你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
创建和浏览带标签的 Azure 机器学习数据集
在本文中,你将学习如何从 Azure 机器学习数据标记项目中导出数据标签,并将其加载为常用格式,例如,加载为 Pandas 数据帧以用于浏览数据。
什么是带标签的数据集
将带标签的 Azure 机器学习数据集称为带标签的数据集。 这些特定数据集是具有专用标签列的 TabularDatasets,只能创建为 Azure 机器学习数据标签项目的输出。 为图像标记或文本标记创建数据标记项目。 机器学习支持用于图像分类的数据标记项目(无论是多标签的还是多类的),以及带边界框的对象标识。
先决条件
- Azure 订阅。 如果还没有 Azure 订阅,可以在开始前创建一个免费帐户。
- 适用于 Python 的 Azure 机器学习 SDK,或 Azure 机器学习工作室的访问权限。
- 机器学习工作区。 请参阅创建工作区资源。
- 对 Azure 机器学习数据标记项目的访问权限。 如果没有标记项目,请首先为图像标记或文本标记创建一个。
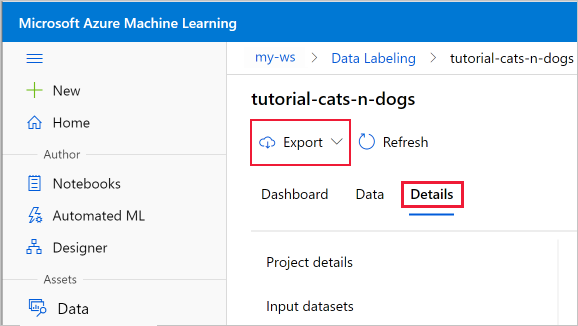
导出数据标签
完成数据标记项目后,可以从标记项目中导出标签数据。 这样,便可以捕获对数据及其标签的引用,并将其导出为 COCO 格式或 Azure 机器学习数据集。
使用标记项目的“项目详细信息”页上的“导出”按钮。
COCO
COCO 文件是在 Azure 机器学习工作区的默认 Blob 存储中创建的,该存储位于 export/coco 内的某个文件夹中。
注意
在物体检测项目中,COCO 文件中导出的“bbox": [x,y,width,height]”值已规范化。 其度量单位设定为 1。 示例:在像素为 640x480 的图像中,位置位于 (10, 10)、宽度为 30 像素、高度为 60 像素的边框将被标注为 (0.015625. 0.02083, 0.046875, 0.125)。 由于坐标已规范化,因此所有图像的“宽度”和“高度”将显示为“0.0”。 可以使用 Python 库(如 OpenCV 或 Pillow(PIL))获取实际的宽度和高度。
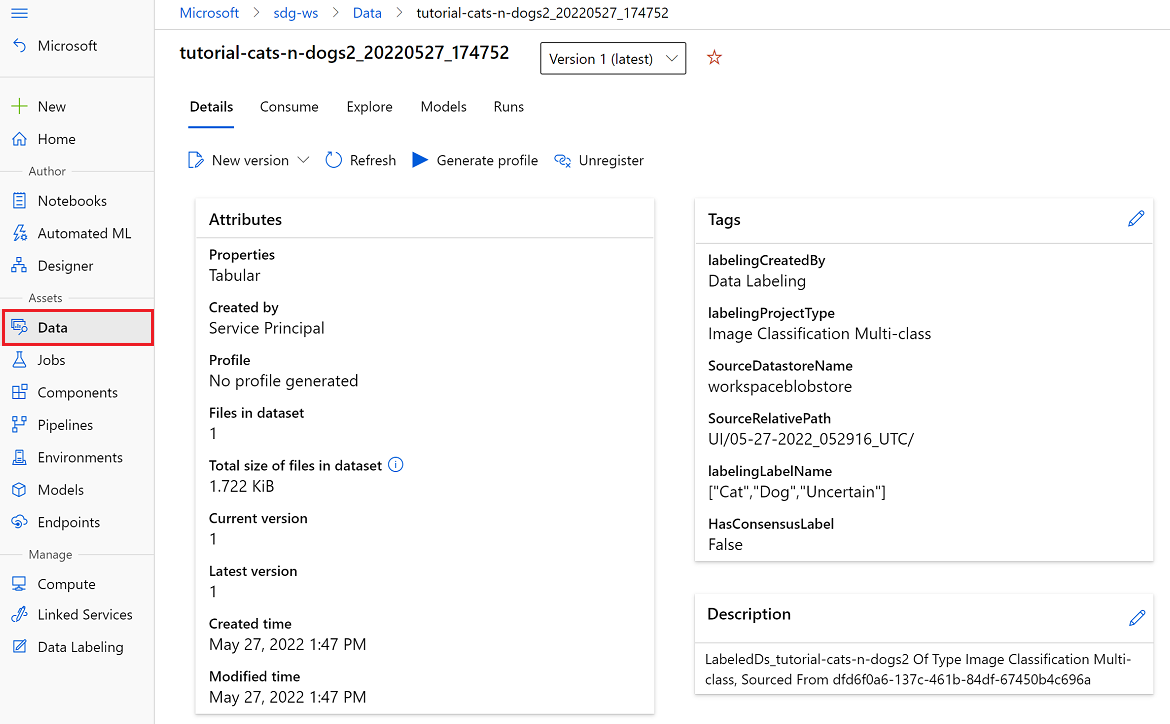
Azure 机器学习数据集
可以在 Azure 机器学习工作室的“数据集”部分中访问导出的 Azure 机器学习数据集。 数据集“详细信息”页还提供了演示如何从 Python 访问标签的示例代码。
提示
将标记数据导出到 Azure 机器学习数据集后,可以使用 AutoML 构建基于标记数据训练的计算机视觉模型。 要了解详细信息,请参阅设置 AutoML,以使用 Python 训练计算机视觉模型
通过 pandas 数据帧浏览带标签的数据集
将带标签的数据集加载到 pandas 数据帧中,以利用常见的开源库通过 azureml-dataprep 类中的 to_pandas_dataframe() 方法进行数据浏览。
可以使用以下 shell 命令安装此类:
pip install azureml-dataprep
在以下代码中,animal_labels 数据集是之前保存到工作区的标签项目的输出。
导出的数据集是一个 TabularDataset。

import azureml.core
from azureml.core import Dataset, Workspace
# get animal_labels dataset from the workspace
animal_labels = Dataset.get_by_name(workspace, 'animal_labels')
animal_pd = animal_labels.to_pandas_dataframe()
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#read images from dataset
img = mpimg.imread(animal_pd['image_url'].iloc(0).open())
imgplot = plt.imshow(img)