你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure 机器学习 CLI 和组件创建和运行机器学习管道

本文介绍如何使用 Azure CLI 和组件来创建并运行机器学习管道。 可以在不使用组件的情况下创建管道,但组件可提供最大的灵活性和可重用性。 可以使用 YAML 定义 Azure 机器学习管道并从 CLI 运行,也可以使用 Python 创作 Azure 机器学习管道,或在 Azure 机器学习工作室设计器中通过拖放 UI 操作来编写 Azure 机器学习管道。 本文档重点介绍 CLI。
先决条件
如果没有 Azure 订阅,请在开始操作前先创建一个免费帐户。 试用免费版或付费版 Azure 机器学习。
Azure 机器学习工作区。 创建工作区资源。
克隆示例存储库:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
建议的预读取
使用组件创建第一个管道
让我们使用示例创建你的第一个组件管道。 本部分旨在通过具体示例让你初步了解 Azure 机器学习中的管道和组件。
从 azureml-examples 存储库的 cli/jobs/pipelines-with-components/basics 目录导航到 3b_pipeline_with_data 子目录。 在此目录下有三种类型的文件。 这些都是在生成你自己的管道时需要创建的文件。
pipeline.yml:此 YAML 文件定义机器学习管道。 此 YAML 文件介绍如何将完整的机器学习任务拆分为多步骤工作流。 例如,假设有一个使用历史数据训练销售预测模型的简单机器学习任务,你可能需要生成顺序工作流,其中包含数据处理、模型训练和模型评估步骤。 每个步骤都是一个具有明确定义接口的组件,可以独立开发、测试和优化。 管道 YAML 还定义了子步骤如何连接到管道中的其他步骤,例如模型训练步骤生成模型文件,模型文件又将传递给模型评估步骤。
component.yml:此 YAML 文件定义组件。 它打包以下信息:
- 元数据:名称、显示名称、版本、说明、类型等。元数据可帮助描述和管理组件 。
- 接口:输入和输出 。 例如,模型训练组件将训练数据和时期数作为输入,并生成训练的模型文件作为输出。 定义接口后,各个团队可以独立开发和测试组件。
- 命令、代码和环境:用于运行组件的命令、代码和环境 。 命令是用于执行组件的 shell 命令。 代码通常指源代码目录。 环境可以是 Azure 机器学习环境(特选或客户创建)、Docker 映像或 conda 环境。
component_src:特定组件的源代码目录。 它包含在组件中执行的源代码。 可使用首选语言(Python、R 等)。代码必须由 shell 命令执行。 源代码可采用 shell 命令行中的一些输入来控制此步骤的执行方式。 例如,训练步骤可以采用训练数据、学习速率、日期数来控制训练过程。 shell 命令的参数用于向代码传递输入和输出。
现在,使用 3b_pipeline_with_data 示例创建管道。 以下部分介绍每个文件的详细含义。
首先,使用以下命令列出可用的计算资源:
az ml compute list
如果没有计算资源,请运行以下命令以创建名为 cpu-cluster 的群集:
注意
跳过此步骤以使用无服务器计算。
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
现在,使用以下命令创建在 pipeline.yml 文件中定义的管道作业。 在 pipeline.yml 文件中,计算目标被引用为 azureml:cpu-cluster。 如果计算目标使用其他名称,务必在 pipeline.yml 文件中进行更新。
az ml job create --file pipeline.yml
你应该会收到包含管道作业相关信息的 JSON 字典,这些信息包括:
| 密钥 | 说明 |
|---|---|
name |
作业的 GUID 名称。 |
experiment_name |
在工作室中组织作业时使用的名称。 |
services.Studio.endpoint |
用于监视和查看管道作业的 URL。 |
status |
作业的状态。 此时的状态可能是Preparing。 |
打开 services.Studio.endpoint URL 以查看管道的图形可视化效果。
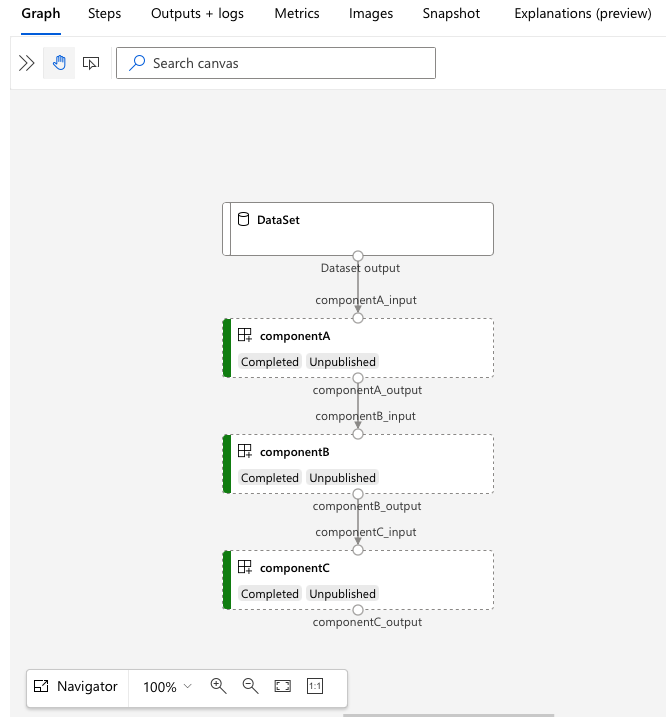
了解管道定义 YAML
先了解一下 3b_pipeline_with_data/pipeline.yml 文件中的管道定义。
注意
若要使用无服务器计算,请将此文件中的 default_compute: azureml:cpu-cluster 替换为 default_compute: azureml:serverless。
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
该表介绍了管道 YAML 架构最常用的字段。 若要了解详细信息,请参阅完整的管道 YAML 架构。
| key | description |
|---|---|
| type | 必需。 对于管道作业,作业类型必须为 pipeline。 |
| display_name | 管道作业在工作室 UI 中的显示名称。 在工作室 UI 中可编辑。 不必在工作区中的所有作业中保持唯一。 |
| jobs | “必需”。 在管道中作为步骤运行的一组单个作业的字典。 这些作业被视为父管道作业的子作业。 在此版本中,管道中支持的作业类型为 command 和 sweep |
| inputs | 管道作业的输入字典。 键是作业上下文中的输入名称,值是输入值。 这些管道输入可以被管道中单个步骤作业的输入所引用(使用 ${{ parent.inputs.<input_name> }} 表达式)。 |
| outputs | 管道作业的输出配置字典。 键是作业上下文中的输出名称,值是输出配置。 这些管道输出可以被管道中单个步骤作业的输出所引用(使用 ${{ parents.outputs.<output_name> }} 表达式)。 |
在 3b_pipeline_with_data 示例中,我们创建了三步骤管道。
- 这三个步骤在
jobs下定义。 三个步骤类型都是命令作业。 每个步骤的定义都位于相应的component.yml文件中。 可在 3b_pipeline_with_data 目录下查看组件 YAML 文件。 下一部分将介绍 componentA.yml。 - 此管道具有数据依赖项,这在大多数实际管道中很常见。 Component_a 从
./data下的本地文件夹(第 17-20 行)获取数据输入,并将其输出传递给 componentB(第 29 行)。 Component_a 的输出可以引用为${{parent.jobs.component_a.outputs.component_a_output}}。 compute定义此管道的默认计算。 如果jobs下的某个组件定义了此组件的不同计算,系统会遵循特定于组件的设置。

在管道中读取和写入数据
一种常见场景是在管道中读取和写入数据。 在 Azure 机器学习中,我们针对所有类型的作业(管道作业、命令作业和扫描作业)使用同一架构来读取和写入数据。 以下是在常见场景中使用数据的管道作业示例。
了解组件定义 YAML
现在以 componentA.yml 为例了解组件定义 YAML。
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
该表介绍了组件 YAML 最常用的架构。 若要了解详细信息,请参阅完整的组件 YAML 架构。
| key | description |
|---|---|
| name | “必需”。 组件的名称。 在 Azure 机器学习工作区中必须是唯一的。 必须以小写字母开头。 可使用小写字母、数字和下划线 (_)。 最大长度为 255 个字符。 |
| display_name | 组件在工作室 UI 中的显示名称。 在工作区中可以不唯一。 |
| 命令 | 必需,要执行的命令 |
| code | 要上传并用于组件的源代码目录的本地路径。 |
| 环境 | 必需。 用于执行此组件的环境。 |
| inputs | 组件输入的字典。 键是组件上下文中的输入名称,值是组件输入定义。 可使用 ${{ inputs.<input_name> }} 表达式在命令中引用输入。 |
| outputs | 组件输出的字典。 键是组件上下文中的输出名称,值是组件输出定义。 可使用 ${{ outputs.<output_name> }} 表达式在命令中引用输出。 |
| is_deterministic | 是否在组件输入未更改的情况下重用上一作业的结果。 默认值为 true,默认为再使用。 设置为 false 时,常见场景是强制从云存储或 URL 重新加载数据。 |
对于 3b_pipeline_with_data/componentA.yml 中的示例,componentA 有一个数据输入和一个数据输出,可以连接到父管道中的其他步骤。 提交管道作业时,组件 YAML 中 code 部分下的所有文件都将上传到 Azure 机器学习。 在此示例中,将上传 ./componentA_src 下的文件(componentA.yml 中的第 16 行)。 可在工作室 UI 中查看上传的源代码:双击 ComponentA 步骤并导航到“快照”选项卡,如以下屏幕截图所示。 可看到它是一个仅执行一些简单打印的 hello-world 脚本,并可将当前日期/时间写入 componentA_output 路径。 组件通过命令行参数获取输入和输出,并在 hello.py 中使用 argparse 进行处理。

