你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 流分析自定义 blob 输出分区
Azure 流分析支持包含自定义字段或属性和自定义 DateTime 路径模式的自定义 blob 输出分区。
自定义字段或属性
自定义字段或输入属性通过允许进一步控制输出,改进下游数据处理和报告工作流。
分区键选项
用于对输入数据进行分区的分区键或列名可以包含 blob 名称可以接受的任何字符。 除非与别名一起使用,否则无法将嵌套字段用作分区键。 不过,可以使用某些字符来创建文件的层次结构。 例如,可以使用以下查询创建一个列,该列将来自其他两个列的数据组合在一起以构成唯一的分区键:
SELECT name, id, CONCAT(name, "/", id) AS nameid
分区键必须为 NVARCHAR(MAX)、BIGINT、FLOAT 或 BIT(1.2 兼容性级别或更高级别)。 不支持 DateTime、Array 和 Records 类型,但如果将它们转换为 String,则可用作分区键。 有关详细信息,请参阅 Azure 流分析数据类型。
示例
假设作业从连接到外部视频游戏服务的实时用户会话获取输入数据,其中引入的数据包含用于识别会话的列 client_id。 若要按 client_id 对数据进行分区,请在创建作业时将 blob“路径模式”字段设置为在 blob 输出属性中添加分区标记 {client_id}。 当包含各种 client_id 值的数据流经流分析作业时,输出数据根据每个文件夹的单一 client_id 值保存到单独的文件夹中。

同样,如果作业输入是来自数百万个传感器的传感器数据(其中每个传感器有一个 sensor_id),那么路径模式为 {sensor_id},用于将每个传感器数据分区到不同的文件夹中。
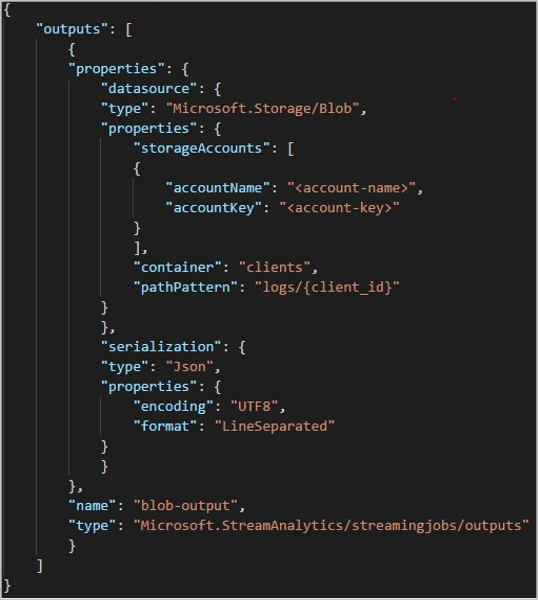
使用 REST API 时,用于该请求的 JSON 文件的输出节可能如下图所示:
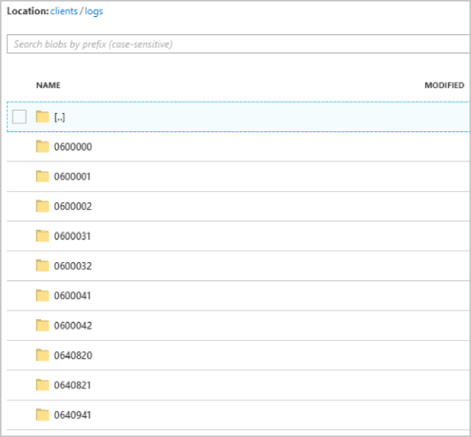
作业开始运行后,clients 容器可能如下图所示:
每个文件夹都可能包含多个 blob,其中每个 blob 包含一个或多个记录。 在前面的示例中,标记为 "06000000" 的文件夹中有一个 blob,其中包含以下内容:
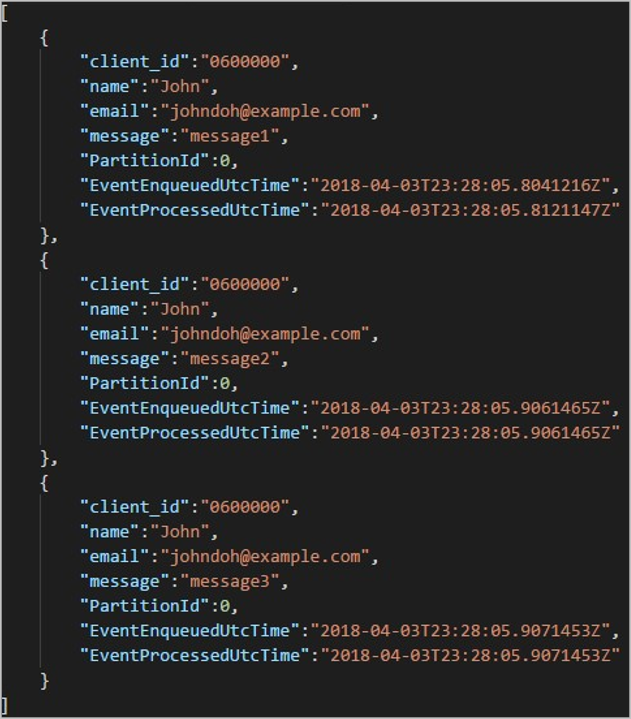
请注意,blob 中的每个记录都有一个与文件夹名称匹配的 client_id 列,这是因为用于在输出路径中对输出进行分区的列是 client_id。
限制
“路径模式”blob 输出属性中只允许有一个自定义分区键。 以下所有路径模式都有效:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
如果客户想要使用多个输入字段,他们可以使用
CONCAT在针对 blob 输出中的自定义路径分区的查询中创建组合键。 示例为select concat (col1, col2) as compositeColumn into blobOutput from input。 然后,他们可以将compositeColumn指定为 Azure Blob 存储中的自定义路径。分区键不区分大小写,因此
John和john等分区键等效。 另外,表达式无法用作分区键。 例如,{columnA + columnB}无效。如果输入流由分区键基数低于 8,000 的记录组成,则这些记录会附加到现有 blob。 它们仅在必要时创建新的 blob。 如果基数超过 8,000,则无法保证写入现有的 blob。 不会为具有相同分区键的任意数量的记录创建新的 blob。
如果 blob 输出 配置为不可变,则每次发送数据时,流分析都会新建 blob。
自定义 DateTime 路径模式
可以使用自定义 DateTime 路径模式来指定与 Hive 流式处理约定相符的输出格式,这样流分析就可以将数据发送到 Azure HDInsight 和 Azure Databricks 进行下游处理。 自定义 DateTime 路径模式可以轻松地实现,只需在 blob 输出的“路径前缀”字段中使用 datetime 关键字并使用格式说明符即可。 示例为 {datetime:yyyy}。
支持的令牌
以下格式说明符令牌可以单独使用,也可以组合使用,以便实现自定义 DateTime 格式。
| 格式说明符 | 说明 | 示例时间 2018-01-02T10:06:08 的结果 |
|---|---|---|
| {datetime:yyyy} | 年份为四位数 | 2018 |
| {datetime:MM} | 月份为 01 到 12 | 01 |
| {datetime:M} | 月份为 1 到 12 | 1 |
| {datetime:dd} | 日期为 01 到 31 | 02 |
| {datetime:d} | 日期为 1 到 31 | 2 |
| {datetime:HH} | 小时为 00 到 23,采用 24 小时格式 | 10 |
| {datetime:mm} | 分钟为 00 到 60 | 06 |
| {datetime:m} | 分钟为 0 到 60 | 6 |
| {datetime:ss} | 秒为 00 到 60 | 08 |
如果不希望使用自定义 DateTime 模式,可以将 {date} 和/或 {time} 令牌添加到“路径前缀”字段,从而使用内置的 格式生成下拉列表DateTime。
扩展性和限制
可以在路径模式中使用尽量多的令牌 ({datetime:<specifier>}),直到达到路径前缀字符限制。 在单个令牌中,格式说明符的组合不能超出日期和时间下拉列表已经列出的组合。
对于 logs/MM/dd 路径分区:
| 有效表达式 | 无效表达式 |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
可以在路径前缀中多次使用同一格式说明符。 令牌每次都必须重复。
Hive 流式处理约定
Blob 存储的自定义路径模式可以与 Hive 流式处理约定配合使用,后者要求文件夹在其名称中使用 column= 进行标记。
示例为 year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}。
有了自定义输出,就不需更改表,也不需将分区添加到流分析和 Hive 之间的端口数据。 许多文件夹可以使用以下方式自动添加:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
示例
根据流分析 Azure 门户快速入门中的说明,创建存储帐户、资源组、流分析作业和输入源。 使用在快速入门中使用的相同示例数据。 此外,GitHub 上也会提供示例数据。
使用以下配置创建 Blob 输出接收器:
完整路径模式为:
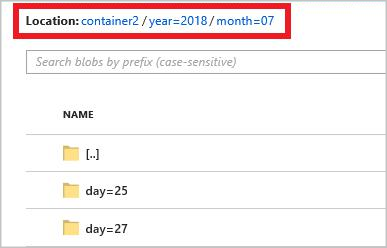
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
启动作业时,会在 Blob 容器中创建基于路径模式的文件夹结构。 可以向下钻取到日级别。