你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:使用 Azure Synapse Analytics 捕获 Parquet 格式的事件中心数据并进行分析
此教程展示如何使用流分析无代码编辑器来创建作业,以便以 Parquet 格式将事件中心数据捕获到 Azure Data Lake Storage Gen2。
本教程介绍如何执行下列操作:
- 部署用于将示例事件发送到事件中心的事件生成器
- 如何使用无代码编辑器创建流分析作业
- 查看输入数据和架构
- 配置将捕获事件中心数据的 Azure Data Lake Storage Gen2
- 运行流分析作业
- 使用 Azure Synapse Analytics 查询 Parquet 文件
先决条件
在开始之前,请确保已完成以下步骤:
- 如果还没有 Azure 订阅,可以创建一个免费帐户。
- 将 TollApp 事件生成器应用部署到 Azure。 将“interval”参数设置为 1,并使用新资源组执行此步骤。
- 使用 Data Lake Storage Gen2 帐户创建 Azure Synapse Analytics 工作区。
使用无代码编辑器创建流分析作业
找到在其中部署了 TollApp 事件生成器的资源组。
选择 Azure 事件中心命名空间。 你可能想要在单独的选项卡或窗口中打开它。
在“事件中心命名空间”页上,选择左侧菜单上“实体”下的“事件中心”。
选择
entrystream实例。
在“事件中心实例”页上,选择左侧菜单上的“功能”部分中的“处理数据”。
在“以 Parquet 格式将数据捕获到 ADLS Gen2”磁贴上选择“开始”。

将作业命名为“
parquetcapture”,然后选择“创建”。
在事件中心配置页上,按照以下步骤操作:
对于“使用者组”,选择“使用现有”。
确认已选择
$Default使用者组。确认已将“序列化”设置为 JSON。
确认已将“身份验证方法”设置为“连接字符串”。
确认已将“事件中心共享访问密钥名称”设置为“RootManageSharedAccessKey”。
在窗口底部,选择“连接”。

几秒钟内,你将看到示例输入数据和架构。 可以选择删除字段、重命名字段或更改数据类型。

在画布上选择 Azure Data Lake Storage Gen2 磁贴,并通过指定以下项进行配置
Azure Data Lake Gen2 帐户所在的订阅
存储帐户名称,该名称应与在先决条件部分中完成的 Azure Synapse Analytics 工作区使用的 ADLS Gen2 帐户相同。
将在其中创建 Parquet 文件的容器。
对于“增量表路径”,指定该表的名称。
日期和时间模式,默认为 yyyy-mm-dd 和 HH。
选择“连接”

在顶部功能区中选择“保存”以保存作业,然后选择“启动”以运行作业。 启动作业后,选择右上角的“X”以关闭“流分析作业”页。

然后,你将看到使用无代码编辑器创建的所有流分析作业的列表。 在两分钟内,作业将进入“正在运行”状态。 选择页面上的“刷新”按钮,查看状态是否按“已创建”->“正在启动”->“正在运行”的顺序变化。









在 Azure Data Lake Storage Gen 2 帐户中查看输出
找到在上一步中使用的 Azure Data Lake Storage Gen2 帐户。
选择在上一步中使用的容器。 你将看到在前面指定的文件夹中创建的 parquet 文件。
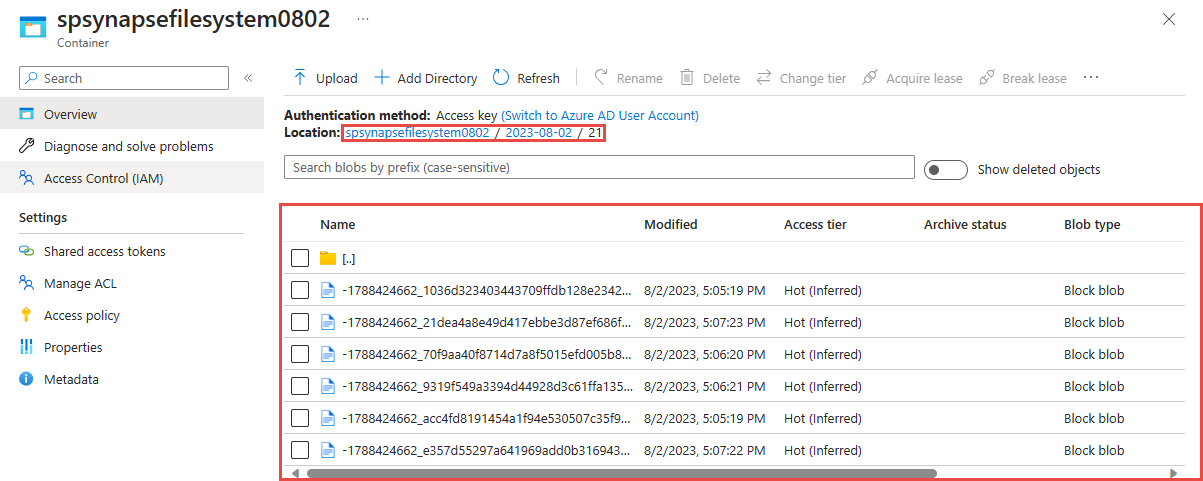

