你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Nebula 提高检查点速度并降低成本
了解如何使用 Nebula 提高大型 Azure 机器学习训练模型的检查点速度,降低检查点成本。
概述
Nebula 是适用于 PyTorch 的 Azure 容器 (ACPT) 中的一款快速、简单、无磁盘模型感知检查点工具。 Nebula 为使用 PyTorch 的分布式大规模模型训练作业提供简单、高速的检查点解决方案。 通过利用最新的分布式计算技术,Nebula 可以将检查点时间从几小时缩短到几秒,从而节省 95% 到 99.9% 的时间。 大规模训练作业可以极大地受益于 Nebula 的性能。
请在脚本中导入 nebulaml Python 包,训练作业才能使用 Nebula。 Nebula 与不同的分布式 PyTorch 训练策略完全兼容,包括 PyTorch Lightning、DeepSpeed 等。 Nebula API 提供简单的方式来监控和查看检查点生命周期。 API 支持各种模型类型,并可确保检查点的一致性和可靠性。
重要
nebulaml 包不能用于公共 PyPI Python 包索引。 该包仅在 Azure 机器学习上的适用于 PyTorch 的 Azure 容器 (ACPT) 特选环境中提供。 为了避免出现问题,请不要尝试从 PyPI 安装 nebulaml 或使用 pip 命令进行安装。
本文档介绍如何将 Nebula 与 Azure 机器学习上的 ACPT 配合使用,以快速检查模型训练作业。 此外,还会介绍如何查看和管理 Nebula 检查点数据。 你还将了解在遇到 Azure 机器学习中断、故障或终止时,如何从最近可用检查点恢复模型训练作业。
大型模型训练的检查点优化为什么重要
随着数据量的增长和数据格式变得越来越复杂,机器学习模型也变得更加复杂。 由于 GPU 内存容量限制和训练时间的漫长,训练这些复杂模型将是一道难题。 因此,在使用大型数据集和复杂模型时,通常会使用分布式训练。 但是,分布式体系结构可能会遇到意外故障和节点故障,随着机器学习模型中节点数量的增加,这些问题可能会越来越严重。
检查点可以通过在给定时间定期保存完整模型状态快照来帮助缓解这些问题。 如果发生故障,可以使用此快照将模型重新生成为快照时的状态,以便从该点恢复训练。
当大型模型训练操作遇到故障或终止时,数据科学家和研究人员可以从以前保存的检查点还原训练过程。 但是,检查点和终止之间的任何进度都将丢失,因为必须重新执行计算才能恢复未保存的中间结果。 更短的检查点间隔可以帮助降低这种损失。 此图说明了从检查点开始的训练过程与终止之间所浪费的时间:

但是,保存检查点本身的进程可能会产生巨大的开销。 保存 TB 大小的检查点通常会成为训练过程中的瓶颈,同步的检查点进程会阻塞训练数小时。 平均而言,检查点相关开销可占训练总时间的 12%,可升至 43%。(Maeng et al., 2021)。
总之,大型模型检查点管理涉及大量存储和作业恢复时间开销。 频繁保存检查点,加上从最近的可用检查点恢复训练作业,成为一项艰巨挑战。
Nebula 能够帮你应对
在有效训练大型的分布式模型时,务必要有可靠有效的方法保存和恢复训练过程,降低数据丢失和浪费资源。 Nebula 通过提供更快、更轻松的检查点管理,帮助减少大型模型 Azure 机器学习训练作业的检查点节省时间和 GPU 小时需求。
使用 Nebula,你可以:
