Abbv
ON ALRTS.AccessRight = Abbv.AccessRight
WHERE RoleName='BI_DEVELOPER'
Order By 2,3,4,5;
请修改这些示例 SELECT 语句,以通过在 SELECT 语句中包含相应的文本作为字面量来生成一个结果集,该结果集是一系列 GRANT 语句。
使用表 AccessRightsAbbv 查找访问权限的完整文本,因为联接键是一个缩写形式的“type”字段。 有关 Teradata 访问权限及其在 Azure Synapse 中的等效项的列表,请参阅下表。
| Teradata 权限名称 | Teradata 类型 | Azure Synapse 等效项 |
|---|---|---|
| ABORT SESSION | AS | KILL DATABASE CONNECTION |
| ALTER EXTERNAL PROCEDURE | AE | 4 |
| ALTER FUNCTION | AF | ALTER FUNCTION |
| ALTER PROCEDURE | AP | ALTER PROCEDURE |
| CHECKPOINT | CP | CHECKPOINT |
| CREATE AUTHORIZATION | CA | CREATE LOGIN |
| CREATE DATABASE | CD | CREATE DATABASE |
| CREATE EXTERNAL PROCEDURE | CE | 4 |
| CREATE FUNCTION | CF | CREATE FUNCTION |
| CREATE GLOP | GC | 3 |
| CREATE MACRO | CM | CREATE PROCEDURE 2 |
| CREATE OWNER PROCEDURE | OP | CREATE PROCEDURE |
| CREATE PROCEDURE | PC | CREATE PROCEDURE |
| CREATE PROFILE | CO | CREATE LOGIN 1 |
| CREATE ROLE | CR | CREATE ROLE |
| DROP DATABASE | DD | DROP DATABASE |
| .DROP FUNCTION | DF | .DROP FUNCTION |
| DROP GLOP | GD | 3 |
| DROP MACRO | DM | DROP PROCEDURE 2 |
| DROP PROCEDURE | PD | DELETE PROCEDURE |
| DROP PROFILE | DO | DROP LOGIN 1 |
| DROP ROLE | DR | DELETE ROLE |
| DROP TABLE | DT | DROP TABLE |
| DROP_TRIGGER | DG | 3 |
| DROP USER | DU | DROP USER |
| DROP VIEW | DV | DROP VIEW |
| DUMP | DP | 4 |
| EXECUTE | E | EXECUTE |
| EXECUTE FUNCTION | EF | EXECUTE |
| EXECUTE PROCEDURE | PE | EXECUTE |
| GLOP MEMBER | GM | 3 |
| INDEX | IX | CREATE INDEX |
| INSERT | I | INSERT |
| MONRESOURCE | MR | 5 |
| MONSESSION | MS | 5 |
| OVERRIDE DUMP CONSTRAINT | OA | 4 |
| OVERRIDE RESTORE CONSTRAINT | OR | 4 |
| REFERENCES | RF | REFERENCES |
| REPLCONTROL | RO | 5 |
| RESTORE | RS | 4 |
| SELECT | R | SELECT |
| SETRESRATE | SR | 5 |
| SETSESSRATE | SS | 5 |
| SHOW | SH | 3 |
| UPDATE | U | UPDATE |
AccessRightsAbbv 表格备注:
Teradata
PROFILE在功能上等效于 Azure Synapse 中的LOGIN。下表汇总了 Teradata 中的宏和存储过程之间的差异。 在 Azure Synapse 中,过程提供表中所述的功能。
宏 存储过程 包含 SQL 包含 SQL 可以包含 BTEQ 点命令 包含综合 SPL 可以接收传递给它的参数值 可以接收传递给它的参数值 可以检索一行或多行 必须使用游标检索多行 存储在 DBC PERM 空间中 存储在 DATABASE 或 USER PERM 中 将行返回给客户端 可将一个或多个值作为参数返回给客户端 SHOW、GLOP和TRIGGER在 Azure Synapse 中没有直接的等效项。这些功能由 Azure Synapse 中的系统自动管理。 请参阅操作注意事项。
在 Azure Synapse 中,这些功能在数据库外部处理。
有关 Azure Synapse 中的访问权限的详细信息,请参阅 Azure Synapse Analytics 安全权限。
运行考虑事项
提示
有必要执行操作任务来使任何数据仓库保持高效运行。
本部分介绍如何在 Azure Synapse 中以最低的风险、在对用户造成最小影响的情况下实现典型的 Teradata 操作任务。
与所有数据仓库产品一样,一旦投入生产,就有必要执行持续的管理任务来使系统保持高效运行并提供监视和审核数据。 为将来的发展规划资源利用率和容量也属于这种任务类别,数据备份/还原同样如此。
虽然从概念上讲,针对不同数据仓库的管理和操作任务是相似的,但各自的实现可能有所不同。 一般而言,Azure Synapse 等新式基于云的产品倾向于采用自动化程度更高的“系统托管”方法(而 Teradata 等旧式数据仓库中则采用“手动”程度更高的方法)。
以下部分将 Teradata 和 Azure Synapse 的各种操作任务选项做了比较。
保养工作任务
提示
保养工作任务使生产仓库保持高效运行,并优化存储等资源的使用。
在大多数旧式数据仓库环境中,必须执行常规的“保养工作”任务,例如回收磁盘存储空间(可以通过移除已更新或删除的行的旧版本来释放),或者重新组织数据日志文件或索引块以提高效率。 收集统计信息也可能是一项耗时的任务。 在批量引入数据后需要收集统计信息,以便为查询优化器提供最新数据来建立生成查询执行计划的基础。
Teradata 建议按如下所述收集统计信息:
收集未填充的表的统计信息,以设置用于内部处理的区间直方图。 完成这第一次收集后,后续的统计信息收集速度更快。 确保在添加数据后重新收集统计信息。
为新填充的表收集原型阶段统计信息。
在对表或分区进行很大比例的更改(大约更改了 10% 的行)后,收集生产阶段统计信息。 如果存在大量的非唯一值(例如日期或时间戳),按 7% 的比例重新收集统计信息可能有利。
在创建用户并将真实查询负载应用于数据库(最多大约三个月的查询)之后收集生产阶段统计信息。
在 CPU 利用率较低的时段,在升级或迁移之后的最初几周收集统计信息。
可以使用自动化统计信息管理开放 API 手动管理或使用 Teradata Viewpoint Stats Manager portlet 自动管理统计信息收集。
提示
在 Azure 中自动化和监视保养工作任务。
Teradata 数据库在数据字典中包含许多日志表,其中会自动或在启用某些功能后累积数据。 由于日志数据会不断增长,因此请清除旧信息以避免耗尽永久性空间。 可以使用一些选项来自动维护这些日志。 下面介绍了需要维护的 Teradata 字典表。
要维护的字典表
使用随软件一起提供的 DBC.AMPUsage 视图和 ClearPeakDisk 宏来重置累加器和峰值:
DBC.Acctg:帐户/用户的资源使用量DBC.DataBaseSpace:数据库和表空间记帐
Teradata 会自动维护这些表,但良好的做法可以减少其大小:
DBC.AccessRights:对象的用户权限DBC.RoleGrants:对象的角色权限DBC.Roles:定义的角色DBC.Accounts:用户的帐户代码
请存档这些日志记录表(如果需要)并清除 60-90 天前的信息。 保留期取决于客户要求:
