你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:使用 SynapseML 和 Azure AI 搜索为 Apache Spark 中的大数据编制索引
本 Azure AI 搜索教程介绍如何为从 Spark 群集加载的大型数据编制索引和查询。 设置一个 Jupyter Notebook 来执行以下操作:
- 在 Apache Spark 会话中将各种表单(发票)加载到数据帧
- 分析它们以确定其功能
- 将生成的输出组合到表格数据结构中
- 将输出写入 Azure AI 搜索中托管的搜索索引
- 浏览和查询所创建的内容
本教程依赖于 SynapseML,SynapseML 是一个开源库,支持对大数据进行大规模并行机器学习。 在 SynapseML 中,搜索索引和机器学习通过执行专门任务的转换器公开。 转换器利用各种 AI 功能。 在本练习中,使用 AzureSearchWriter API 进行分析和 AI 扩充。
尽管 Azure AI 搜索具有本机 AI 扩充,本教程显示如何访问 Azure AI 搜索之外的 AI 功能。 通过使用 SynapseML 而不是索引器或技能,你不会受到数据限制或与这些对象相关的其他约束。
提示
在 https://www.youtube.com/watch?v=iXnBLwp7f88 观看此演示的简短视频。 视频将在本教程中展开,其中包含更多步骤和视觉对象。
先决条件
需要 synapseml 库和几个 Azure 资源。 如果可能,请为 Azure 资源使用相同的订阅和区域,并将所有内容放入一个资源组中,便于稍后清理。 以下链接用于门户安装。 示例数据是从公共站点导入的。
- SynapseML 包1
- Azure AI 搜索(任何层)2
- Azure AI 服务(任何层)3
- Azure Databricks(任何层)4
1 此链接是加载包的教程。
2 可以使用免费搜索层为示例数据编制索引,但如果数据量很大,请选择更高的层。 对于可计费层级,请在接下来的设置依赖项步骤中提供搜索 API 密钥。
3 本教程使用 Azure AI 文档智能和 Azure AI 翻译。 在以下说明中,提供多服务密钥和区域。 同一个密钥适用于这两个服务。
4 在本教程中,Azure Databricks 提供 Spark 计算平台。 我们按照门户说明设置了工作区。
注意
以上所有 Azure 资源都支持 Microsoft 标识平台中的安全功能。 为简单起见,本教程假定使用从每个服务的 Azure 门户页复制的终结点和密钥进行基于密钥的身份验证。 如果在生产环境中实现此工作流,或与他人共享解决方案,请记住将硬编码密钥替换为集成安全性或加密密钥。
步骤 1:创建 Spark 群集和笔记本
在本部分中,创建群集、安装 synapseml 库并创建用于运行代码的笔记本。
在 Azure 门户中,找到你的 Azure Databricks 工作区并选择“启动工作区”。
在左侧菜单中,选择“计算”。
选择“创建计算”。
接受默认配置。 创建群集需要几分钟时间。
创建群集后安装
synapseml库:从群集页面顶部的选项卡中选择“库”。
选择“新安装”。

选择“Maven”。
在坐标中,输入
com.microsoft.azure:synapseml_2.12:1.0.4选择“安装” 。
在左侧菜单中,选择“创建”>“笔记本”。
为笔记本指定一个名称,选择 Python 作为默认语言,然后选择具有
synapseml库的群集。创建七个连续单元格。 将代码粘贴到每个单元格中。
步骤 2:设置依赖项
将以下代码粘贴到笔记本的第一个单元格中。
将占位符替换为每个资源的终结点和访问密钥。 提供新搜索索引的名称。 不需要进行其他修改,因此准备就绪后便可运行代码。
此代码导入多个包并设置对此工作流中使用的 Azure 资源的访问权限。
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
步骤 3:将数据加载到 Spark 中
将以下代码粘贴到第二个单元格中。 无需修改,因此准备就绪后便可运行代码。
此代码从 Azure 存储帐户加载一些外部文件。 这些文件是各种发票,可读入数据帧。
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
步骤 4:添加文档智能
将以下代码粘贴到第三个单元格中。 无需修改,因此准备就绪后便可运行代码。
此代码加载 AnalyzeInvoices 转换器,并传递对包含发票的数据帧的引用。 它调用 Azure AI 文档智能的预建发票模型,以从发票中提取信息。
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
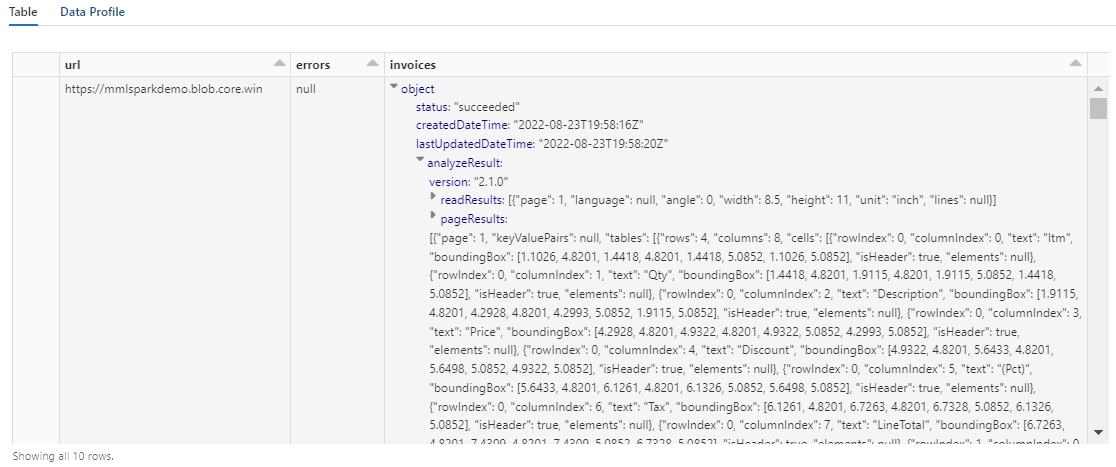
display(analyzed_df)
此步骤的输出应如下个屏幕截图所示。 请注意表单分析如何打包成难处理的密集结构化列。 下一个转换通过将列解析为行和列来解决此问题。
步骤 5:重构文档智能输出
将以下代码粘贴到第四个单元格并运行。 无需进行任何修改。
此代码加载 FormOntologyLearner,这是一个分析文档智能转换器的输出并推断表格数据结构的转换器。 AnalyzeInvoices 的输出是动态的,具体因内容中检测到的特征而异。 此外,转换器将输出合并到单个列中。 由于输出是动态的且是合并的,因此很难在需要更多结构的下游转换中使用该输出。
FormOntologyLearner 通过查找可用于创建表格数据结构的模式扩展了 AnalyzeInvoices 转换器的实用性。 通过将输出组织成多列和多行,使内容可供在其他转换器(例如 AzureSearchWriter)中使用。
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
请注意,此转换如何将嵌套字段重新广播到一个表中,从而启用接下来的两个转换。 为了简洁起见,此屏幕截图已剪裁。 如果使用自己的笔记本继续操作,你将有 19 列和 26 行。
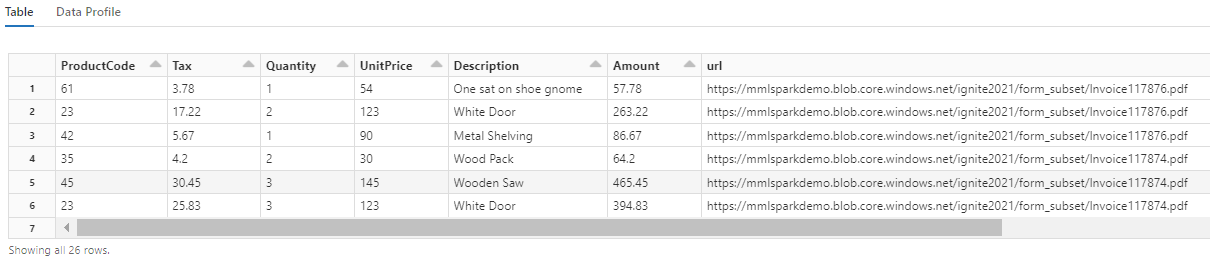
步骤 6:添加翻译
将以下代码粘贴到第五个单元格中。 无需修改,因此准备就绪后便可运行代码。
此代码加载 Translate,这是一个调用 Azure AI 服务中的 Azure AI 翻译服务的转换器。 “说明”一列的英文原文被机器翻译成各种语言。 所有输出都合并到“output.translations”数组中。
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
提示
若要查看已翻译的字符串,请滚动到行的末尾。
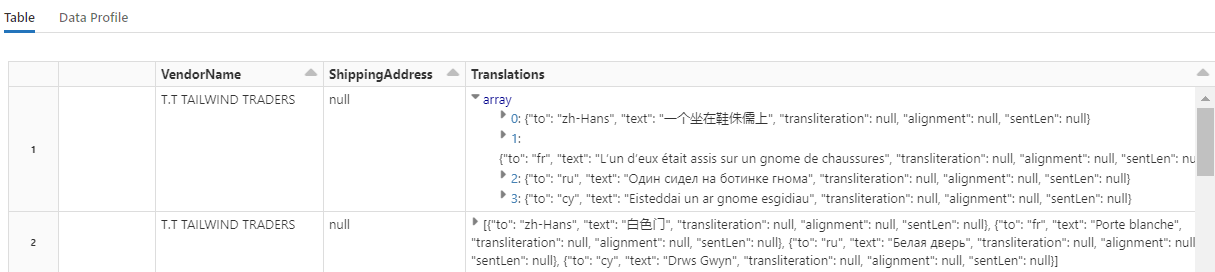
步骤 7:使用 AzureSearchWriter 添加搜索索引
将以下代码粘贴到第六个单元格中,然后运行它。 无需进行任何修改。
此代码加载 AzureSearchWriter。 它使用表格数据集,并推断一个搜索索引架构,该架构为每个列定义一个字段。 翻译结构是一个数组,因此它在索引中被表述为一个复杂的集合,其中每个语言翻译都有子字段。 生成的索引具有文档键,并使用通过创建索引 REST API 创建的字段的默认值。
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
可以查看 Azure 门户中的搜索服务页面,以探索由 AzureSearchWriter 创建的索引定义。
注意
如果不能使用默认搜索索引,可以在 JSON 中提供外部自定义定义,将其 URI 作为字符串传递到“indexJson”属性中。 首先生成默认索引,以确保知道要指定哪些字段,然后生成自定义属性,例如在需要特定分析器时生成自定义属性。
步骤 8:查询索引
将以下代码粘贴到第七个单元格中,然后运行它。 无需进行任何修改,但你可能希望更改语法或尝试更多示例以进一步探索你的内容:
没有发出查询的转换器或模块。 此单元格是对搜索文档 REST API 的简单调用。
此特定示例搜索“door”一词 ("search": "door")。 它还返回匹配文档的“计数”,并只为结果选择“说明”和“翻译”字段的内容。 如果要查看字段的完整列表,请删除“select”参数。
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2024-07-01".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
以下屏幕截图显示示例脚本的单元格输出。

清理资源
在自己的订阅中操作时,最好在项目结束时删除不再需要的资源。 持续运行资源可能会产生费用。 可以逐个删除资源,也可以删除资源组以删除整个资源集。
可以使用左侧导航窗格中的“所有资源”或“资源组”链接在 Azure 门户中查找和管理资源。
后续步骤
本教程介绍 SynapseML 中的 AzureSearchWriter转换器,这是一种在 Azure AI 搜索中创建和加载搜索索引的新方法。 此转换器采用结构化 JSON 作为输入。 FormOntologyLearner 可以为 SynapseML 中的文档智能转换器生成的输出提供必要的结构。
下一步,请查看其他 SynapseML 教程,这些教程可生成你想要通过 Azure AI 搜索来探索的转换内容: