你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
管理组件和管道的输入和输出
Azure 机器学习管道支持组件级别和管道级别的输入和输出。 本文介绍了管道和组件输入和输出以及如何管理它们。
在组件级别,输入和输出可定义组件接口。 可以使用一个组件的输出作为同一父级管道中另一个组件的输入,从而允许在组件之间传递数据或模型。 此互连表示管道中的数据流。
在管道级别,可以使用输入和输出来提交具有不同数据输入或参数的管道作业,例如 learning_rate。 通过 REST 终结点调用管道时,输入和输出特别有用。 可以将不同的值分配给管道输入或访问不同管道作业的输出。 有关详细信息,请参阅为批处理终结点创建作业和输入数据。
输入和输出类型
支持以下类型作为组件或管道的输入和输出:
数据类型。 有关详细信息,请参阅数据类型。
uri_fileuri_foldermltable
模型类型。
mlflow_modelcustom_model
也仅支持将以下基元类型作为输入:
- 基元类型
stringnumberintegerboolean
不支持基元类型输出。
输入和输出示例
这些示例来自 Azure 机器学习示例 GitHub 存储库中的 NYC Taxi Data Regression 管道。
- train 组件具有名为
test_split_ratio的number输入。 - prep 组件具有
uri_folder类型输出。 组件源代码会从输入文件夹读取 CSV 文件,处理文件并将处理过的 CSV 文件写入输出文件夹。 - train 组件具有
mlflow_model类型输出。 组件源代码中使用mlflow.sklearn.save_model方法保存训练的模型。
输出序列化
使用数据或模型输出将输出序列化,并将其作为文件保存在存储位置。 后续步骤可以通过装载此存储位置或将文件下载或上传到计算文件系统来访问作业执行过程中的文件。
组件源代码必须将输出对象(通常存储在内存中)序列化到文件中。 例如,可以将 pandas 数据帧序列化到 CSV 文件中。 Azure 机器学习没有为对象序列化定义任何标准化方法。 可以灵活地选择将对象序列化到文件中的首选方法。 在下游组件中,可以选择如何反序列化和读取这些文件。
数据类型输入和输出路径
对于数据资产输入和输出,必须指定指向数据位置的 path 参数。 下表显示了 Azure 机器学习管道输入和输出所支持的数据位置,并提供了 path 参数示例。
| 位置 | 输入 | 输出 | 示例 |
|---|---|---|---|
| 本地计算机上的路径 | ✓ | ./home/<username>/data/my_data |
|
| 公共 http/s 服务器上的路径 | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Azure 存储上的路径 | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>或 abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Azure 机器学习数据存储上的路径 | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| 数据资产的路径 | ✓ | ✓ | azureml:my_data:<version> |
* 不建议直接使用 Azure 存储进行输入,因为它可能需要额外的标识配置才能读取数据。 最好使用跨各种管道作业类型支持的 Azure 机器学习数据存储路径。
数据类型输入和输出模式
对于数据类型输入和输出,可以从多个下载、上传和装载模式中进行选择,以定义计算目标访问数据的方式。 下表显示了不同类型的输入和输出所支持的模式。
| 类型 | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder 输入 |
✓ | ✓ | ✓ | ||||
uri_file 输入 |
✓ | ✓ | ✓ | ||||
mltable 输入 |
✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder 输出 |
✓ | ✓ | |||||
uri_file 输出 |
✓ | ✓ | |||||
mltable 输出 |
✓ | ✓ | ✓ |
对于大多数情况,建议使用 ro_mount 或 rw_mount 模式。 有关详细信息,请参阅模式。
管道图中的输入和输出
在 Azure 机器学习工作室的管道作业页上,组件输入和输出显示为称为输入/输出端口的小圆圈。 这些端口表示管道中的数据流。 管道级别的输出以紫色框显示,以便于识别。
NYC Taxi Data Regression 管道图中的以下屏幕截图显示了许多组件和管道输入与输出。

将鼠标悬停在输入/输出端口上时,将显示类型。
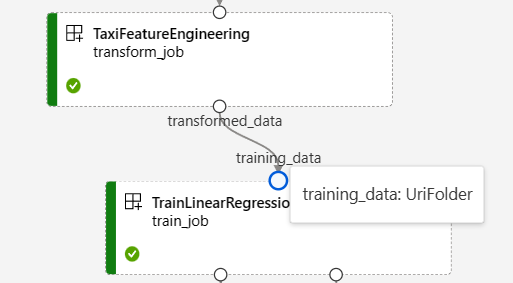
管道图不显示基元类型输入。 这些输入显示在管道“作业概述”面板(用于管道级别输入)或组件面板(用于组件级别输入)的“设置”选项卡上。 若要打开组件面板,请双击图中的组件。

在工作室设计器中编辑管道时,管道输入和输出位于“管道接口”面板中,组件输入和输出位于组件面板中。
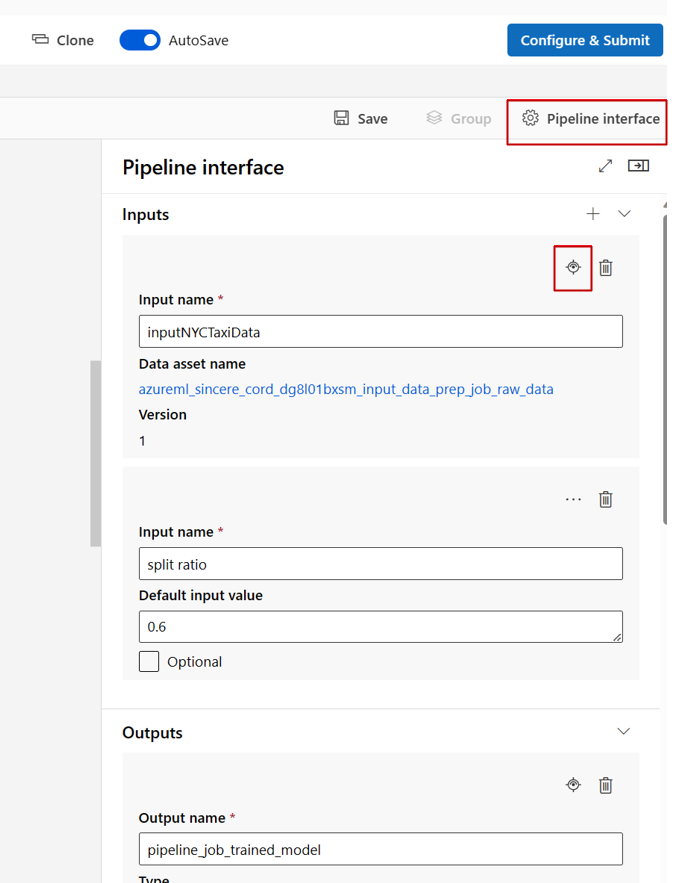
将组件输入/输出提升到管道级别
通过将组件的输入/输出提升到管道级别,可以在提交管道作业时覆盖组件的输入/输出。 此功能对于使用 REST 终结点触发管道特别有用。
以下示例显示了如何将组件级别输入/输出提升到管道级别输入/输出。
以下管道将三个输入和三个输出提升到管道级别。 例如,pipeline_job_training_max_epocs 是管道级别输入,因为它在根级别的 inputs 部分下声明。
在 jobs 部分中的 train_job 下,名为 max_epocs 的输入引用为 ${{parent.inputs.pipeline_job_training_max_epocs}},这意味着 train_job 的 max_epocs 输入引用了管道级别 pipeline_job_training_max_epocs 输入。 使用同一架构提升管道输出。
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
可以在 Azure 机器学习示例存储库的包含已注册组件的 train-score-eval 管道中找到完整示例。
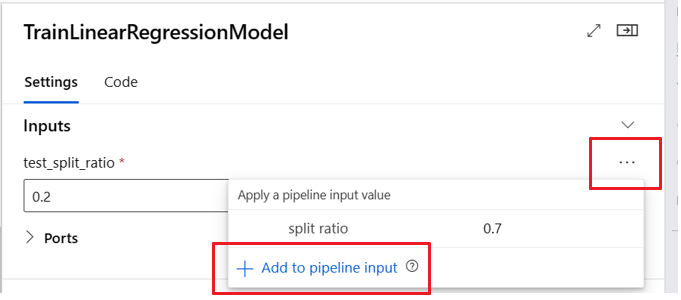
定义可选输入
默认情况下,所有输入都是必需的,并且每次提交管道作业时,必须拥有一个默认值或分配一个值。 但是,可以定义可选输入。
注意
不支持可选输出。
设置可选输入在以下两种方案中很有用:
如果定义了可选的数据/模型类型输入,但在提交管道作业时未为其赋值,则管道组件将缺少该数据依赖项。 如果组件的输入端口未链接到任何组件或数据/模型节点,则管道将直接调用组件,而不是等待上述依赖项。
如果为管道设置了
continue_on_step_failure = True,但node2使用来自node1的必需输入,则node1一旦失败,将不会执行node2。 如果node1输入是可选的,则即使node1失败,node2也会执行。 下图演示了此方案。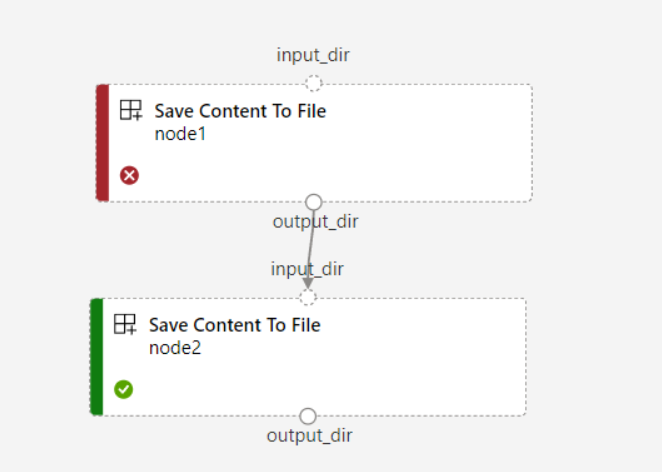
以下代码示例展示了如何定义可选输入。 当输入设置为 optional = true 时,必须使用 $[[]] 来接受命令行输入,如示例中突出显示的行所示。
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

自定义输出路径
默认情况下,组件输出存储在为管道 azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}} 设置的 {default_datastore} 中。 如果未设置,则默认值为工作区 Blob 存储。
作业 {name} 在作业执行时解析,{output_name} 是在组件 YAML 中定义的名称。 可以通过定义输出路径来自定义存储输出的位置。
包含已注册组件的 train-score-eval 管道示例中的 pipeline.yml 文件定义了具有三个管道级别输出的管道。 可以使用以下命令设置 pipeline_job_trained_model 输出的自定义输出路径。
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

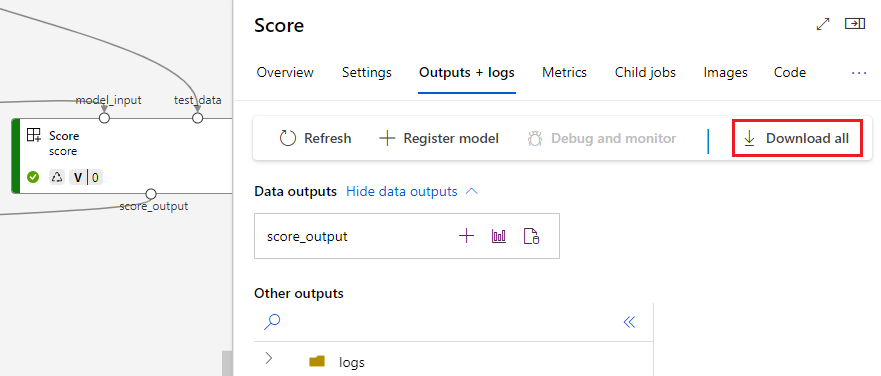
下载输出
可以在管道或组件级别下载输出。
下载管道级别输出
可以下载作业的所有输出或下载特定输出。
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

下载组件输出
若要下载子组件的输出,请先列出管道作业的所有子作业,然后使用类似的代码下载输出。
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
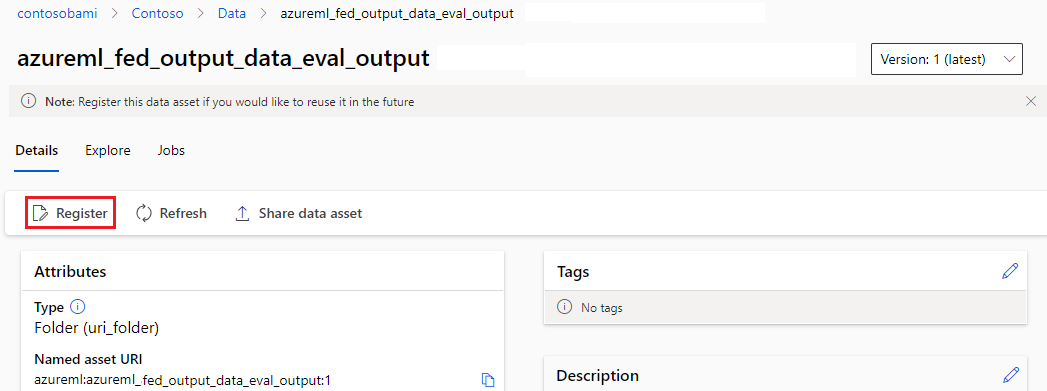
将输出注册为命名资产
可以通过将 name 和 version 分配给输出来将组件或管道的输出注册为命名资产。 注册的资产可以通过工作室 UI、CLI 或 SDK 在工作区中列出,也可以在将来的工作区作业中引用。
注册管道级别输出
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
注册组件输出
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster