你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
多租户 SaaS 应用程序与 Azure AI 搜索的设计模式
多租户应用程序可以为无法看到或共享任何其他租户数据的任意数量的租户,提供相同服务和功能。 本文讨论的租户隔离策略适用于使用 Azure AI 搜索生成的多租户应用程序。
Azure AI 搜索概念
作为一种搜索即服务解决方案,Azure AI 搜索允许开发人员将丰富的搜索体验添加到应用程序中,而无需管理任何基础结构,或者成为信息检索方面的专家。 数据上载到服务,并存储在云中。 通过对 Azure AI 搜索 API 发出简单请求,即可修改和搜索数据。
搜索服务、索引、字段和文档
在讨论设计模式之前,应务必了解一些基本概念。
使用 Azure AI 搜索时,即已订阅一种搜索服务。 当数据上传到 Azure AI 搜索后,将存储在搜索服务内的一个索引中。 单个服务中可能有大量索引。 若要利用熟悉的数据库概念,搜索服务可以比作一个数据库,而服务中的索引可以比作数据库中的表。
搜索服务中的每个索引具有自己的架构,由大量的可自定义字段定义。 数据以各文档的形式添加到 Azure AI 搜索索引中。 每个文档都必须上传到一个特定索引,并且必须适合该索引的架构。 使用 Azure AI 搜索进行数据搜索时,将针对某个特定索引发出全文搜索查询。 若要与数据库中的概念进行比较,字段可以比作表中的列,文档可以比作行。
可伸缩性
标准定价层中的任何 Azure AI 搜索服务都可以在两个维度中缩放:存储和可用性。
- 可以添加分区以便增加搜索服务的存储。
- 可以将副本添加到服务中,以便增加搜索服务可处理请求的吞吐量。
添加和删除分区以及副本,可使搜索服务的容量随着应用程序需要的大量数据和流量一起增加。 为了使搜索服务实现读取 SLA,需要两个副本。 为了使服务实现读写 SLA,需要三个副本。
Azure AI 搜索中的服务和索引限制
Azure AI 搜索中有一些不同的定价层,每一层都有不同的限制和配额。 有一些限制位于服务级别,有一些位于索引级别,还有一些位于分区级别。
S3 高密度
在 Azure AI 搜索的 S3 定价层中,有一个专门为多租户方案设计的高密度 (HD) 模式的选项。 在许多情况下,都有必要支持单个服务下的大量较小租户,从而获得简洁性和成本效益带来的优势。
S3 HD 通过以使用分区扩展索引的能力,换得在单个服务中承载更多索引的能力,允许多个小索引在单个搜索服务中填满并受其管理。
S3 服务旨在托管固定数量的索引(最多 200 个),并允许每个索引在新分区添加到服务时大小水平缩放。 向 S3 HD 服务添加分区会增加服务可托管的最大索引数。 尽管系统对每个索引都没有硬性大小限制,但是单个 S3HD 索引的理想最大大小约为 50 - 80 GB。
多租户应用程序注意事项
