你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用负责任 AI 仪表板评估 AI 系统
在实践中实现负责任 AI 需要严谨的工程设计。 但是,如果没有合适的工具和基础结构,严谨的工程设计也可能导致非常繁琐、手动和耗时。
负责任 AI 仪表板提供单一的界面来帮助你在实践中有效且高效地实现负责任 AI。 它汇集了多个成熟的负责任 AI 工具用于实现以下方面的需求:
- 模型性能和公平性评估
- 数据研究
- 机器学习可解释性
- 错误分析
- 反事实分析和扰动
- 因果推理
该仪表板提供模型的整体评估和调试,使你可以做出明智的数据驱动的决策。 在一个界面中访问所有这些工具可以让你:
通过识别模型错误和公平性问题、诊断出现这些错误的原因以及告知缓解步骤来评估和调试机器学习模型。
通过回答如下所述的问题来提升数据驱动的决策能力:
“用户为了从模型中获取不同结果而可以对其特征应用的最轻微更改是什么?”
“减少或增加特征(例如红肉食用量)对实际结果(例如糖尿病发展阶段)的因果效应是什么?”
可以自定义仪表板以仅包含与用例相关的工具子集。
负责任 AI 仪表板附有 PDF 记分卡。 使用记分卡可将负责任 AI 元数据和见解导出到数据和模型中。 然后,可以与产品和合规性利益干系人脱机共享这些信息。
负责任 AI 仪表板组件
负责任 AI 仪表板在综合视图中汇集了各种新的和现有工具。 该仪表板将这些工具与 Azure 机器学习 CLI v2、Azure 机器学习 Python SDK v2 和 Azure 机器学习工作室相集成。 这些工具包括:
- 数据分析:用于了解和探索数据集分布和统计。
- 模型概述和公平性评估,用于评估模型的性能并评估模型的组公平性问题(模型的预测如何影响不同的人群)。
- 错误分析,用于查看和了解错误在数据集中的分布情况。
- 模型可解释性(聚合和各个特征的重要性值),用于了解模型的预测以及这些整体预测和各项预测是如何做出的。
- 反事实 What-If,用于观察特征扰动如何影响模型预测,同时提供具有相反或不同模型预测的最接近数据点。
- 因果分析,用于通过历史数据查看处理特征对实际结果的因果效应。
这些工具相结合,可帮助你调试机器学习模型,同时为数据驱动和模型驱动的业务决策提供见解。 下图显示了如何将这些工具整合到 AI 生命周期中,以改进模型并获取可靠的数据见解。
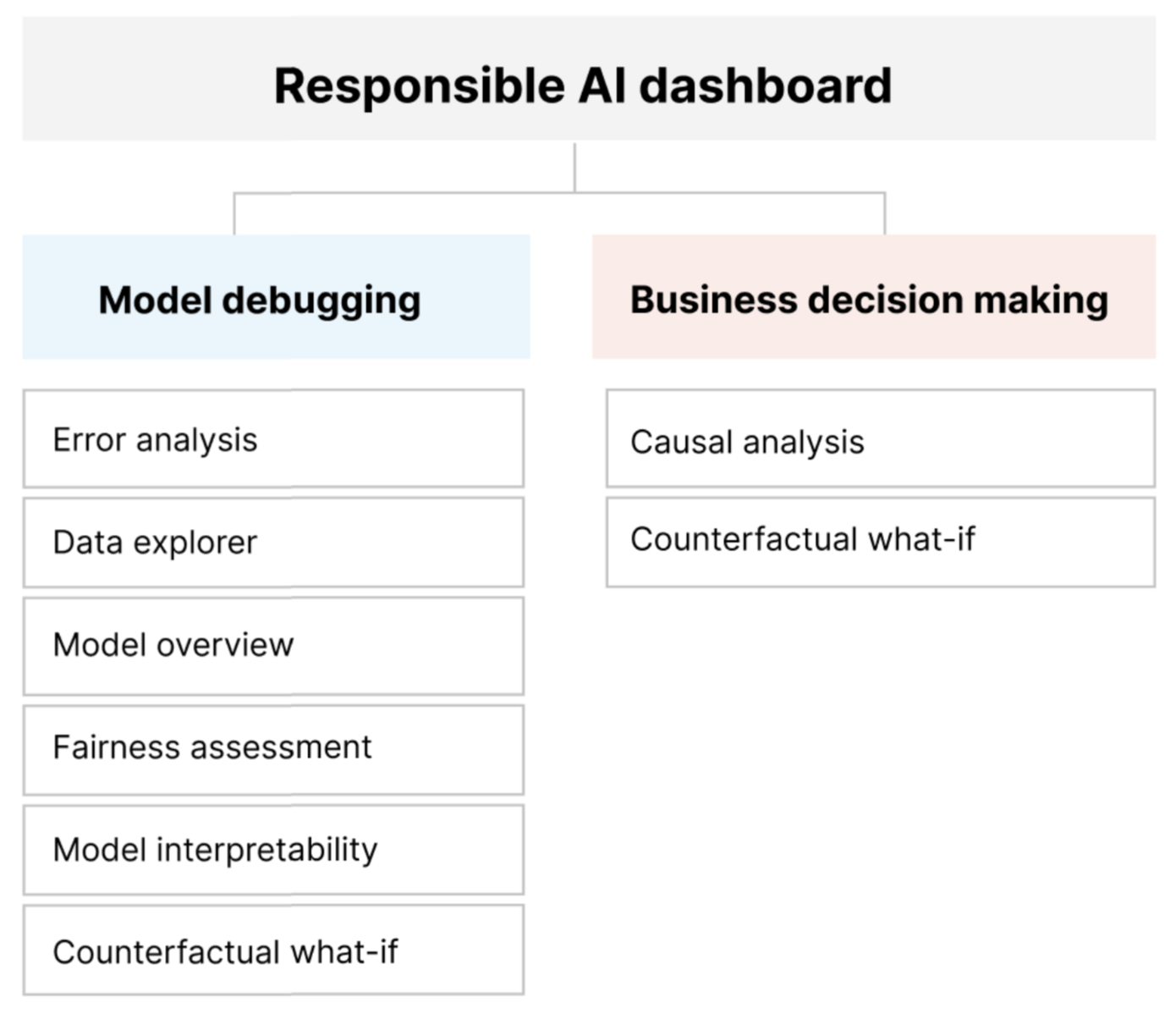
模型调试
评估和调试机器学习模型对于模型的可靠性、可解释性、公平性和合规性至关重要。 它有助于确定 AI 系统的行为方式和原因。 然后,你可以使用这些知识来提高模型性能。 从概念上讲,模型调试包括三个阶段:
识别,通过解决以下问题来了解和识别模型错误和/或公平性问题:
“我的模型有哪些类型的错误?”
“哪些方面的错误最为普遍?”
诊断,通过解决以下问题来探索已识别错误背后的原因:
“发生这些错误的原因是什么?”
“应将资源集中在何处以改进模型?”
缓解,利用前一阶段的识别和诊断见解采取有针对性的缓解步骤并解决以下问题:
“如何改进模型?”
“这些问题存在哪些社会或技术解决方案?”