DBC.SW_Event_Log:数据库控制台日志DBC.ResUsage:资源监视表DBC.EventLog:会话登录/注销历史记录DBC.AccLogTbl:记录的用户/对象事件DBC.DBQL tables:记录的用户/SQL 活动.NETSecPolicyLogTbl:记录动态安全策略审核跟踪.NETSecPolicyLogRuleTbl:控制何时以及如何记录动态安全策略
当关联的可移动媒体过期并被覆盖时,请清除以下表:
DBC.RCEvent:存档/恢复事件DBC.RCConfiguration:存档/恢复配置DBC.RCMedia:存档/恢复操作的 VolSerial
Azure Synapse 提供一个选项用于自动创建统计信息,以便可以根据需要使用它们。 手动、按计划或自动对索引和数据块执行碎片整理。 利用原生内置的 Azure 功能可以减少迁移练习中所需的工作量。
监视和审核
提示
随着时间的推迟,现已实现多种不同的工具来监视和记录 Teradata 系统。
Teradata 提供多种工具用于监视操作,包括 Teradata Viewpoint 和 Ecosystem Manager。 要记录查询历史记录,可以使用数据库查询日志 (DBQL) 这项 Teradata 数据库功能,它提供一系列预定义的表,用于根据用户定义的规则存储查询的历史记录及其持续时间、性能和目标活动。
数据库管理员可以使用 Teradata Viewpoint 来确定系统状态、趋势和各种查询状态。 通过观察系统的使用趋势,系统管理员可以更好地规划项目实施、批处理作业和维护,以避免出现使用高峰期。 业务用户可以使用 Teradata Viewpoint 快速访问报表和查询的状态并向下钻取详细信息。
提示
Azure 门户提供了一个 UI 用于管理所有 Azure 数据和流程的监视与审核任务。
同样,Azure Synapse 在 Azure 门户中提供了丰富的监视体验用于提供数据仓库工作负载的见解。 建议使用 Azure 门户来监视数据仓库,因为它提供可配置的保持期、警报、建议,并为指标和日志提供可自定义的图表与仪表板。
在门户中,还可与 Operations Management Suite (OMS)、Azure Monitor(日志)等其他 Azure 监视服务集成。这样,不仅可以针对数据仓库,而且还能针对整个 Azure 分析平台提供一体式监视体验,构成一种集成式监视体验。
提示
低级别和系统范围的指标将自动记录在 Azure Synapse 中。
Azure Synapse 的资源利用率统计信息将自动记录在系统中。 每个查询的指标包括 CPU、内存、缓存、I/O 和临时工作区的使用率统计信息,以及失败的连接尝试等连接信息。
Azure Synapse 提供一组动态管理视图 (DMV)。 在主动排查和识别工作负荷的性能瓶颈时,这些视图非常有用。
有关详细信息,请参阅 Azure Synapse 操作和管理选项。
高可用性 (HA) 和灾难恢复 (DR)
Teradata 可实现 FALLBACK、存档还原复制 (ARC) 实用工具和数据流体系结构 (DSA) 等功能,以通过数据复制和存档来防止数据丢失并提供高可用性 (HA)。 灾难恢复 (DR) 选项包括双主动解决方案、DR 即服务或替换系统,具体取决于恢复时间要求。
提示
Azure Synapse 自动创建快照以确保快速恢复。
Azure Synapse 使用数据库快照来提供仓库的高可用性。 数据仓库快照会创建一个还原点,利用该还原点可将数据仓库恢复或复制到以前的状态。 由于 Azure Synapse 属于分布式系统,因此数据仓库快照包含 Azure 存储中的许多文件。 快照捕获数据仓库中存储的数据的增量更改。
Azure Synapse 自动创建全天快照,并创建 7 天的可用还原点。 无法更改此保持期。 Azure Synapse 支持 8 小时恢复点目标 (RPO)。 可以在主要区域中从过去 7 天创建的任一快照还原数据仓库。
提示
在更新密钥之前,使用用户定义的快照定义恢复点。
此外,支持用户定义的还原点,以便在进行大规模修改之前和之后手动触发快照来创建数据仓库的还原点。 此功能确保还原点保持逻辑一致性,可在发生任何工作负载中断或用户错误时提供额外的数据保护,以实现小于 8 小时的所需 RPO。
提示
Microsoft Azure 提供自动备份到单独的地理位置以实现 DR 的功能。