多租户应用程序必须在租户之间高效分配资源,同时在各租户之间保持一定程度的隐私。 设计此类应用程序的体系结构时需要了解几个注意事项:
租户隔离: 应用程序开发人员需要采取适当措施,确保任何租户都无法对其他租户的数据进行未经授权或未经允许的访问。 从数据隐私的角度之上来看,租户隔离策略需要有效管理共享资源并且避免受到干扰性邻户影响。
云资源成本: 与任何其他应用程序一样,软件解决方案必须将保持成本竞争力作为多租户应用程序的一部分考虑。
操作易用性: 开发多租户体系结构时,对应用程序操作和复杂性的影响是一个重要的考虑因素。 Azure AI 搜索具有 99.9% SLA。
全球分布:多租户应用程序经常需要为分布在全球范围内的租户提供服务。
可伸缩性: 应用程序开发人员需要考虑如何在以下二者之间进行协调:保持应用程序复杂性级别足够低,以及所设计的应用程序可随着租户数量和租户数据与工作负荷大小的增加而进行扩展。
Azure AI 搜索提供几个可用于隔离租户数据和工作负载的边界。
使用 Azure AI 搜索对多组织建模
对于多租户方案,应用程序开发人员使用一个或多个搜索服务,并在各服务和/或各索引中划分其租户。 Azure AI 搜索具有一些适用于对多租户方案建模的常见模式:
每个租户一个索引:每个租户都在搜索服务中有自己的索引,可与其他租户共享。
每个租户一个服务:每个租户都有自己专用的 Azure AI 搜索服务,从而提供最高级别的数据和工作负载分隔。
二者混合: 为较大、活跃度较高的租户分配专用服务,而为较小的租户分配共享服务中的单个索引。
模型 1:每个租户一个索引
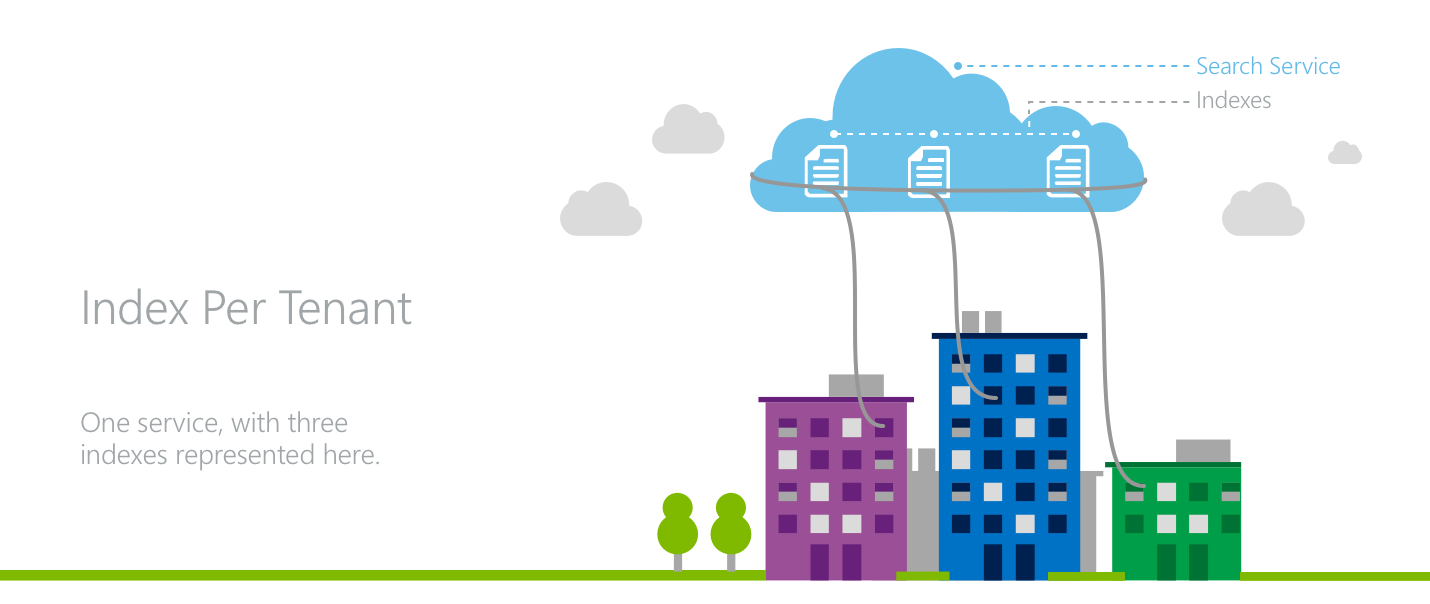
在每租户索引模型中,多个租户占用一个 Azure AI 搜索服务,其中每个租户拥有自己的索引。
租户实现数据隔离,因为所有搜索请求和文档操作都在 Azure AI 搜索的索引级别发出。 在应用程序层中,要带着需求意识将各租户的流量定向到正确的索引,同时还要跨所有租户在服务级别上管理资源。
每租户索引模型的一个关键特性是应用程序开发人员能够在应用程序的租户之间超额订阅搜索服务容量。 如果租户的工作负载分布不均,最佳租户组合可以是跨搜索服务索引分布,以便容纳大量高度活跃的资源密集型租户,同时又能够为活跃度较低但具有长尾效应的租户提供服务。 弊端是模型无法处理每个租户同时高度活跃的情况。
每租户索引模型为可变成本模型提供基础,在该模型中,预先提供整个 Azure AI 搜索服务,随后再填充租户。 这样可以为试用和免费帐户指定未使用的容量。
对于全球分布的应用程序,每租户索引模型可能不是最有效的。 如果应用程序的租户在全球分布,那么每个区域可能都需要一个单独的服务,而每个都会叠加成本。
Azure AI 搜索允许各索引和索引总数的规模增加。 如果选择相应的定价层,当服务中的单个索引在存储或流量方面增长到过于庞大时,可以向整个搜索服务增加分区和副本。
如果索引总数对于单个服务而言增长过高,另一个服务必须预配为能够容纳新租户。 如果当新服务添加后,必须在搜索服务之间移动索引,索引中的数据必须以手动方式从一个索引复制到另一个中,因为 Azure AI 搜索不允许移动索引。
模型 2:每个租户一个服务
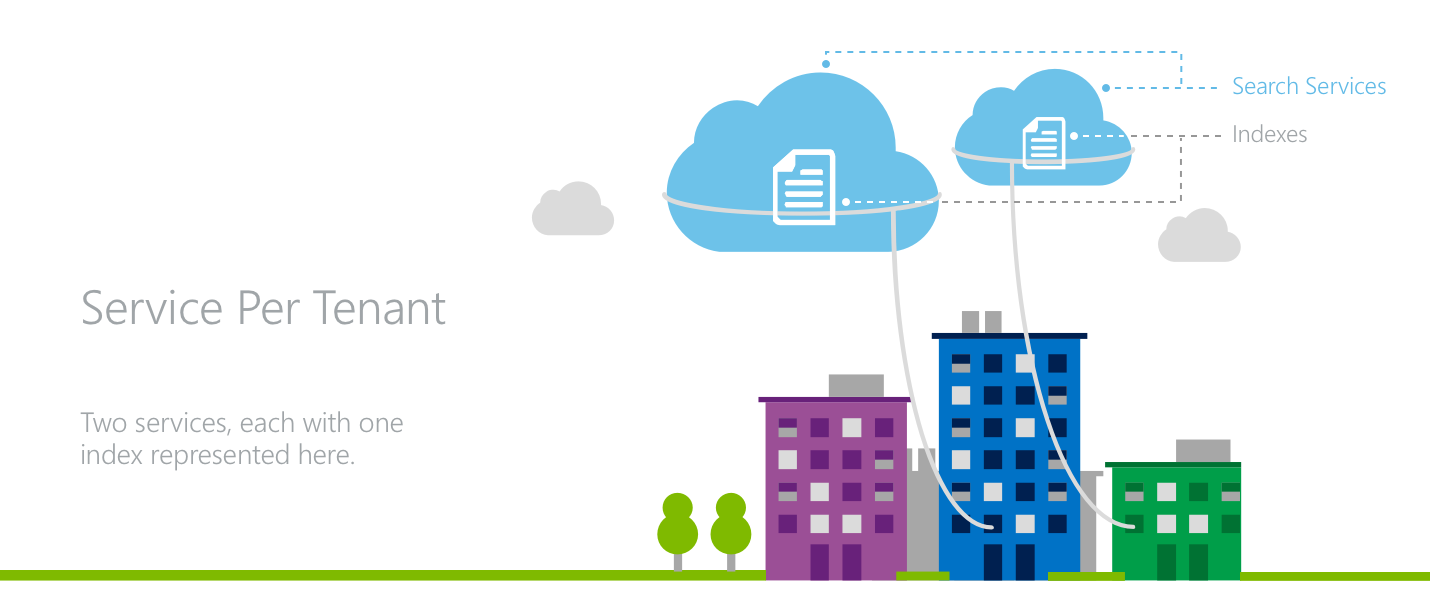
在每租户服务体系结构中,每个租户都有自己的搜索服务。
在此模型中,应用程序为其租户实现最高隔离级别。 每个服务都有专用存储和吞吐量,用于处理搜索请求。 每个租户都拥有 API 密钥的单独所有权。
对于每个租户具有较大分布范围或租户与租户之间工作负载差异不大的应用程序而言,每租户服务模型是一个有效的选择,因为资源不在各租户的工作负载之间共享。
每租户服务模型还提供可预测、成本固定模型的优势。 在填充租户之前,无需在整个搜索服务中进行前期投资,但是每租户成本高于每租户索引模型。
每租户服务模型对于全球分布的应用程序而言是一种高效选择。 对于地域分布式租户,很难在相应的区域中让每个租户都拥有服务。
当各租户发展过快使其服务不再适用时,扩展此模式将遇到困难。 Azure AI 搜索当前不支持升级搜索服务的定价层,因此所有数据都需要以手动方式复制到新服务中。
模型 3:混合
另一种对多组织建模的模式是混合使用每租户索引和每租户服务策略。
通过混合使用这两种模式,应用程序的最大租户可以占用专用服务,而活跃度较低且具有长尾效应的较小租户可以占用共享服务中的索引。 此模型可确保最大租户持续享有服务的高性能,同时帮助较小租户避免受到干扰性邻户的影响。
但是,实现此策略依赖于远见性,要预测哪些租户将需要专用服务,哪些将需要共享服务中的索引。 应用程序复杂性随着这两种多组织模型的管理需求而增长。
实现更精细的粒度
在 Azure AI 搜索中进行多租户建模方案的以上设计模式假定了一个统一的范围,其中每个租户都是应用程序的一个完整实例。 但是,应用程序有时可能处理多个较小的范围。
如果每租户服务和每租户索引模型不是足够小的范围,则无法对索引建模以实现更精细的粒度。
若要使单个索引的行为与其他客户端终结点有所不同,可以向索引添加字段,为每个可能的客户端指定某个值。 每次客户端调用 Azure AI 搜索查询或修改索引时,客户端应用程序的代码都在查询时使用 Azure AI 搜索的筛选功能为该字段指定相应值。
此方法可用于实现单独用户帐户的功能、分隔权限级别甚至完全分隔应用程序。
注意
如果使用上面介绍的方法将单个索引配置为为多个租户提供服务,将影响搜索结果的相关性。 搜索相关性分数在索引级范围(而不是租户级范围)内计算,因此所有租户的数据都纳入相关性分数的基础统计数据(如术语频率)。
后续步骤
对于许多应用程序而言,Azure AI 搜索是极具吸引力的选项。 评估多租户应用程序的各个设计模式时,请考虑各个定价层和各自的服务限制,定制最合适的 Azure AI 搜索以满足所有大小的应用程序工作负载和体系结构需求。