你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用自动化机器学习来准备用于计算机视觉任务的数据
适用于: Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
重要
支持在 Azure 机器学习中使用自动化 ML 训练计算机视觉模型是一项实验性公共预览功能。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
在本文中,你将了解如何准备图像数据,以便在 Azure 机器学习中使用自动化机器学习来训练计算机视觉模型。 要使用自动化机器学习来生成用于计算机视觉任务的模型,需要以 MLTable 的形式引入标记的图像数据作为模型训练的输入。
可以从 JSONL 格式的已标记训练数据创建一个 MLTable。 如果标记的训练数据采用不同的格式,例如 Pascal 视觉对象类 (VOC) 或 COCO,则可以使用转换脚本将其转换为 JSONL,然后创建一个 MLTable。 或者,可以使用 Azure 机器学习的数据标签工具手动标记图像。 然后导出标记数据,用于训练 AutoML 模型。
先决条件
获取标记的数据
若要使用 AutoML 训练计算机视觉模型,需要获取标记的训练数据。 需要将图像上传到云。 标签批注需要采用 JSONL 格式。 可以使用 Azure 机器学习数据标签工具来标记数据,也可以一开始就采用经过预先标记的图像数据。
使用 Azure 机器学习数据标签工具来标记训练数据
如果没有预标记的数据,可以使用 Azure 机器学习的数据标记工具来手动标记图像。 该工具会自动生成接受格式的训练所需的数据。 有关详细信息,请参阅设置图像标记项目。
此工具可帮助创建、管理和监视以下数据标签任务:
- 图像分类(多类和多标签)
- 对象检测(范围框)
- 实例分段(多边形)
如果已有要使用的标记数据,则可以将该标记数据导出为 Azure 机器学习数据集,然后在 Azure 机器学习工作室中的“数据集”选项卡下访问该数据集。 可以使用 azureml:<tabulardataset_name>:<version> 格式将此导出的数据集作为输入传递。 有关详细信息,请参阅导出标签。
下面是一个示例,说明了如何将现有数据集作为训练计算机视觉模型的输入进行传递。
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
从本地计算机使用预先标记的训练数据
如果已有要用于训练模型的标记数据,请将图像上传到 Azure。 可以将图像上传到 Azure 机器学习工作区的默认 Azure Blob 存储。 将其注册为数据资产。 有关详细信息,请参阅创建和管理数据资产。
以下脚本将本地计算机 ./data/odFridgeObjects 路径下的图像数据上传到 Azure Blob 存储的数据存储。 然后,它会在 Azure 机器学习工作区中创建名为 fridge-items-images-object-detection 的新数据资产。
如果 Azure 机器学习工作区中已存在名为 fridge-items-images-object-detection 的数据资产,代码会更新数据资产的版本号,并将其指向上传了图像数据的新位置。
创建一个具有以下配置的 .yml 文件。
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
若要将图像作为数据资产上传,请运行以下 CLI v2 命令,并提供 .yml 文件的路径、工作区名称、资源组和订阅 ID。
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
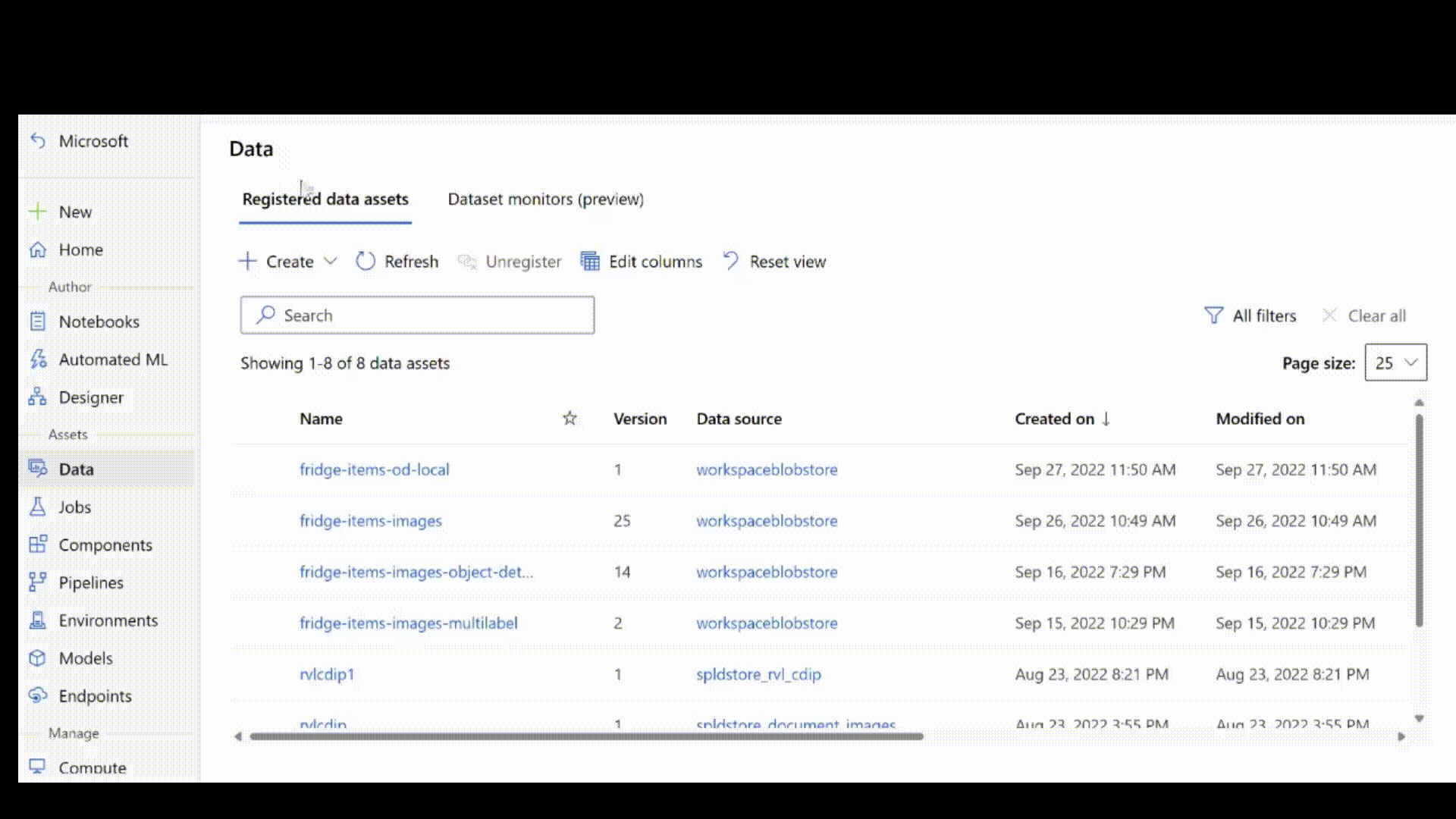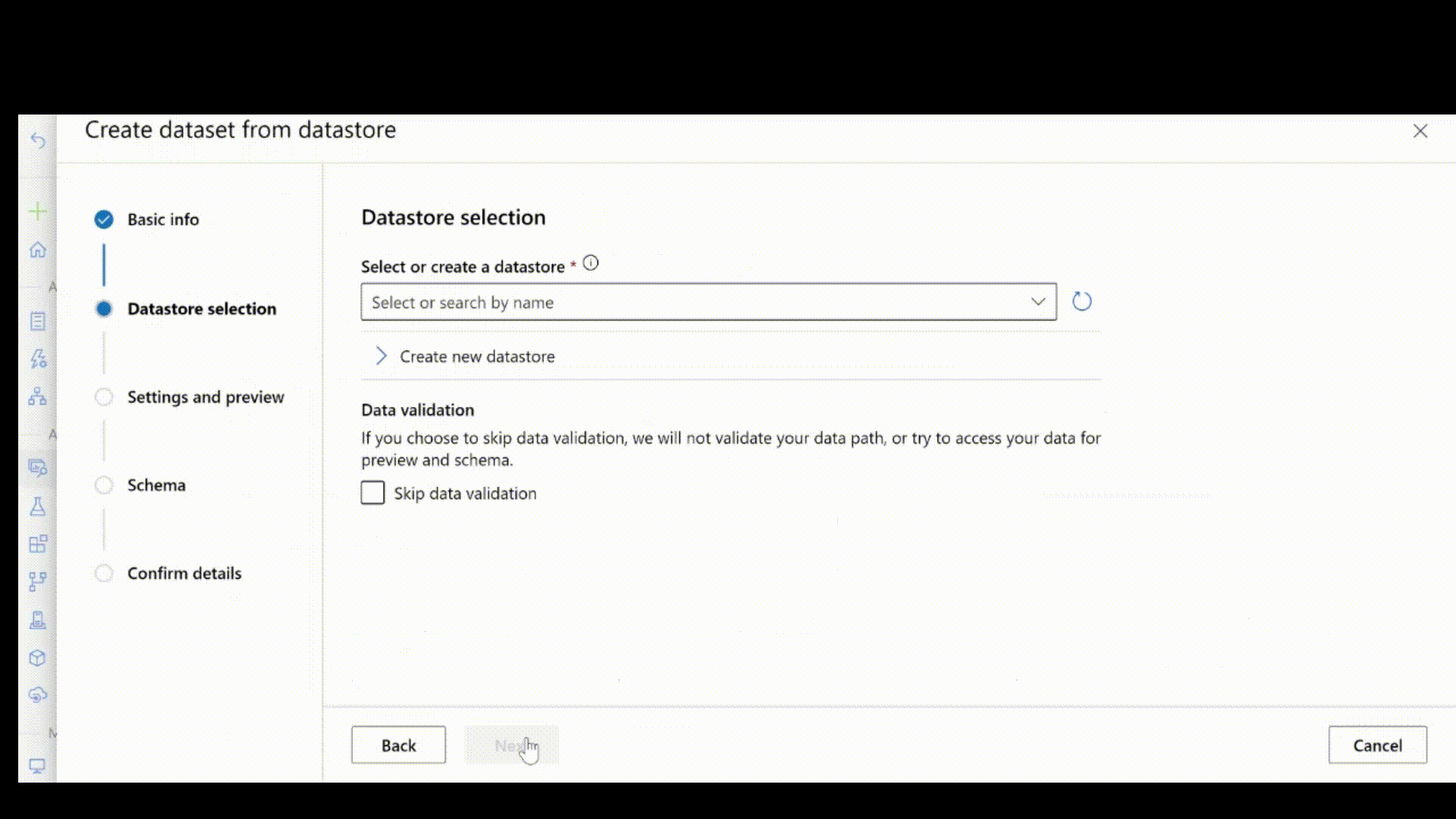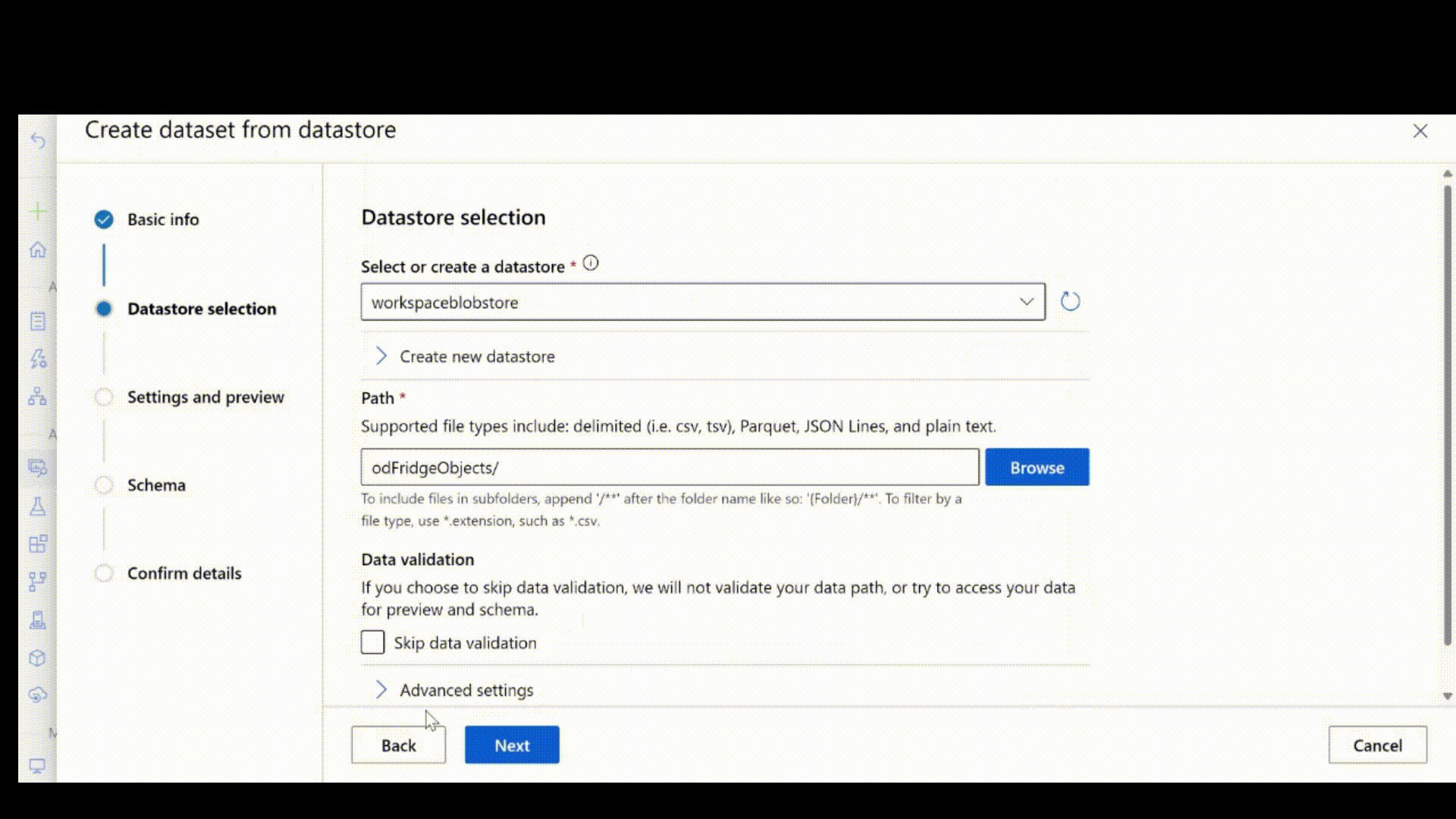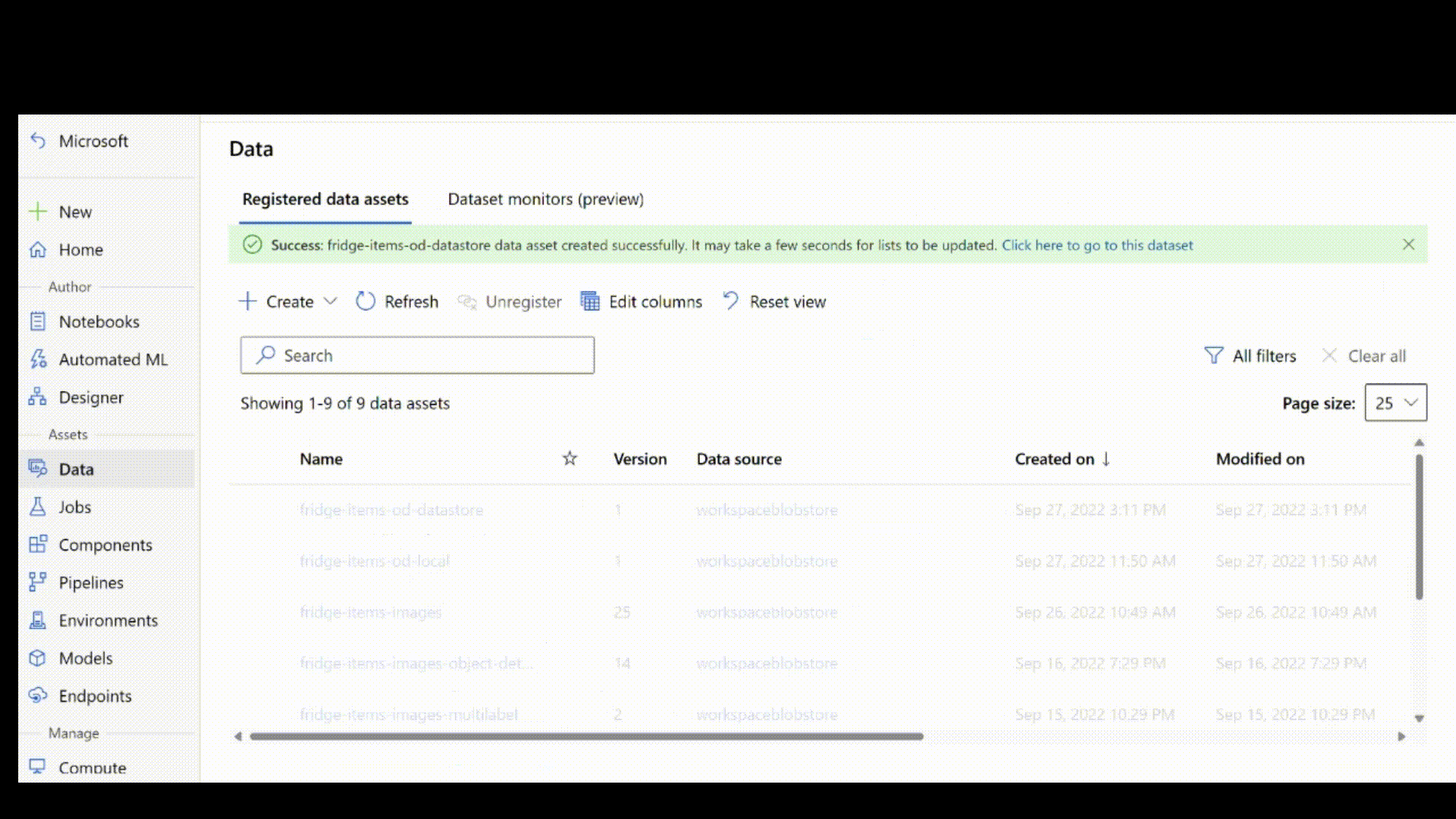
如果现有数据存储中已有数据,则可以使用它创建数据资产。 提供数据存储中数据的路径,而不是本地计算机的路径。 使用以下代码片段更新上述代码。
创建一个具有以下配置的 .yml 文件。
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
接下来,获取 JSONL 格式的标签批注。 已标记数据的架构取决于手头的计算机视觉任务。 若要详细了解每种任务类型所需的 JSONL 架构,请参阅使用自动化机器学习训练计算机视觉模型的数据架构。
如果训练数据采用不同的格式,如 pascal VOC 或 COCO,帮助程序脚本可以将数据转换为 JSONL。 这些脚本可在笔记本示例中找到。
创建 .jsonl 文件后,可以使用 UI 将其注册为数据资产。 请确保在架构部分选择 stream 类型,如此动画所示。
使用 Azure Blob 存储中预先标记的训练数据
如果标记的训练数据存在于 Azure Blob 存储中的容器中,则可以直接访问这些数据。 为该容器创建数据存储。 有关详细信息,请参阅创建和管理数据资产。
创建 MLTable
标记数据为 JSONL 格式后,可以使用它创建 MLTable,如此 yaml 代码片段所示。 MLtable 会将数据打包为一个可供训练使用的对象。
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
然后,你可以传入 MLTable,作为 AutoML 训练作业的数据输入。 有关详细信息,请参阅设置 AutoML 以训练计算机视觉模型。