通过一个与训练过程异步的简单 API,将检查点速度最高提升至 1000 倍。 Nebula 可以将检查点时间从几小时减少到几秒,最高可减少 95% 到 99%。
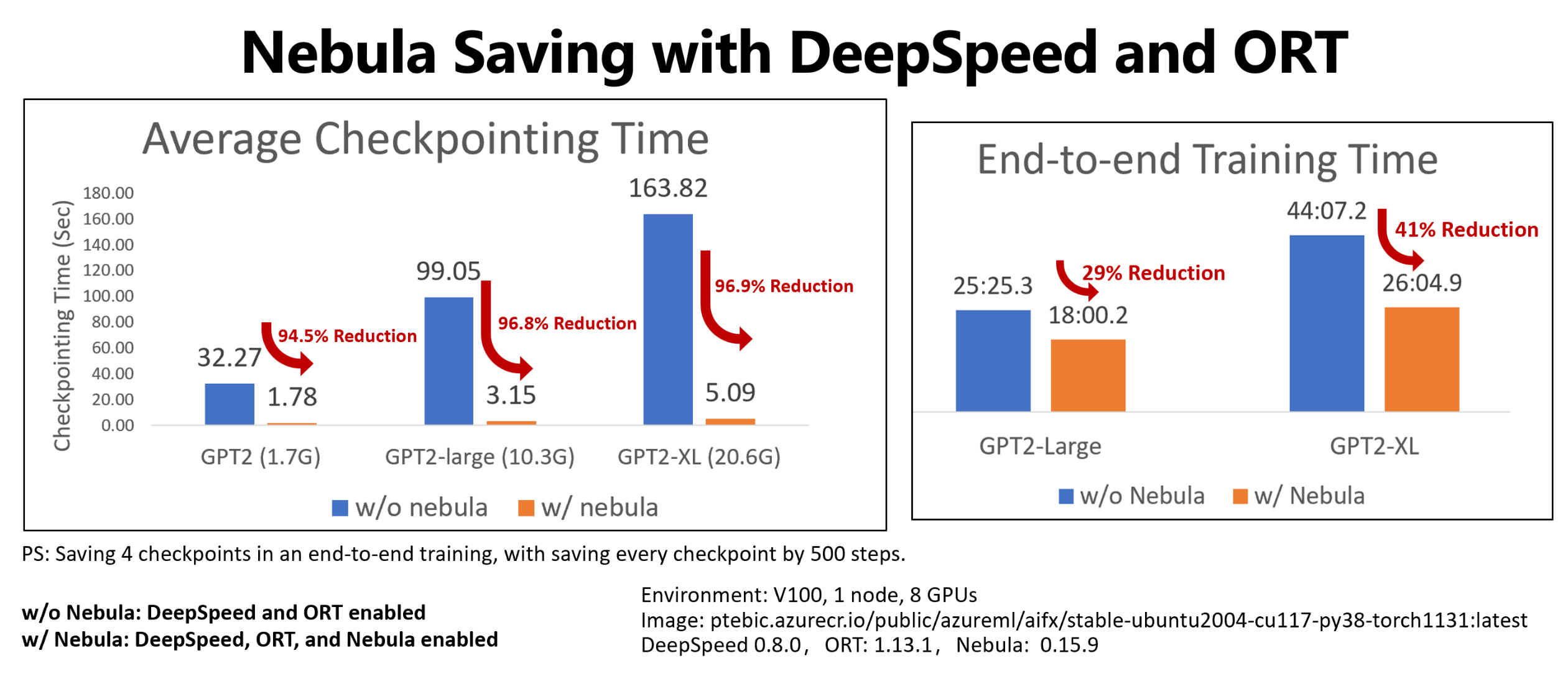
此示例展示了 Hugging Face GPT2、GPT2-Large 和 GPT-XL 训练作业的四个检查点在检查点和端到端训练方面节省的时间。 对于中型 Hugging Face GPT2-XL 检查点保存 (20.6 GB),Nebula 在每个检查点节省了 96.9% 的时间。
检查点速度增益仍会随着模型大小和 GPU 数量而增加。 例如,在 128 块 A100 英伟达 GPU 上测试保存 97GB 的训练点检查点的时间可以从 20 分钟缩短到 1 秒。
通过最大程度地减少检查点开销并减少在作业恢复上浪费的 GPU 小时数,减少大型模型的端到端训练时间和计算成本。 Nebula 异步保存检查点,并取消阻止训练过程,以缩短端到端训练时间。 此外,它还允许更频繁地保存检查点。 这样,可以在任何中断后从最近的检查点恢复训练,并节省在作业恢复和 GPU 训练时间上浪费的时间和金钱。
完全兼容 PyTorch。 Nebula 完全兼容 PyTorch,并提供与分布式训练框架(包括 DeepSpeed (>=0.7.3) 和 PyTorch Lightning (>=1.5.0) )的完全集成。 还可以将其用于不同的 Azure 机器学习计算目标,例如 Azure 机器学习计算或 AKS。
使用 Python 包帮助列出、获取、保存和加载检查点,轻松管理检查点。 为了显示检查点生命周期,Nebula 还提供有关 Azure 机器学习工作室的综合日志。 可以选择将检查点保存到本地或远程存储位置
- Azure Blob 存储
- Azure Data Lake Storage
- NFS
并随时通过几行代码访问检查点。

先决条件
- Azure 订阅和 Azure 机器学习工作区。 有关工作区资源创建的更多信息,请参阅创建工作区资源
- 一个 Azure 机器学习计算目标。 请参阅管理训练和部署计算,了解有关创建计算目标的详细信息
- 使用 PyTorch 训练脚本。
- ACPT 特选(适用于 PyTorch 的 Azure 容器)环境。 请参阅特选环境以获取 ACPT 映像。 了解如何使用策展环境
如何使用 Nebula
Nebula 可在现有训练脚本中提供快速简单的检查点体验。 快速入门 Nebula 的步骤包括:
使用 ACPT 环境
适用于 PyTorch 的 Azure 容器 (ACPT) 是进行 PyTorch 模型训练的特选环境,包含 Nebula 作为预安装的依赖 Python 包。 请参阅 适用于 PyTorch 的 Azure 容器 (ACPT) 查看特选环境,以及在 Azure 机器学习中通过适用于 PyTorch 的 Azure 容器启用深度学习,详细了解 ACPT 映像。
初始化 Nebula
只需要修改训练脚本以导入 nebulaml 包,然后在相应位置调用 Nebula API,即可在 ACPT 环境中启用 Nebula。 可以避免修改 Azure 机器学习 SDK 或 CLI。 还可以避免修改其他步骤,即可在 Azure 机器学习平台上训练大型模型。
Nebula 需要初始化才能在训练脚本中运行。 在初始化阶段,指定确定检查点保存位置和频率的变量,代码片段如下所示:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
Nebula 已集成到 DeepSpeed 和 PyTorch Lightning 中。 因此,初始化变得很容易。 这些示例演示了如何将 Nebula 集成到训练脚本中。
重要
使用 Nebula 保存检查点需要一些内存来存储检查点。 请确保内存大于检查点的至少三个副本。
如果内存不足以保留检查点,建议在命令中设置环境变量 NEBULA_MEMORY_BUFFER_SIZE,以在保存检查点时限制每个节点的内存使用量。 设置此变量时,Nebula 将使用此内存作为缓冲区来保存检查点。 如果内存使用量不受限制,Nebula 将尽可能多地使用内存来存储检查点。
如果多个进程在同一节点上运行,则保存检查点的最大内存将是限制的一半除以进程数。 Nebula 将使用另一半进行多进程协调。 例如,如果要将每个节点的内存使用量限制为 200MB,可以在命令中将环境变量设置为 export NEBULA_MEMORY_BUFFER_SIZE=200000000(以字节为单位,大约为 200MB)。 在这种情况下,Nebula 将仅使用 200MB 内存在每个节点中存储检查点。 如果同一节点上运行了 4 个进程,则 Nebula 将为每个进程使用 25MB 内存来存储检查点。
调用 API 以保存并加载检查点
Nebula 提供多种 API 来处理检查点保存。 可以在训练脚本中使用这些 API,类似于 PyTorch torch.save() API。 这些示例演示了如何在训练脚本中使用 Nebula。
查看检查点历史记录
训练作业完成后,导航到“作业 Name> Outputs + logs”窗格。 在左侧面板中,展开“Nebula”文件夹,然后选择 checkpointHistories.csv 以查看有关 Nebula 检查点保存的详细信息:持续时间、吞吐量和检查点大小。

示例
这些示例演示了如何将 Nebula 与不同的框架类型配合使用。 可以选择最适合训练脚本的示例。
如需基于 PyTorch 的训练脚本与 Nebula 做到完全兼容,请根据需要修改训练脚本。
首先,导入所需的
nebulaml包:# Import the Nebula package for fast-checkpointing import nebulaml as nm若要初始化 Nebula,请如下所示,调用
main()中的nm.init()函数:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)若要保存检查点,请替换原始
torch.save()语句,将检查点保存为 Nebula。 请确保检查点实例以“global_step”开头,例如“global_step500”或“global_step1000”:checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)注意
<'CKPT_TAG_NAME'>是检查点的唯一 ID。 标记通常是步骤数、纪元编号或任何用户定义的名称。 可选<'NUM_OF_FILES'>可选参数指定要为此标记保存的状态编号。加载最近的有效检查点,如下所示:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)由于检查点或快照可能包含许多文件,因此可以按名称加载其中一个或多个文件。 训练状态可以使用最近的检查点还原到最近一个检查点保存的状态。
其他 API 可以处理检查点管理
- 列出所有检查点
- 获取最近的检查点
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)