输入和输出
输入和输出定义组件的接口。 输入和输出可以是文本值(string、number、integer 或 boolean 类型)或包含输入架构的对象。
对象输入(uri_file、uri_folder、mltable、mlflow_model、custom_model 类型)可以连接到父管道作业中的其他步骤,从而将数据/模型传递给其他步骤。 在管道图中,对象类型输入呈现为连接点。
文本值输入(string、number、integer、boolean)是可以在运行时传递给组件的参数。 可在 default 字段下添加文本输入的默认值。 对于 number 和 integer 类型,还可使用 min 和 max 字段添加接受值的最小值和最大值。 如果输入值超过最小值和最大值,管道在验证时会失败。 提交管道作业之前进行验证以节省时间。 验证适用于 CLI、Python SDK 和设计器 UI。 以下屏幕截图显示了设计器 UI 中的验证示例。 同样,可在 enum 字段中定义允许的值。

如果要向组件添加输入,请记得编辑三个位置:
- 组件 YAML 中的
inputs字段 - 组件 YAML 中的
command字段。 - 处理命令行输入的组件源代码。 上一屏幕截图中的绿色框中标记了它。
若要了解有关输入和输出的详细信息,请参阅管理组件和管道的输入和输出。
环境
环境定义要执行组件的环境。 可以是 Azure 机器学习环境(特选或客户注册的)、Docker 映像或 conda 环境。 请参阅以下示例。
- 已注册 Azure 机器学习的环境资产。 它在组件中引用,遵循
azureml:<environment-name>:<environment-version>语法。 - 公共 docker 映像
- conda 文件 Conda 文件需要与基础映像一起使用。
注册组件以重用和共享
虽然某些组件特定于特定管道,但组件的实际优势来自重用和共享。 在机器学习工作区中注册组件,使其可供重用。 已注册的组件支持自动版本控制,因此你可以更新组件,但要确保需使用较旧版本的管道能够继续工作。
在 azureml-examples 存储库中,导航到 cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components 目录。
若要注册组件,请使用 az ml component create 命令:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
运行完这些命令后,可在工作室的“资产”->“组件”下查看组件:

选择组件。 你会看到每个版本的组件的详细信息。
在“详细信息”选项卡下,会看到组件的基本信息,例如名称、创建者、版本等。还会看到“标记”和“说明”的可编辑字段。 标记可用于添加快速搜索的关键字。 说明字段支持 Markdown 格式设置,应将其用于描述组件的功能和基本用途。
在“作业”选项卡下,你会看到使用此组件的所有作业的历史记录。
在管道作业 YAML 文件中使用已注册的组件
现在使用 1b_e2e_registered_components 演示如何在管道 YAML 中使用已注册的组件。 导航到 1b_e2e_registered_components 目录,打开 pipeline.yml 文件。 inputs 和 outputs 字段中的键和值类似于之前讨论过的键和值。 唯一的显著区别是 jobs.<JOB_NAME>.component 项中 component 字段的值。 component 值的格式为 azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>。 例如,train-job 定义指定应使用已注册组件 my_train 的最新版本:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
管理组件
可以使用 CLI (v2) 检查组件详细信息和管理组件。 使用 az ml component -h 获取有关组件命令的详细说明。 下表列出了所有可用的命令。 请参阅 Azure CLI 参考了解更多示例。
| commands | description |
|---|---|
az ml component create |
创建组件 |
az ml component list |
列出工作区中的组件 |
az ml component show |
显示组件的详细信息 |
az ml component update |
更新组件。 仅一些字段(description、display_name)支持更新 |
az ml component archive |
存档组件容器 |
az ml component restore |
还原存档组件 |
后续步骤
- 试用 CLI v2 组件示例