除了前面所述的快照外,Azure Synapse 还按标准方式每日异地备份到配对的数据中心一次。 异地还原的 RPO 为 24 小时。 可以将异地备份还原到支持 Azure Synapse 的任何其他区域中的服务器。 异地备份可确保主要区域中的还原点不可用时可以还原数据仓库。
工作负荷管理
提示
在生产数据仓库中,通常会并发运行具有不同资源使用特征的混合工作负载。
工作负载是一种具有共同特征的数据库请求,可以使用一组规则来管理它们对数据库的访问。 工作负载可用于:
为不同类型的请求设置不同的访问优先级。
监视资源使用模式、性能优化和容量规划。
限制可同时运行的请求或会话数。
在 Teradata 系统中,工作负载管理是指通过监视系统活动来管理工作负载性能,并在达到预定义的限制时采取措施。 工作负载管理使用规则,每个规则仅应用于某些数据库请求。 但是,所有规则的集合将应用于平台上的所有活动工作。 Teradata Active System Management (TASM) 在 Teradata 数据库中执行完整工作负载管理。
在 Azure Synapse 中,资源类是预先确定的资源限制,用于控制查询执行的计算资源和并发性。 资源类可以针对并发运行的查询数以及分配给每个查询的计算资源量设置限制,从而帮助管理工作负载。 我们需要在内存和并发性之间进行权衡。
Azure Synapse 会自动记录资源利用率统计信息。 指标包括每个查询的 CPU、内存、缓存、I/O 和临时工作区的使用统计信息。 Azure Synapse 还会记录连接信息,例如连接尝试失败。
提示
低级别和系统范围的指标会自动记录在 Azure 中。
Azure Synapse 支持以下基本工作负载管理概念:
工作负载分类:可以将请求分配给工作负载组以设置重要性级别。
工作负载重要性:可影响请求获取资源访问权限的顺序。 默认情况下,当资源可用时,查询以先进先出的方式从队列中释放。 工作负载重要性使较高优先级的查询能立即接收资源,无论队列长度情况如何。
工作负载隔离:可以为工作负载组保留资源,为不同资源分配最大和最小使用量,限制一组请求可以使用的资源,并设置超时值以自动终止失控查询。
运行混合工作负荷会给繁忙的系统带来资源挑战。 成功的工作负载管理方案能够有效地管理资源,确保高效的资源利用,并将投资回报率 (ROI) 最大化。 工作负载分类、工作负载重要性和工作负载隔离可以更好地控制工作负载利用系统资源的方式。
工作负载管理指南介绍了用于分析工作负载、管理和监视工作负载重要性的技术](../../sql-data-warehouse/sql-data-warehouse-how-to-manage-and-monitor-workload-importance.md),以及将资源类转换为工作负载组的步骤。 使用 Azure 门户和 DMV 上的 T-SQL 查询来监视工作负载,确保有效利用适用的资源。 Azure Synapse 提供了一组动态管理视图 (DMV),用于监视工作负负载管理的各个方面。 在主动排查和识别工作负载的性能瓶颈时,这些视图非常有用。
此信息还可用于容量规划,以及确定附加用户或应用程序工作负载所需的资源。 此信息还适用于规划计算资源的纵向扩展/缩减,以便为“高峰”工作负载提供经济高效的支持。
有关 Azure Synapse 中的工作负载管理的详细信息,请参阅使用资源类进行工作负载管理。
缩放计算资源
提示
Azure 的一项主要优势是能够按需独立纵向扩展和缩减计算资源,以便以经济高效的方式处理高峰工作负载。
Azure Synapse 的体系结构对存储和计算进行了分隔,允许单独缩放每种资源。 因此,可以根据性能需求独立于数据存储缩放计算资源。 还可以暂停和恢复计算资源。 此体系结构的原生优势是,计算和存储的计费是分开的。 如果未使用数据仓库,你可以通过暂停计算来节省计算成本。
通过调整数据仓库的数据仓库单位设置,可以纵向扩展或缩减计算资源。 添加更多的数据仓库单位后,加载和查询性能会线性提高。
添加更多计算节点可增大计算能力,并可以利用更高的并行处理能力。 随着计算节点数量的增加,每个计算节点的分布区数量会减少,因此可为查询提供更高的计算能力和并发处理能力。 同样,减少数据仓库单位会减少计算节点数量,从而减少用于查询的计算资源。
后续步骤
若要详细了解可视化效果和报表,请参阅本系列教程的下一篇文章:Teradata 的可视化效果和报表迁移。