你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure Monitor 日志监视 Site Recovery
本文介绍如何使用 Azure Monitor 日志和 Log Analytics 监视 Azure Site Recovery 复制的计算机。
Azure Monitor 日志提供一个日志数据平台用于收集活动和资源日志,以及其他监视数据。 在 Azure Monitor 日志中,可以使用 Log Analytics 编写和测试日志查询,并以交互方式分析日志数据。 可以可视化和查询日志结果,并配置警报来根据监视的数据采取措施。
对于 Site Recovery,Azure Monitor 日志可帮助你执行以下操作:
- 监视 Site Recovery 运行状况和状态。 例如,可以监视复制运行状况、测试故障转移状态、Site Recovery 事件、受保护计算机的恢复点目标 (RPO),以及磁盘/数据更改率。
- 为 Site Recovery 设置警报。 例如,可以针对计算机运行状况、测试故障转移状态或 Site Recovery 作业状态配置警报。
支持结合 Site Recovery 使用 Azure Monitor 日志进行“Azure 到 Azure”的复制和“VMware 虚拟机/物理服务器到 Azure”的复制。
注意
若要获取 VMware 和物理计算机的变动数据日志和上传速率日志,需要在进程服务器上安装 Microsoft 监视代理。 此代理可将复制计算机的日志发送到工作区。 此功能仅适用于 9.30 移动代理版本和更高版本。
必备条件
下面是需要的项:
- 至少一台在恢复服务保管库中受保护的计算机。
- 用于存储 Site Recovery 日志的 Log Analytics 工作区。 了解如何设置工作区。
- 基本了解如何在 Log Analytics 中编写、运行和分析日志查询。 了解详细信息。
在开始之前,我们建议查看常见监视问题。
可用于 Azure Site Recovery 的事件日志
Azure Site Recovery 提供以下特定于资源的表和旧表。 每个事件都提供一组特定的站点恢复相关项目的详细数据。
特定于资源的表:
旧表:
- Azure Site Recovery 事件
- Azure Site Recovery 复制项
- Azure Site Recovery 复制统计信息
- Azure Site Recovery 恢复点
- Azure Site Recovery 复制数据上传速度
- Azure Site Recovery 受保护的磁盘数据改动
- Azure Site Recovery 复制项详细信息
配置 Site Recovery 以发送日志
在保管库中,选择“诊断设置”>“添加诊断设置”。
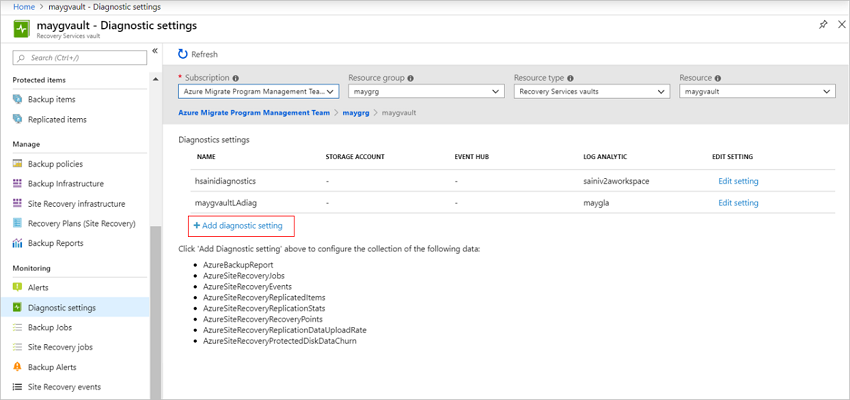
在“诊断设置”中,指定一个名称,并选中“发送到 Log Analytics”复选框 。
选择 Azure Monitor 日志订阅和 Log Analytics 工作区。
在切换选项中选择“Azure 诊断”。
在日志列表中,选择带有 AzureSiteRecovery 前缀的所有日志。 然后选择“确定”。
Site Recovery 日志将开始馈送到选定工作区中的某个表 (AzureDiagnostics) 内。
在进程服务器上配置 Microsoft 监视代理以发送变动和上传速率日志
可以在本地捕获 VMware/物理计算机的数据变动速率信息和源数据上传速率信息。 若要启用此功能,需要在进程服务器上安装 Microsoft 监视代理。
转到 Log Analytics 工作区并选择“高级设置”。
选择“连接的源”页面,然后选择“Windows Server”。
在进程服务器上下载 Windows 代理(64 位)。
通过提供获取的工作区 ID 和密钥完成代理安装。
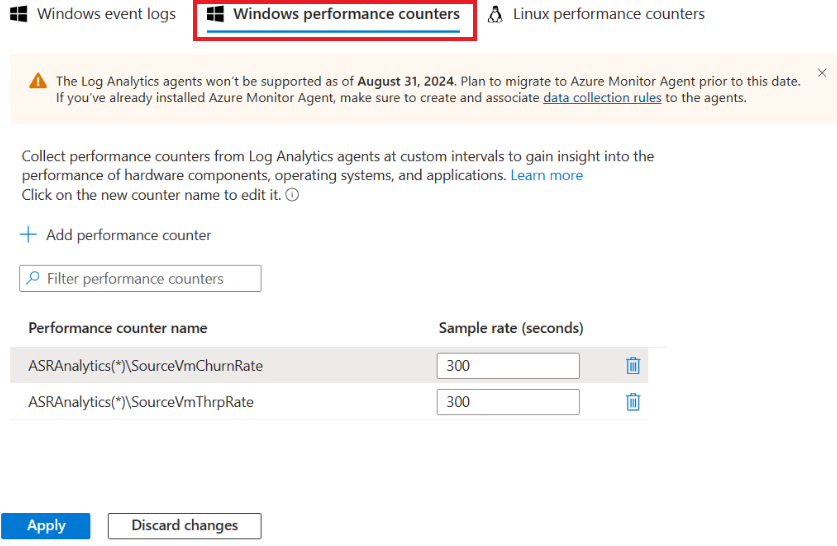
安装完成后,转到 Log Analytics 工作区并选择“旧代理管理”。 转到“数据”页并选择“Windows 性能计数器”。
选择“+”添加以下两个计数器,采样间隔为 300 秒:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
变动和上传速率数据将开始输入工作区。
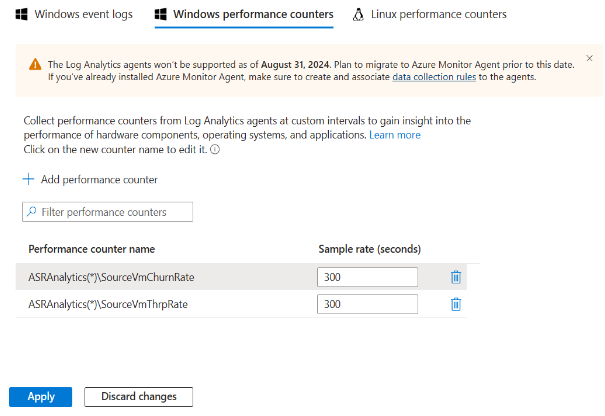
目前无法搜索以下 Site Recovery 计数器:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
但是,可以通过粘贴完整名称来添加它们。
注意
目前,无法搜索这些计数器。 但是,可以通过复制并粘贴其全名来添加它们。
- SourceVmThrpRate 会通过源上的放置速率显示网络。
- SourceVmChurnRate 会在源虚拟机的磁盘上显示数据更改率。
查询日志 - 示例
使用以 Kusto 查询语言编写的日志查询从日志中检索数据。 本部分提供几个可用于 Site Recovery 监视的常见查询示例。
注意
其中一些示例使用设置为 A2A 的 replicationProviderName_s。 它检索使用 Site Recovery 复制到次要 Azure 区域的 Azure 虚拟机。 若要检索使用 Site Recovery 复制到 Azure 的本地 VMware 虚拟机或物理服务器,可在这些示例中将 A2A 替换为 InMageRcm。
查询复制运行状况
此查询绘制所有受保护 Azure 虚拟机的当前复制运行状况的饼图,这些虚拟机分为三种状态:正常、警告或严重。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
查询移动服务版本
此查询为使用 Site Recovery 复制的 Azure 虚拟机绘制饼图,这些虚拟机按其运行的移动代理版本进行细分。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
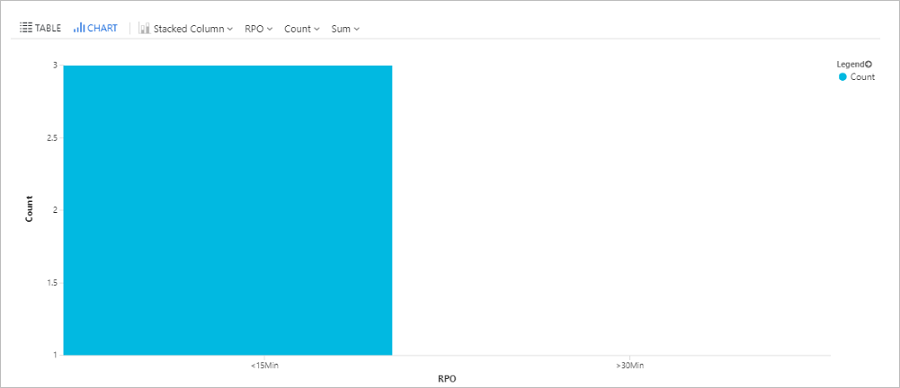
查询 RPO 时间
此查询绘制使用 Site Recovery 复制的 Azure 虚拟机的条形图,这些虚拟机按以下恢复点目标 (RPO) 进行细分:不到 15 分钟、15-30 分钟、超过 30 分钟。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
查询 Site Recovery 作业
此查询检索过去 72 小时触发的所有 Site Recovery 作业(适用于所有灾难恢复方案)及其完成状态。
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
查询 Site Recovery 事件
此查询检索过去 72 小时引发的所有 Site Recovery 事件(适用于所有灾难恢复方案)及其严重性。
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
查询测试故障转移状态(饼图)
此查询绘制使用 Site Recovery 复制的 Azure 虚拟机的测试故障转移状态饼图。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
查询测试故障转移状态(表格)
此查询绘制使用 Site Recovery 复制的 Azure 虚拟机的测试故障转移状态表。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
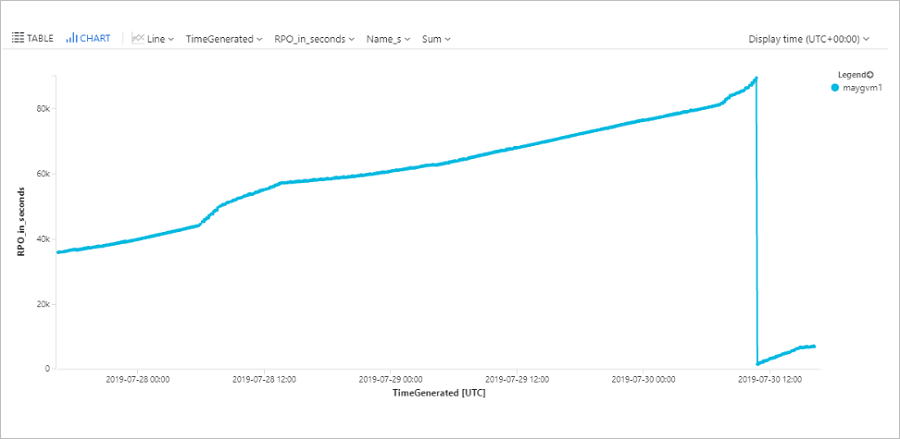
查询计算机 RPO
此查询绘制一个趋势图,用于跟踪特定 Azure 虚拟机 (ContosoVM123) 在过去 72 小时的 RPO。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart
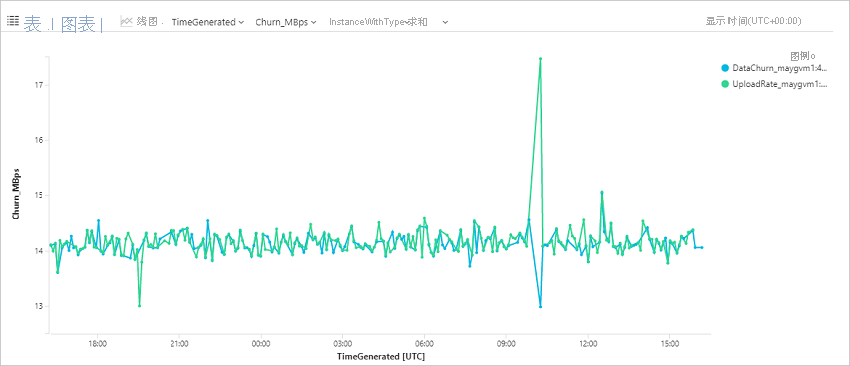
查询 Azure 虚拟机的数据更改(变动)速率和上传速率
此查询绘制特定 Azure 虚拟机 (ContosoVM123) 的趋势图,表示数据更改速率(每秒写入字节数)和数据上传速率。
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
查询 VMware 或物理计算机的数据更改(变动)速率和上传速率
注意
请确保在进程服务器上设置监视代理以获取这些日志。 请参阅配置监视代理的步骤。
此查询为复制的项 win-9r7sfh9qlru 的特定磁盘 disk0 绘制趋势图,表示数据更改速率(每秒写入字节数)和数据上传速率。 可以在恢复服务保管库中复制的项的“磁盘”边栏选项卡上找到磁盘名称。 要在查询中使用的实例名是计算机的 DNS 名称,后跟 _ 和磁盘名称,如本例所示。
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
进程服务器每 5 分钟将此数据推送到 Log Analytics 工作区。 这些数据点表示 5 分钟内计算的平均值。
查询灾难恢复摘要(Azure 到 Azure)
此查询绘制已复制到次要 Azure 区域的 Azure 虚拟机的摘要表。 它显示虚拟机名称、复制和保护状态、RPO、测试故障转移状态、移动代理版本、任何活动的复制错误以及源位置。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
查询灾难恢复摘要(VMware/物理服务器)
此查询绘制已复制到 Azure 的 VMware 虚拟机和物理服务器的摘要表。 其中显示计算机名称、复制和保护状态、RPO、测试故障转移状态、移动代理版本、任何活动的复制错误以及相关的进程服务器。
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
设置警报 - 示例
可以基于 Azure Monitor 数据设置 Site Recovery 警报。 详细了解如何设置日志警报。
注意
其中一些示例使用设置为 A2A 的 replicationProviderName_s。 这会针对已复制到次要 Azure 区域的 Azure 虚拟机设置警报。 若要针对已复制到 Azure 的本地 VMware 虚拟机或物理服务器设置警报,可在这些示例中将 A2A 替换为 InMageRcm。
多台计算机处于严重状态
如果有 20 台以上的已复制 Azure 虚拟机进入“严重”状态,则设置警报。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
对于警报,请将“阈值”设置为 20。
一台计算机处于严重状态
如果特定的已复制 Azure 虚拟机进入“严重”状态,则设置警报。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
对于警报,请将“阈值”设置为 1。
多台计算机超过 RPO
如果有 20 台以上的 Azure 虚拟机的 RPO 超过 30 分钟,则设置警报。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
对于警报,请将“阈值”设置为 20。
一台计算机超过 RPO
如果单台 Azure 虚拟机的 RPO 超过 30 分钟,则设置警报。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
对于警报,请将“阈值”设置为 1。
多台计算机的测试故障转移超过 90 天
如果有 20 台以上的虚拟机的上次成功测试故障转移时间已超过 90 天,则设置警报。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
对于警报,请将“阈值”设置为 20。
一台计算机的测试故障转移超过 90 天
如果某台特定虚拟机的上次成功测试故障转移时间已超过 90 天,则设置警报。
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
对于警报,请将“阈值”设置为 1。
Site Recovery 作业失败
如果在过去一天,某个 Site Recovery 作业(在本例中为“重新保护”作业)在任何 Site Recovery 方案中失败,则设置警报。
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
对于警报,请将“阈值”设置为 1,将“期限”设置为 1440 分钟,以检查过去一天发生的失败。
后续步骤
了解内置的 Site Recovery 监视。