使用 Azure Synapse Analytics 查询 Parquet 格式的捕获数据
使用 Azure Synapse Spark 进行查询
找到 Azure Synapse Analytics 工作区并打开 Synapse Studio。
在工作区中创建无服务器 Apache Spark 池(如果尚不存在)。
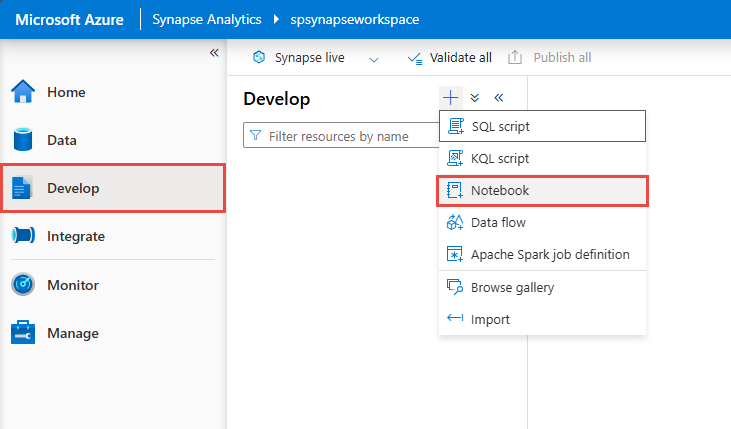
在 Synapse Studio 中,转到“开发”中心,然后新建 Notebook。
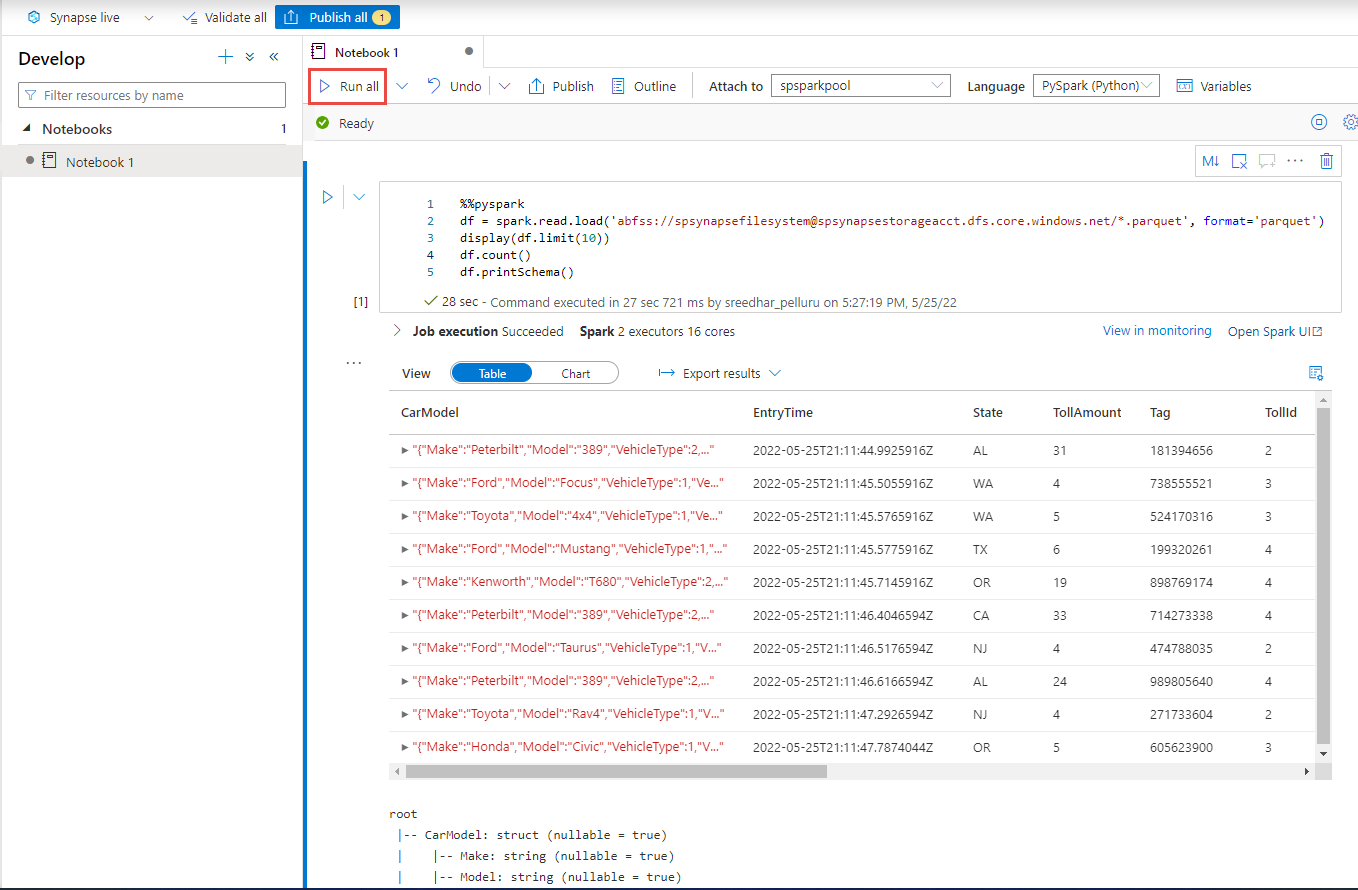
创建新代码单元并将以下代码粘贴到该单元中。 将“容器”和 adlsname 替换为在上一步中使用的容器和 ADLS Gen2 帐户的名称。
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()对于工具栏上的“附加到”,请从下拉列表中选择 Spark 池。
选择“全部运行”,看看结果

使用 Azure Synapse 无服务器 SQL 进行查询
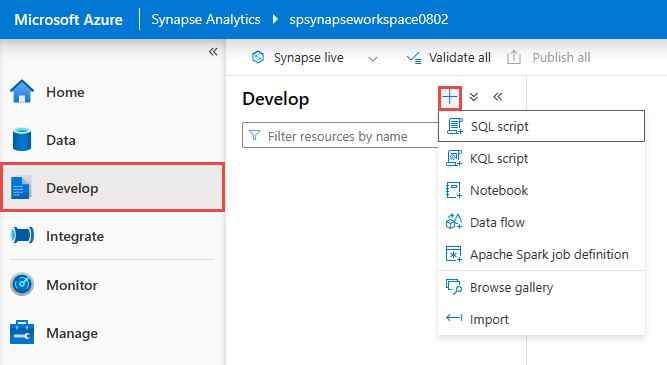
在“开发”中心中,创建新的“SQL 脚本”。
粘贴以下脚本,并使用“内置”无服务器 SQL 终结点运行该脚本。 将“容器”和 adlsname 替换为在上一步中使用的容器和 ADLS Gen2 帐户的名称。
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]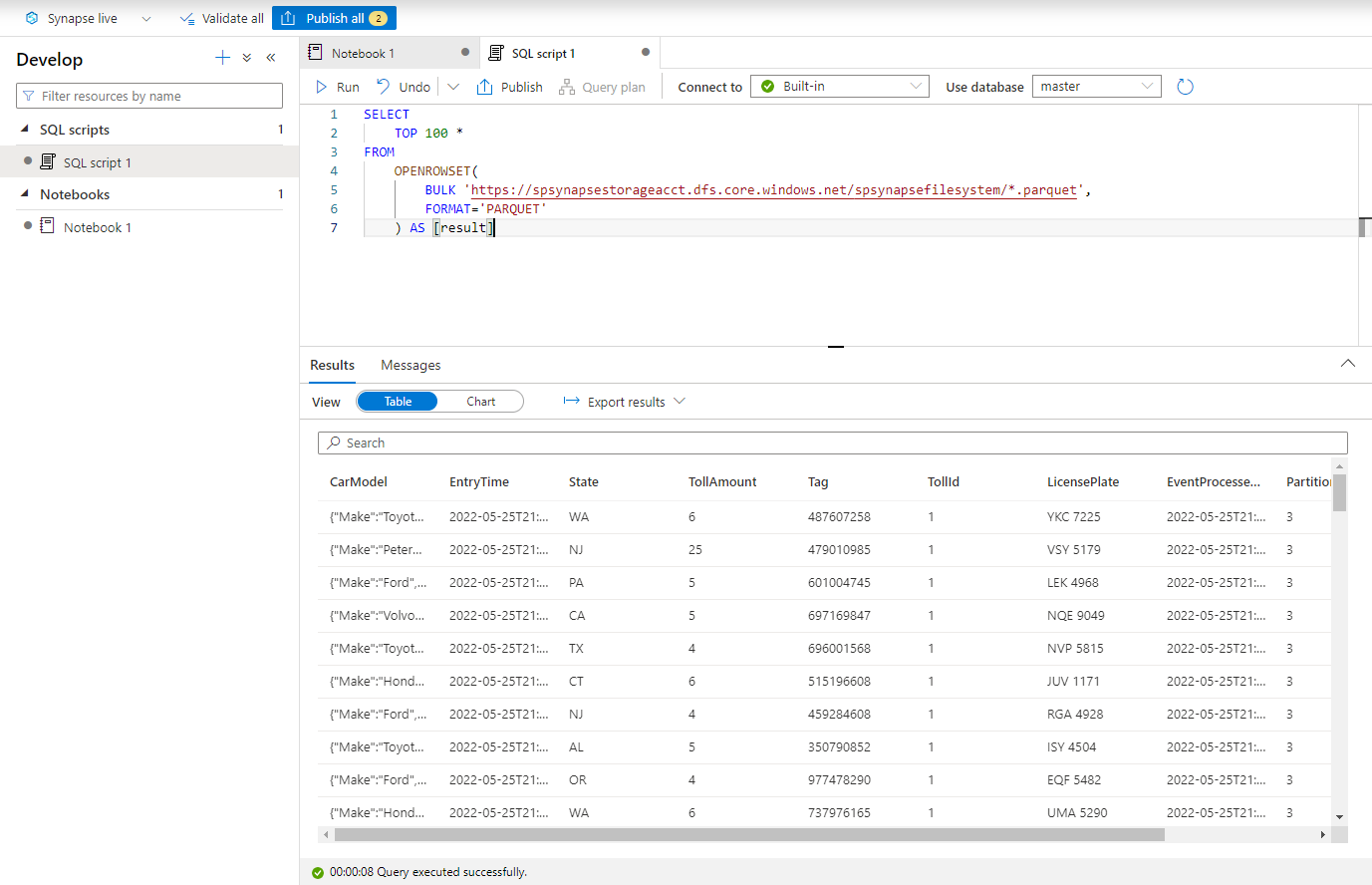

清理资源
- 找到你的事件中心实例,并在“处理数据”部分下查看流分析作业列表。 停止正在运行的任何作业。
- 转到在部署 TollApp 事件生成器时使用的资源组。
- 选择“删除资源组” 。 键入资源组名称以确认删除。
后续步骤
在本教程中,你了解了如何使用无代码编辑器创建流分析作业,以 Parquet 格式捕获事件中心数据流。 然后,你使用 Azure Synapse Analytics 通过 Synapse Spark 和 Synapse SQL 查询了 Parquet 文件。