你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 Azure 中的 Red Hat Enterprise Linux 上设置 Pacemaker
本文介绍如何在 Red Hat Enterprise Server (RHEL) 上配置基本 Pacemaker 群集。 这些说明涵盖 RHEL 7、RHEL 8 和 RHEL 9。
先决条件
请先阅读以下 SAP 说明和文章:
RHEL 高可用性 (HA) 文档
Azure 特定的 RHEL 文档
SAP 产品/服务的 RHEL 文档
概述
重要
标准支持策略未涵盖跨多个虚拟网络 (VNets)/子网的 Pacemaker 群集。
Azure 上有两个选项可用于为 RHEL 配置 Pacemaker 群集中的隔离:Azure 围栏代理(它通过 Azure API 重启故障节点),或者你可以使用 SBD 设备。
重要
在 Azure 中,具有基于存储的隔离 (fence_sbd) 的 RHEL 高可用性群集使用软件模拟监视器。 选择 SBD 作为围栏机制时,请务必查看软件模拟监视器已知限制和 RHEL 高可用性群集的支持策略 - sbd 和fence_sbd。
使用 SBD 设备
注意
RHEL 8.8 及更高版本以及 RHEL 9.0 及更高版本支持采用 SBD 的隔离机制。
可以使用以下两个选项之一配置 SBD 设备:
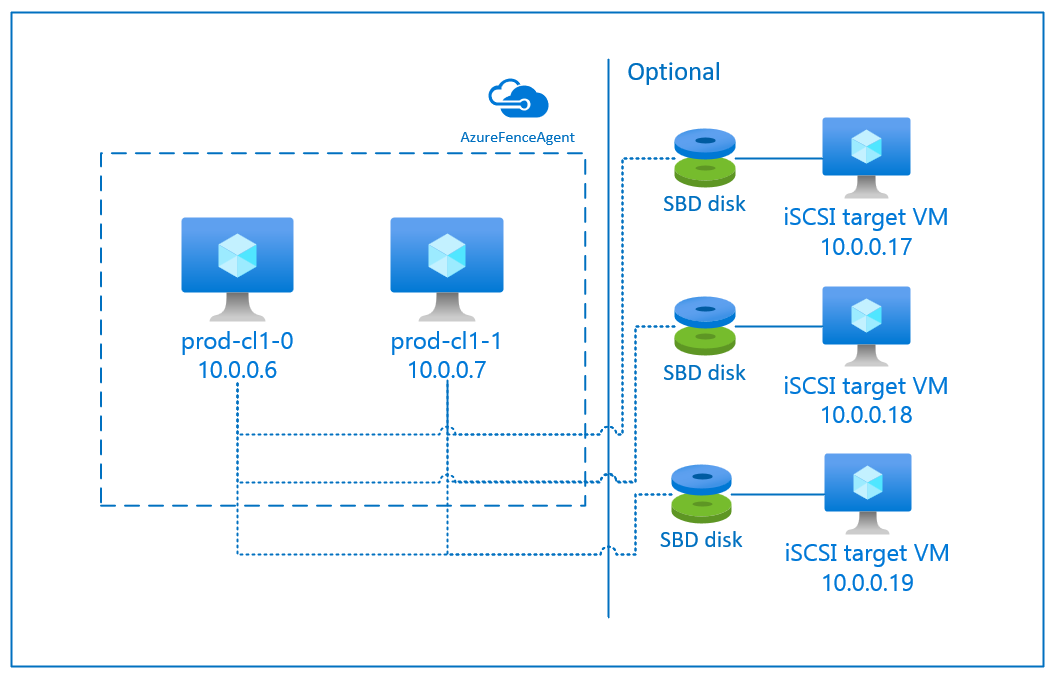
具有 iSCSI 目标服务器的 SBD
SBD 设备至少需要一台额外的充当 Internet 小型计算机系统接口 (iSCSI) 目标服务器并提供 SBD 设备的虚拟机 (VM)。 不过,也可以与其他 Pacemaker 群集共享这些 iSCSI 目标服务器。 使用 SBD 设备的优点是(如果已经在本地使用 SBD 设备)不需要对操作 Pacemaker 群集的方式进行任何更改。
最多可对一个 Pacemaker 群集使用三个 SBD 设备,以允许某个 SBD 设备不可用(例如,在修补 iSCSI 目标服务器的 OS 期间)。 若要对每个 Pacemaker 使用多个 SBD 设备,请务必部署多个 iSCSI 目标服务器并从每个 iSCSI 目标服务器连接一个 SBD。 我们建议使用一个或三个 SBD 设备。 如果仅配置了两个 SBD 设备,并且其中一个 SBD 设备不可用,则 Pacemaker 无法自动隔离群集节点。 当一个 iSCSI 目标服务器关闭时,若要进行隔离,必须使用三个 SBD 设备,因此需要使用三个 iSCSI 目标服务器。 使用 SBD 时,这是复原能力最强的配置。
重要
在规划如何部署和配置 Linux Pacemaker 群集节点和 SBD 设备时,不允许虚拟机与托管 SBD 设备的 VM 之间的路由通过任何其他设备(例如网络虚拟设备 (NVA))。
NVA 维护事件和其他问题可能会对整个群集配置的稳定性和可靠性产生负面影响。 有关详细信息,请参阅用户定义的路由规则。
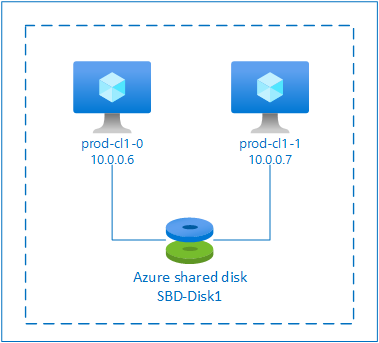
采用 Azure 共享磁盘的 SBD
要配置 SBD 设备,需要至少将一个 Azure 共享磁盘附加到 Pacemaker 群集中的所有虚拟机。 使用 Azure 共享磁盘的 SBD 设备的优点是无需部署和配置其他虚拟机。
下面是使用 Azure 共享磁盘进行配置时有关 SBD 设备的一些重要注意事项:
- 支持将带有高级 SSD 的 Azure 共享磁盘作为 SBD 设备。
- RHEL 8.8 及更高版本支持使用 Azure 共享磁盘的 SBD 设备。
- 本地冗余存储 (LRS) 和区域冗余存储 (ZRS) 支持使用 Azure 高级共享磁盘的 SBD 设备。
- 根据部署类型,为 Azure 共享磁盘选择适当的冗余存储作为 SBD 设备。
- 只有区域性部署(例如可用性集)支持使用 Azure 高级共享磁盘 LRS (skuName - Premium_LRS) 的 SBD 设备。
- 建议对区域性部署(例如,可用性区域,或 FD=1 的规模集)使用 Azure 高级共享磁盘 ZRS (skuName - Premium_ZRS) 的 SBD 设备。
- 托管磁盘的 ZRS 目前在区域可用性文档中列出的区域中可用。
- 用于 SBD 设备的 Azure 共享磁盘不需要很大。 maxShares 值确定可使用共享磁盘的群集节点数。 例如,可在 SAP ASCS/ERS 或 SAP HANA 纵向扩展等双节点群集上为 SBD 设备使用 P1 或 P2 磁盘大小。
- 对于 HANA 系统复制 (HSR) 和 Pacemaker 的 HANA 横向扩展,由于 maxShares 的当前限制,可在群集中为 SBD 设备使用 Azure 共享磁盘,群集在每个复制站点最多具有 5 个节点。
- 建议不要跨 Pacemaker 群集附加 Azure 共享磁盘 SBD 设备。
- 如果使用多个 Azure 共享磁盘 SBD 设备,请检查可附加到 VM 的数据磁盘数目上限。
- 若要详细了解 Azure 共享磁盘的限制,请仔细阅读 Azure 共享磁盘文档的“限制”部分。
使用 Azure 隔离代理
可以使用 Azure 隔离代理设置隔离。 Azure 隔离代理需要群集 VM 的托管标识,或需要一个设法通过 Azure API 重启故障节点的服务主体或托管系统标识 (MSI)。 Azure 隔离代理不需要部署额外的虚拟机。
具有 iSCSI 目标服务器的 SBD
若要使用通过 iSCSI 目标服务器进行隔离的 SBD 设备,请按照后续部分中的说明进行操作。
设置 iSCSI 目标服务器
首先需要创建 iSCSI 目标虚拟机。 你可以与多个 Pacemaker 群集共享 iSCSI 目标服务器。
部署在受支持的 RHEL OS 版本上运行的虚拟机,并通过 SSH 连接到它们。 VM 不必很大。 Standard_E2s_v3 或 Standard_D2s_v3 这样的 VM 大小就足够了。 务必为 OS 磁盘使用高级存储。
不必为 iSCSI 目标服务器使用包含 HA 和更新服务的 RHEL for SAP,也不必为其使用 RHEL for SAP Apps OS 映像。 可以改用标准 RHEL OS 映像。 但请注意,支持生命周期因 OS 产品版本而异。
在所有 iSCSI 目标虚拟机上运行以下命令。
更新 RHEL。
sudo yum -y update注意
升级或更新 OS 后,可能需要重新启动节点。
安装 iSCSI 目标包。
sudo yum install targetcli启动并将目标配置为在系统启动时启动。
sudo systemctl start target sudo systemctl enable target在防火墙中打开端口
3260sudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
在 iSCSI 目标服务器上创建 iSCSI 设备
若要为 SAP 系统群集创建 iSCSI 磁盘,请在每个 iSCSI 目标虚拟机上执行以下命令。 此示例展示了为多个群集创建 SBD 设备,演示了如何将单个 iSCSI 目标服务器用于多个群集。 SBD 设备是在 OS 磁盘上配置的,因此请确保有足够的空间。
- ascsnw1:表示 NW1 的 ASCS/ERS 群集。
- dbhn1:表示 HN1 的数据库群集。
- sap-cl1 和 sap-cl2:NW1 ASCS/ERS 群集节点的主机名。
- hn1-db-0 和 hn1-db-1:数据库群集节点的主机名。
在下面的说明中,请根据需要修改命令,使用你的特定主机名和 SID 进行替换。
为所有 SBD 设备创建根文件夹。
sudo mkdir /sbd为 NW1 系统的 ASCS/ERS 服务器创建 SBD 设备。
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2为 HN1 系统的数据库群集创建 SBD 设备。
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1保存 targetcli 配置。
sudo targetcli saveconfig进行检查以确保一切设置正确
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
设置 iSCSI 目标服务器 SBD 设备
[A]:适用于所有节点。 [1]:仅适用于节点 1。 [2]:仅适用于节点 2。
在群集节点上,连接并发现在前面的部分中创建的 iSCSI 设备。 在要创建的新群集的节点上运行以下命令。
[A] 在所有群集节点上安装或更新 iSCSI 发起程序实用工具。
sudo yum install -y iscsi-initiator-utils[A] 在所有群集节点上安装群集和 SBD 包。
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] 启用 iSCSI 服务。
sudo systemctl enable iscsid iscsi[1] 在群集的第一个节点上更改发起程序名称。
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] 在群集的第二个节点上更改发起程序名称。