下表描述了何时使用负责任 AI 仪表板组件来支持模型调试:
| 阶段 | 组件 | 说明 |
|---|---|---|
| 识别 | 错误分析 | 错误分析组件可帮助你更深入地了解模型故障分布,并快速识别错误的数据队列(子组)。 仪表板中此组件的功能来自错误分析包。 |
| 识别 | 公平性分析 | 公平性组件根据性别、种族和年龄等敏感属性定义组。 然后,它评估模型预测如何影响这些组,以及如何减少差异。 它通过探究预测值的分布以及不同组的模型性能指标值来评估模型的性能。 仪表板中此组件的功能来自 Fairlearn 包。 |
| 识别 | 模型概述 | 模型概述组件在概括性的模型预测分布视图中聚合模型评估指标,以便更好地调查其性能。 此组件还支持组公平性评估,突出各个敏感组的模型性能细分。 |
| 诊断 | 数据分析 | 数据分析根据预测和实际结果、错误组和特定特征可视化数据集。 你可以识别过度代表和代表不足的问题,并查看数据在数据集中是如何聚集的。 |
| 诊断 | 模型可解释性 | 可解释性组件生成对机器学习模型预测的人类可理解的解释。 它提供模型行为的多个视图: - 全局解释(例如,哪些特征会影响贷款分配模型的整体行为) - 局部解释(例如,为何批准或拒绝了申请人的贷款申请) 仪表板中此组件的功能来自 InterpretML 包。 |
| 诊断 | 反事实分析和 What-if | 此组件包含两个功能,以方便进行错误诊断: - 生成一组对给定点做出轻微更改的示例,从而改变模型的预测。 即,这些示例显示具有相反模型预测结果的最接近数据点。 - 为各数据点启用交互式和自定义 What-if 扰动,以了解模型如何对特征变化做出反应。 仪表板中此组件的功能来自 DiCE 包。 |
可通过 Fairlearn 等独立工具执行缓解步骤。 有关详细信息,请参阅不公平性缓解算法。
负责任决策
决策是机器学习的最大承诺之一。 负责任 AI 仪表板可通过以下方式帮助你做出明智的业务决策:
借助数据驱动的见解,只需使用历史数据即可进一步了解因果处理对结果的影响。 例如:
“药物对患者的血压会产生哪种影响?”
“向某些客户提供促销优惠对收入会产生哪种影响?”
这些见解通过仪表板的因果推理组件提供。
模型驱动的见解,可以回答用户的问题(例如“下次我能做些什么才能从你的 AI 得到不同结果?”),使用户能够采取措施。 这些见解通过反事实 What-If 组件提供给数据科学家。

探索性数据分析、因果推理和反事实分析功能可帮助你负责任地做出明智的模型驱动和数据驱动决策。
以下负责任 AI 仪表板组件支持做出负责任的决策:
数据分析:在此处可以重用数据资源管理器组件,以了解数据分布并识别过度代表和代表不足的队列。 数据探索是决策的关键部分,因为对数据中代表不足的队列做出明智决策是不可行的。
因果推理:因果推理组件估计在存在干预的情况下实际结果如何变化。 该组件还有助于通过模拟对各种干预的特征反应,并制定规则来确定哪些同类人群将从特定干预中受益,从而构建有前景的干预。 总的来说,利用这些功能,你可以应用新策略并影响实际变化。
此组件的功能来自 EconML 包,该包通过机器学习根据观察数据估计异质性处理效应。
反事实分析:在此处可以重用反事实分析组件,以生成应用于数据点特征的最轻微更改,从而导致相反的模型预测结果。 例如:如果 Taylor 的年收入增加了 10,000 美元并且少开了两张信用卡,则就会从 AI 获得贷款批准。
向用户提供此信息以告知其观点。 这会告诉他们如何采取行动以在未来从 AI 中获得所需的结果。
此组件的功能来自 DiCE 包。
使用负责任 AI 仪表板的原因
虽然负责任 AI 特定领域的个别工具已取得进展,但数据科学家通常需要使用各种工具来整体性地评估他们的模型和数据。 例如:他们可能必须结合使用模型可解释性和公平性评估。
如果数据科学家发现一个工具存在公平性问题,那么他们需要跳转到另一个工具以了解哪些数据或模型因素是问题的根源,然后再采取任何缓解措施。 以下因素使得这一极具挑战性的过程变得更加复杂:
- 没有发现和了解这些工具的中心位置,从而延长了研究和学习新技术所需的时间。
- 不同的工具无法相互通信。 数据科学家在不同工具之间传递数据集、模型和其他元数据时,必须对它们进行处理。
- 指标和可视化效果不易比较,结果难以分享。
负责任 AI 仪表板挑战了这种现状。 它是一个综合性的但又可自定义的工具,将零散的体验汇集在一个中心位置。 它使你能够无缝地加入一个可自定义的框架,以进行模型调试和数据驱动的决策。
使用负责任 AI 仪表板,可以创建数据集队列,将这些队列传递给所有受支持的组件,并观察已识别的队列的模型运行状况。 可以进一步比较各种预生成队列中所有受支持组件的见解,以执行分解分析并查找模型的盲点。
当你准备好与其他利益干系人分享这些见解时,可以使用负责任 AI PDF 记分卡轻松提取它们。 将 PDF 报告附加到合规性报告,或与同事分享该报告以建立信任并获得其批准。
自定义负责任 AI 仪表板的方式
负责任 AI 仪表板的优势在于其可自定义性。 它使用户能够设计符合其特定需求的定制、端到端模型调试和决策工作流。
需要一些灵感? 以下示例演示如何将仪表板组件组合在一起,以便以多种方式分析场景:
| 负责任 AI 仪表板流 | 用例 |
|---|---|
| 模型概述 > 错误分析 > 数据分析 | 通过了解基础数据分布来识别模型错误并进行诊断 |
| 模型概述 > 公平性评估 > 数据分析 | 通过了解基础数据分布来识别模型公平性问题并进行诊断 |
| 模型概述 > 错误分析 > 反事实分析和 What-If | 通过反事实分析诊断个别实例中的错误(导致不同模型预测的最小变化) |
| 模型概述 > 数据分析 | 了解由于数据不平衡或特定数据队列缺乏代表性而引入的错误和公平性问题的根本原因 |
| 模型概述 > 可解释性 | 通过了解模型如何做出预测来诊断模型错误 |
| 数据分析 > 因果推理 | 区分数据中的相关性和因果关系,或决定应用最佳治疗以获得积极的结果 |
| 可解释性 > 因果推理 | 了解模型用于预测的因素是否对实际结果有任何因果效应 |
| 数据分析 > 反事实分析和 What-if | 解决客户关于他们下次可以做些什么以从 AI 系统获得不同结果的问题 |
应使用负责任 AI 仪表板的人员
以下人员可以使用负责任 AI 仪表板及其相应的负责任 AI 记分卡来与 AI 系统建立信任:
- 有兴趣在部署前调试和改进机器学习模型的机器学习专业人员和数据科学家
- 有兴趣与产品经理和业务利益干系人共享其模型运行状况记录以建立信任并获得部署权限的机器学习专业人员和数据科学家
- 要在部署前审查机器学习模型的产品经理和业务利益干系人
- 要审查机器学习模型以了解公平性和可靠性问题的风险官员
- 想要向用户解释模型决策或帮助他们改善结果的 AI 解决方案提供商
- 需要在严格监管领域与监管员和审核员一起审查机器学习模型的专业人士
支持的场景和限制
- 负责任 AI 仪表板目前支持基于表格结构化数据进行训练的回归和分类(二元分类和多类)模型。
- 负责任 AI 仪表板目前只支持在 Azure 机器学习中注册的 MLflow 模型,并且只有一种 sklearn (scikit-learn) 风格。 scikit-learn 模型应该实现
predict()/predict_proba()方法,或者模型应该包装在一个实现predict()/predict_proba()方法的类中。 模型必须可以在组件环境中加载,并且必须是可供选取的。 - 负责任 AI 仪表板当前在仪表板 UI 中可视化最多 5000 个数据点。 在将数据集传递到仪表板之前,应将数据集的下采样控制为至多 5000 个。
- 负责任 AI 仪表板的数据集输入必须是 Parquet 格式的 pandas 数据帧。 目前不支持 NumPy 和 SciPy 稀疏数据。
- 负责任 AI 仪表板目前支持数字或分类功能。 对于分类特征,用户必须显式指定特征名称。
- 负责任 AI 仪表板目前不支持包含 10000 个以上的列的数据集。
- 负责任 AI 仪表板当前不支持 AutoML MLFlow 模型。
- 负责任 AI 仪表板当前不支持通过 UI 注册的 AutoML 模型。
后续步骤
- 了解如何通过 CLI 和 SDK 或 Azure 机器学习工作室 UI 生成负责任 AI 仪表板。
- 了解如何根据在负责任 AI 仪表板中观察到的见解生成负责任 AI 记分卡。