适用于: Azure CLI ml 扩展 v2(当前)
Azure CLI ml 扩展 v2(当前)
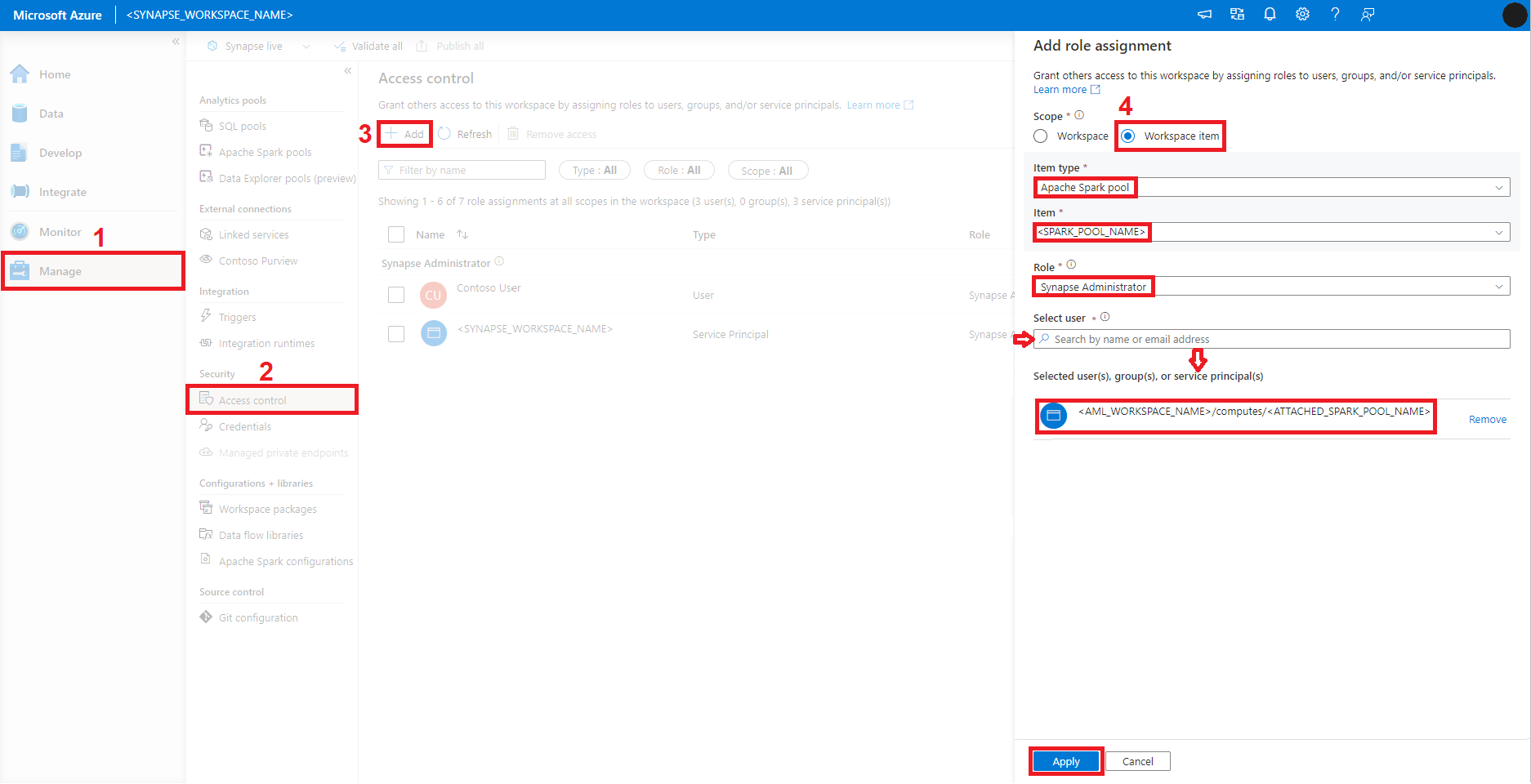
借助 Azure 机器学习 CLI,可以使用直观的 YAML 语法和命令从命令行界面附加和管理 Synapse Spark 池。
若要使用 YAML 语法定义附加的 Synapse Spark 池,YAML 文件应涵盖以下属性:
name - 附加的 Synapse Spark 池的名称。
type - 将此属性设置为 synapsespark。
resource_id - 此属性应提供在 Azure Synapse Analytics 工作区中创建的 Synapse Spark 池的资源 ID 值。 Azure 资源 ID 包括
Azure 订阅 ID,
资源组名称,
Azure Synapse Analytics 工作区名称,以及
Synapse Spark 池的名称。
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity – 此属性定义要分配给附加的 Synapse Spark 池的标识类型。 它可以采用以下值之一:
对于 identity 类型 user_assigned,还应提供 user_assigned_identities 值的列表。 应使用用户分配的标识的 resource_id 值将每个用户分配的标识声明为该列表的元素。 默认情况下,列表中第一个用户分配的标识用于提交作业。
name: <ATTACHED_SPARK_POOL_NAME>
type: synapsespark
resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>
identity:
type: user_assigned
user_assigned_identities:
- resource_id: /subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>
上述 YAML 文件可在 az ml compute attach 命令中用作 --file 参数。 可以使用 az ml compute attach 命令将 Synapse Spark 池附加到位于订阅的指定资源组中的 Azure 机器学习工作区,如下所示:
az ml compute attach --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
此示例显示了上述命令的预期输出:
Class SynapseSparkCompute: This is an experimental class, and may change at any time. Please visit https://aka.ms/azuremlexperimental for more information.
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
如果附加的 Synapse Spark 池(其名称在 YAML 规范文件中指定)已存在于工作区中,则 az ml compute attach 命令执行会使用 YAML 规范文件中提供的信息更新现有池。 你可以通过 YAML 规范文件更新
值。
若要显示附加的 Synapse Spark 池的详细信息,请执行 az ml compute show 命令。 使用 --name 参数传递附加的 Synapse Spark 池的名称,如下所示:
az ml compute show --name <ATTACHED_SPARK_POOL_NAME> --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
此示例显示了上述命令的预期输出:
<ATTACHED_SPARK_POOL_NAME>
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-13 19:01:05.109840+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
}
若要查看所有计算(包括工作区中附加的 Synapse Spark 池)的列表,请使用 az ml compute list 命令。 使用 name 参数传递工作区的名称,如下所示:
az ml compute list --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
此示例显示了上述命令的预期输出:
[
{
"auto_pause_settings": {
"auto_pause_enabled": true,
"delay_in_minutes": 15
},
"created_on": "2022-09-09 21:28:54.871251+00:00",
"id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>/computes/<ATTACHED_SPARK_POOL_NAME>",
"identity": {
"principal_id": "<PRINCIPAL_ID>",
"tenant_id": "<TENANT_ID>",
"type": "system_assigned"
},
"location": "eastus2",
"name": "<ATTACHED_SPARK_POOL_NAME>",
"node_count": 5,
"node_family": "MemoryOptimized",
"node_size": "Small",
"provisioning_state": "Succeeded",
"resourceGroup": "<RESOURCE_GROUP>",
"resource_id": "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>",
"scale_settings": {
"auto_scale_enabled": false,
"max_node_count": 0,
"min_node_count": 0
},
"spark_version": "3.2",
"type": "synapsespark"
},
...
]
适用于:Python SDK azure-ai-ml v2(当前版本)
Azure 机器学习 Python SDK 提供了方便的功能,用于使用 Azure 机器学习笔记本中的 Python 代码附加和管理 Synapse Spark 池。
若要使用 Python SDK 附加 Synapse 计算,请先创建 azure.ai.ml.MLClient 类的实例。 这为与 Azure 机器学习服务交互提供了方便的功能。 以下代码示例使用 azure.identity.DefaultAzureCredential 连接到指定 Azure 订阅的资源组中的工作区。 在以下代码示例中,使用以下参数定义 SynapseSparkCompute:
name - 新附加的 Synapse Spark 池的用户定义名称。resource_id - 先前在 Azure Synapse Analytics 工作区中创建的 Synapse Spark 池的资源 ID
azure.ai.ml.MLClient.begin_create_or_update() 函数调用将定义的 Synapse Spark 池附加到 Azure 机器学习工作区。
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_comp = SynapseSparkCompute(name=synapse_name, resource_id=synapse_resource)
ml_client.begin_create_or_update(synapse_comp)
若要附加使用系统分配的标识的 Synapse Spark 池,请将类型设置为 SystemAssigned 的 IdentityConfiguration 作为 SynapseSparkCompute 类的 identity 参数传递。 此代码片段附加了一个使用系统分配的标识的 Synapse Spark 池:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import SynapseSparkCompute, IdentityConfiguration
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(type="SystemAssigned")
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
Synapse Spark 池还可以使用用户分配的标识。 对于用户分配的标识,可以使用 IdentityConfiguration 类将托管标识定义作为 SynapseSparkCompute 类的 identity 参数传递。 对于以这种方式使用的托管标识定义,请将 type 设置为 UserAssigned。 此外,传递 user_assigned_identities 参数。 参数 user_assigned_identities 是 UserAssignedIdentity 类的对象列表。 用户分配的标识的 resource_id 填充每个 UserAssignedIdentity 类对象。 此代码片段附加了一个使用用户分配的标识的 Synapse Spark 池:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
SynapseSparkCompute,
IdentityConfiguration,
UserAssignedIdentity,
)
from azure.identity import DefaultAzureCredential
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<AML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace_name
)
synapse_name = "<ATTACHED_SPARK_POOL_NAME>"
synapse_resource = "/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.Synapse/workspaces/<SYNAPSE_WORKSPACE_NAME>/bigDataPools/<SPARK_POOL_NAME>"
synapse_identity = IdentityConfiguration(
type="UserAssigned",
user_assigned_identities=[
UserAssignedIdentity(
resource_id="/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>"
)
],
)
synapse_comp = SynapseSparkCompute(
name=synapse_name, resource_id=synapse_resource, identity=synapse_identity
)
ml_client.begin_create_or_update(synapse_comp)
注意
如果工作区中尚不存在具有指定名称的池,则 azure.ai.ml.MLClient.begin_create_or_update() 函数将附加新的 Synapse Spark 池。 但是,如果具有该指定名称的 Synapse Spark 池已附加到工作区,则对 azure.ai.ml.MLClient.begin_create_or_update() 函数的调用将使用新标识更新现有的附加池。