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] 重启 iSCSI 服务以应用更改。
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] 连接 iSCSI 设备。 在下面的示例中,10.0.0.17 是 iSCSI 目标服务器的 IP 地址,3260 是默认端口。 运行第一个命令
iscsiadm -m discovery时,目标名称iqn.2006-04.ascsnw1.local:ascsnw1会被列出。sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] 如果你使用多个 SBD 设备,请同时连接到第二个 iSCSI 目标服务器。
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] 如果你使用多个 SBD 设备,请同时连接到第三个 iSCSI 目标服务器。
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] 请确保 iSCSI 设备可用并记下设备名称。 在以下示例中,通过将节点连接到三个 iSCSI 目标服务器来发现三个 iSCSI 设备。
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] 检索 iSCSI 设备的 ID。
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg此命令会列出每个 SBD 设备的三个设备 ID。 建议使用以 scsi-3 开头的 ID。 在前面的示例中,这些 ID 为:
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] 创建 SBD 设备。
使用 iSCSI 设备的设备 ID 在第一个群集节点上创建新的 SBD 设备。
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 create如果要使用多个 SBD 设备,请创建第二个和第三个 SBD 设备。
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] 调整 SBD 配置
打开 SBD 配置文件。
sudo vi /etc/sysconfig/sbd更改 SBD 设备的属性,启用 pacemaker 集成,并更改 SBD 的启动模式。
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] 运行以下命令以加载
softdog模块。modprobe softdog[A] 运行以下命令,以确保在节点重启后自动加载
softdog。echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] SBD 服务超时值默认设置为 90 秒。 但是,如果将
SBD_DELAY_START值设置为yes,SBD 服务将延迟其启动,直到msgwait超时后。 因此,启用了SBD_DELAY_START时,SBD 服务超时值应超过msgwait超时值。sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
具有 Azure 共享磁盘的 SBD
本部分仅适用于要使用具有 Azure 共享磁盘的 SBD 设备的情况。
使用 PowerShell 配置 Azure 共享磁盘
若要使用 PowerShell 创建和附加 Azure 共享磁盘,请执行以下指令。 如果要使用 Azure CLI 或 Azure 门户部署资源,也可参阅部署 ZRS 磁盘。
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
设置 Azure 共享磁盘 SBD 设备
[A] 在所有群集节点上安装群集和 SBD 包。
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] 确保附加的磁盘可用。
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] 检索附加的共享磁盘的设备 ID。
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sda此命令列出附加的共享磁盘的设备 ID。 建议使用以 scsi-3 开头的 ID。 在此示例中,ID 为 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107。
[1] 创建 SBD 设备
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] 调整 SBD 配置
打开 SBD 配置文件。
sudo vi /etc/sysconfig/sbd更改 SBD 设备的属性,启用 Pacemaker 集成,并更改 SBD 的启动模式
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] 运行以下命令以加载
softdog模块。modprobe softdog[A] 运行以下命令,以确保在节点重启后自动加载
softdog。echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] SBD 服务超时值默认设置为 90 秒。 但是,如果将
SBD_DELAY_START值设置为yes,SBD 服务将延迟其启动,直到msgwait超时后。 因此,启用了SBD_DELAY_START时,SBD 服务超时值应超过msgwait超时值。sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Azure 隔离代理配置
隔离设备使用 Azure 资源托管标识或服务主体来对 Azure 授权。 根据标识管理方法,遵循相应的过程 -
配置标识管理
使用托管标识或服务主体。
为隔离代理创建自定义角色
默认情况下,托管标识和服务主体都无权访问 Azure 资源。 需要为托管标识或服务主体授予启动和停止(关闭)群集所有 VM 的权限。 如果尚未创建自定义角色,可以使用 PowerShell 或 Azure CLI 创建。
将以下内容用于输入文件。 你需要根据订阅调整内容,即将
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx和yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy替换为订阅的 ID。 如果只有一个订阅,请删除AssignableScopes中的第二个条目。{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }分配自定义角色
使用托管标识或服务主体。
将上一部分中创建的自定义角色
Linux Fence Agent Role分配给群集 VM 的每个托管标识。 每个 VM 系统分配的托管标识都需要为每个群集 VM 资源分配的角色。 有关详细信息,请参阅使用 Azure 门户为托管标识分配对资源的访问权限。 验证每个 VM 的托管标识角色分配是否包含所有群集 VM。重要
请注意,使用托管标识分配和删除授权可能会延迟,直到生效。
群集安装
文档中标记了 RHEL 7 和 RHEL 8/RHEL 9 之间有关命令或配置的差异。
[A] 安装 RHEL HA 附加产品。
sudo yum install -y pcs pacemaker nmap-ncat[A] 在 RHEL 9.x 上,为云部署安装资源代理。
sudo yum install -y resource-agents-cloud[A] 如果你使用基于 Azure 隔离代理的隔离设备,请安装 fence-agents 包。
sudo yum install -y fence-agents-azure-arm重要
对于希望将 Azure 资源托管标识而不是服务主体名称用于隔离代理的客户,建议使用以下版本的 Azure 隔离代理(或更高版本):
- RHEL 8.4:fence-agents-4.2.1-54.el8。
- RHEL 8.2:fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1:fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9:fence-agents-4.2.1-41.el7_9.4。
重要
在 RHEL 9 上,建议使用以下包版本(或更高版本),以避免 Azure 隔离代理出现问题:
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
检查 Azure 隔离代理的版本。 如有必要,请将其更新为所需的最低版本或更高版本。
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-arm重要
如果需要使用自定义角色更新 Azure 隔离代理,请确保更新自定义角色来将关闭操作包含在内。 有关详细信息,请参阅为围栏代理创建自定义角色。
[A] 设置主机名解析。
可以使用 DNS 服务器,或修改所有节点上的
/etc/hosts文件。 此示例演示如何使用/etc/hosts文件。 请替换以下命令中的 IP 地址和主机名。重要
如果在群集配置中使用主机名,则必须具有可靠的主机名解析。 如果名称不可用,群集通信就会失败,这可能会导致群集故障转移延迟。
使用
/etc/hosts的好处是群集可以不受 DNS 影响,DNS 也可能会成为单一故障点。sudo vi /etc/hosts将以下行插入
/etc/hosts中。 根据环境更改 IP 地址和主机名。# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A] 将
hacluster密码更改为同一密码。sudo passwd hacluster[A] 为 Pacemaker 添加防火墙规则。
向群集节点之间的所有群集通信添加以下防火墙规则。
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] 启用基本群集服务。
运行以下命令以启用并启动 Pacemaker 服务。
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] 创建 Pacemaker 群集。
运行以下命令以验证节点并创建群集。 将令牌设置为 30000,以允许内存保留维护。 有关详细信息,请参阅这篇适用于 Linux 的文章。
如果在 RHEL 7.x 上构建群集,请使用以下命令:
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --all如果在 RHEL 8.x/RHEL 9.x 上构建群集,请使用以下命令:
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --all运行以下命令验证群集状态:
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] 设置预期投票。
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2提示
如果要构建多节点群集(即节点数超过两个的群集),请不要将投票数设置为 2。
[1] 允许并发隔离操作。
sudo pcs property set concurrent-fencing=true
在 Pacemaker 群集上创建隔离设备
提示
- 若要避免双节点 Pacemaker 群集内的隔离争用,可以配置
priority-fencing-delay群集属性。 当发生分脑方案时,此属性会在隔离具有较高总资源优先级的节点时引入额外的延迟。 有关详细信息,请参阅 Pacemaker 是否可以隔离运行最少资源的群集节点?。 - 属性
priority-fencing-delay适用于 Pacemaker 版本 2.0.4-6.el8 或更高版本,并且适用于双节点群集。 如果配置priority-fencing-delay群集属性,则无需设置pcmk_delay_max属性。 但是,如果 Pacemaker 版本低于 2.0.4-6.el8,则需要设置pcmk_delay_max属性。 - 有关如何设置
priority-fencing-delay群集属性的说明,请参阅相应的 SAP ASCS/ERS 和 SAP HANA 纵向扩展 HA 文档。
根据所选隔离机制,仅按照相关说明的一个部分进行操作:SBD 作为隔离设备或 Azure 隔离代理作为隔离设备。
SBD 作为隔离设备
[A] 启用 SBD 服务
sudo systemctl enable sbd[1] 对于使用 iSCSI 目标服务器或 Azure 共享磁盘配置的 SBD 设备,请运行以下命令。
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] 重启群集
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --all注意
如果在启动 Pacemaker 群集时遇到以下错误,则可以忽略该消息。 另外,还可以使用
pcs cluster start --all --request-timeout 140命令启动群集。错误:无法启动所有节点 node1/node2:无法连接到 node1/node2,请检查 pcsd 是否正在运行,或者尝试通过
--request-timeout选项设置更高的超时(操作已在 60000 毫秒后超时,收到 0 个字节)
Azure 隔离代理作为隔离设备
[1] 将角色分配给两个群集节点后,你可在群集中配置隔离设备。
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] 运行相应的命令,具体取决于是使用 Azure 隔离代理的托管标识还是服务主体。
注意
使用 Azure 政府云时,必须在配置围栏代理时指定
cloud=选项。 例如,Azure 美国政府云cloud=usgov。 有关 Azure 政府云上的 RedHat 支持的详细信息,请参阅 RHEL 高可用性群集的支持策略 - Microsoft Azure 虚拟机作为群集成员。提示
如果 RHEL 主机名和 Azure VM 名称不相同,则命令中仅需要选项
pcmk_host_map。 以 hostname:vm-name 格式指定映射。 有关详细信息,请参阅应使用哪种格式在 pcmk_host_map 中指定节点到隔离设备的映射?。对于 RHEL 7.x,请使用以下命令配置隔离设备:
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600对于 RHEL 8.x/9.x,请使用以下命令配置隔离设备:
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
如果使用的是基于服务主体配置的隔离设备,请阅读使用 Azure 隔离将 Pacemaker 群集从 SPN 更改为 MSI,并了解如何转换为托管标识配置。
对监视和隔离操作进行反序列化。 因此,如果存在运行时间较长的监视操作和同时发生的隔离事件,则群集故障转移不会延迟,因为监视操作已经在运行。
提示
Azure 隔离代理需要与公共终结点建立出站连接。 有关详细信息以及可能的解决方案,请参阅使用标准 ILB 的 VM 的公共终结点连接。
为 Azure 计划事件配置 Pacemaker
Azure 提供计划事件。 计划事件通过元数据服务发送,并可为应用程序留出时间为此类事件做准备。
Pacemaker 资源代理 azure-events-az 可监视计划的 Azure 事件。 如果检测到事件并且资源代理确定有另一个群集节点可用,则会设置群集运行状况属性。
为节点设置群集健康状况属性后,会触发位置约束,并且所有名称不以 health- 开头的资源将从具有计划事件的节点迁移走。 在受影响的群集节点没有正在运行的群集资源后,计划事件会得到确认,并且可以执行其操作(例如重启)。
[A] 确保已安装
azure-events-az代理的程序包,并且其版本是最新的。RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloud最低版本要求:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 及更新版本:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] 配置 Pacemaker 中的资源。
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] 设置 Pacemaker 群集健康状况节点策略和约束。
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'重要
除了后续步骤中所述的资源之外,不要定义群集中以
health-开头的任何其他资源。[1] 设置群集属性的初始值。 针对每个群集节点和横向扩展环境(包括多数制造商 VM)运行。
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] 配置 Pacemaker 中的资源。 确保资源以
health-azure开头。sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true failure-timeout=120s使 Pacemaker 群集退出维护模式。
sudo pcs property set maintenance-mode=false清除启用期间出现的任何错误,并验证
health-azure-events资源是否已在所有群集节点上成功启动。sudo pcs resource cleanup首次执行计划事件的查询最多可能需要 2 分钟。 计划事件的 Pacemaker 测试可以使用群集 VM 的重新启动或重新部署操作。 有关详细信息,请参阅计划事件。
可选隔离配置
提示
本部分仅适用于想要配置特殊隔离设备 fence_kdump 的情况。
如果需要在 VM 中收集诊断信息,则根据隔离代理 fence_kdump 配置额外的隔离设备可能很有用。 fence_kdump 代理可检测到节点进入了 kdump 故障恢复,并在调用其他隔离方法之前允许故障恢复服务完成。 请注意,在使用 Azure VM 时,fence_kdump 无法替代传统的隔离机制,例如 SBD 或 Azure 隔离代理。
重要
请注意,当 fence_kdump 被配置为第一级隔离设备时,它将分别引入隔离操作延迟和应用程序资源故障转移延迟。
如果成功检测到故障转储,隔离会延迟到故障恢复服务完成。 如果故障节点无法访问或未响应,则将按确定的时间、配置的迭代次数和 fence_kdump 超时时间延迟隔离。 有关详细信息,请参阅如何在 Red Hat Pacemaker 群集中配置 fence_kdump?。
建议的 fence_kdump 超时时间可能需要根据具体环境进行调整。
建议仅在需要收集 VM 内的诊断信息时才配置 fence_kdump 隔离,并且始终与 SBD 或 Azure 隔离代理等传统隔离方法结合使用。
以下 Red Hat 知识库文章包含有关如何配置 fence_kdump 隔离的重要信息:
- 请参阅如何在 Red Hat Pacemaker 群集中配置 fence_kdump?。
- 如何使用 Pacemaker 在 RHEL 群集中配置/管理隔离级别。
- 在 kexec-tools 版本低于 2.0.14 的 RHEL 6 或 7 HA 群集中,fence_kdump 失败并显示“X 秒后超时”。
- 若要了解如何更改默认超时,请参阅如何配置 kdump 以与 RHEL 6、7、8 HA 附加产品一起使用?。
- 若要了解如何在使用
fence_kdump时减少故障转移延迟,请参阅添加 fence_kdump 配置时是否可减少故障转移的预期延迟?。
除了 Azure 隔离代理配置,还可运行以下可选步骤来添加 fence_kdump 作为第一级隔离配置。
[A] 验证
kdump是否处于活动状态并已配置。systemctl is-active kdump # Expected result # active[A] 安装
fence_kdump隔离代理。yum install fence-agents-kdump[1] 在群集中创建
fence_kdump隔离设备。pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] 配置隔离级别,以便先启用
fence_kdump隔离机制。pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] 允许
fence_kdump所需的端口通过防火墙。firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A] 在
/etc/kdump.conf中执行fence_kdump_nodes配置,避免在某些kexec-tools版本中fence_kdump失败并显示超时。 有关详细信息,请参阅 kexec-tools 2.0.15 或更高版本没有指定 fence_kdump_nodes 时,fence_kdump 超时和在 kexec-tools 版本低于 2.0.14 的 RHEL 6 或 7 高可用性群集中,fence_kdump 失败并显示“X 秒后超时”。 此处提供了双节点群集的示例配置。 在/etc/kdump.conf中进行更改后,必须重新生成 kdump 映像。 若要重新生成,请重启kdump服务。vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A] 确保
initramfs映像文件包含fence_kdump和hosts文件。 有关详细信息,请参阅如何在 Red Hat Pacemaker 群集中配置 fence_kdump?。lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_send通过使节点故障来测试配置。 有关详细信息,请参阅如何在 Red Hat Pacemaker 群集中配置 fence_kdump?。
重要
如果群集已在生产环境中投入使用,请相应地计划测试,因为节点故障会影响应用程序。
echo c > /proc/sysrq-trigger
后续步骤
- 请参阅适用于 SAP 的 Azure 虚拟机规划和实施。
- 请参阅适用于 SAP 的 Azure 虚拟机部署。
- 请参阅适用于 SAP 的 Azure 虚拟机 DBMS 部署。
- 若要了解如何为 Azure VM 上的 SAP HANA 建立 HA 并规划灾难恢复,请参阅 Azure 虚拟机上的 SAP HANA 的高可用性。