你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 AutoML 预测进行深度学习
本文重点介绍 AutoML 中时序预测的深度学习方法。 有关在 AutoML 中训练预测模型的说明和示例,请参阅为时序预测设置 AutoML 一文。
深度学习在语言建模和蛋白质折叠等领域中有许多用例。 时序预测也受益于深度学习技术的最新进展。 例如,深度神经网络 (DNN) 在高调的 Makridakis 预测竞争的第四次和第五次迭代中,在性能卓越的模型中表现出特征建模方面的突出优势。
在本文中,我们将介绍 AutoML 中 TCNForecaster 模型的结构和操作,帮助你以最佳方式将模型应用于你的场景。
TCNForecaster 简介
TCNForecaster 是一种时序卷积网络 (TCN),它具有专为时序数据设计的 DNN 体系结构。 该模型使用目标数量的历史数据以及相关特征,对目标进行概率预测,一直到指定的预测范围。 下图显示 TCNForecaster 体系结构的主要组成部分:
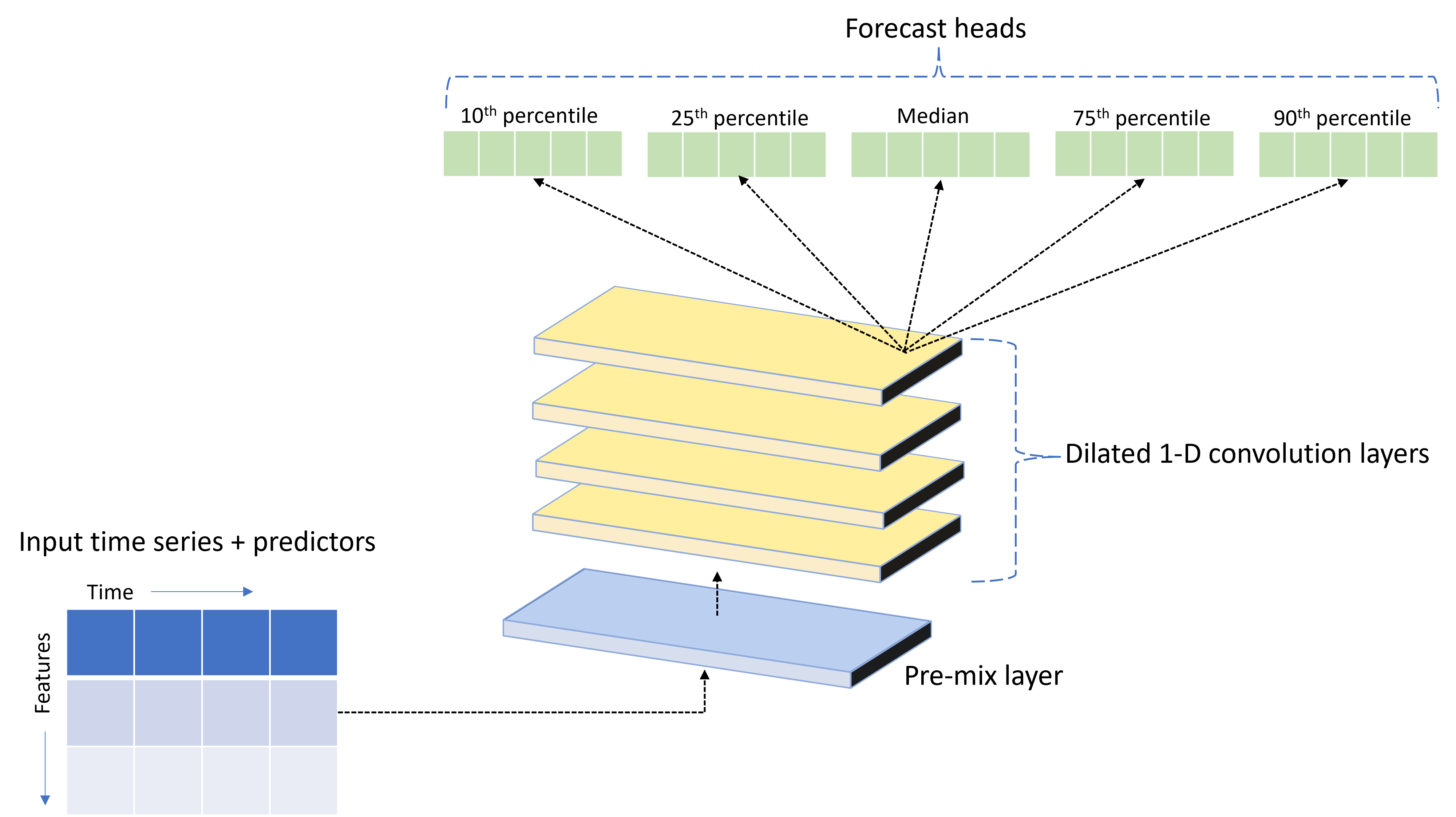
TCNForecaster 具有以下主要组成部分:
- 一个预混合层,用于将输入时序和特征数据混合到卷积堆栈处理的信号通道数组中。
- 按顺序处理通道数组的扩张卷积层堆栈;堆栈中的每个层处理上一层的输出以生成新的通道数组。 此输出中的每个通道都包含来自输入通道的卷积筛选信号的混合。
- 预测头单元的集合,用于合并来自卷积层的输出信号,并从此潜在表示形式生成目标数量的预测。 每个头单元生成预测,一直到预测分布的分位数范围。
扩张的因果卷积
TCN 的中心运算是沿输入信号的时间维度的扩张的因果卷积。 直观地,卷积将输入中附近时间点的值混合在一起。 混合中的比例是卷积的内核或权重,而混合中各点之间的分离是扩张。 输出信号通过沿输入滑动时间内核并在每个位置累积混合,从输入生成。 因果卷积是内核仅混合相对于每个输出点的过去输入值,从而阻止输出“预测”未来。
堆叠扩张卷积使 TCN 能够在内核权重相对较少的输入信号中为长时间的相关性建模。 例如,下图显示了三个堆叠层,每个层中都有一个双权内核以及呈指数级增加的扩张因子:
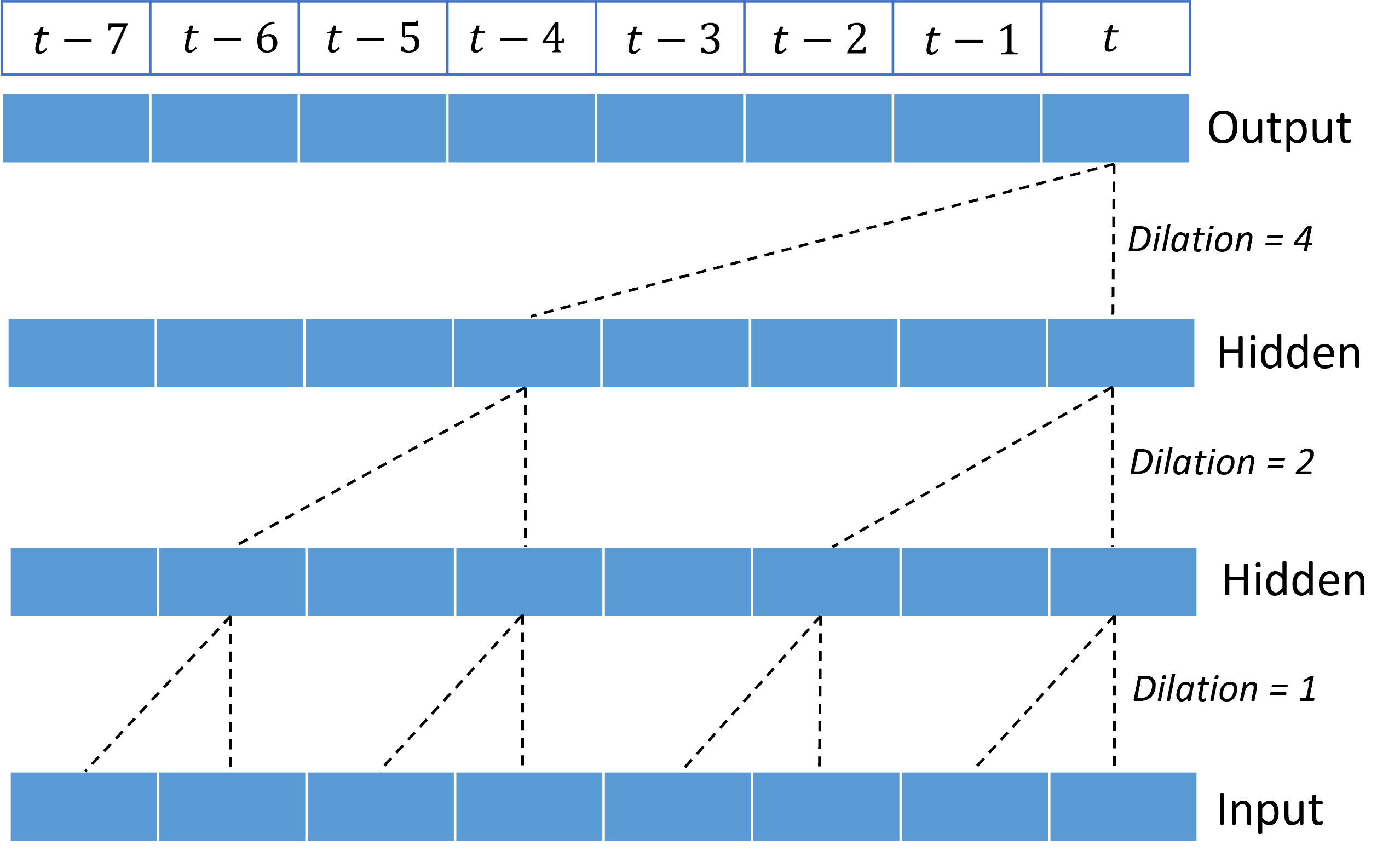
虚线显示网络中的路径,这些路径在 $t$ 时间结束输出。 这些路径涵盖输入中的最后八个点,说明每个输出点都是输入中最近八个点的函数。 卷积网络用于进行预测的历史长度或“回顾”称为“感受野”,完全由 TCN 体系结构决定。
TCNForecaster 体系结构
TCNForecaster 体系结构的核心是预混合和预测头之间的卷积层堆栈。 堆栈在逻辑上划分为称为块的重复单元,这些单元又由残差单元组成。 残差单元在集扩张处应用因果卷积,以及规范化和非线性激活。 重要的是,每个残差单元使用所谓的残差连接将其输出添加到其输入。 这些连接已被证明有利于 DNN 训练,可能是因为它们有助于更高效地通过网络传递信息。 下图显示了一个示例网络卷积层的体系结构,包含两个块,每个块中有三个残差单元:
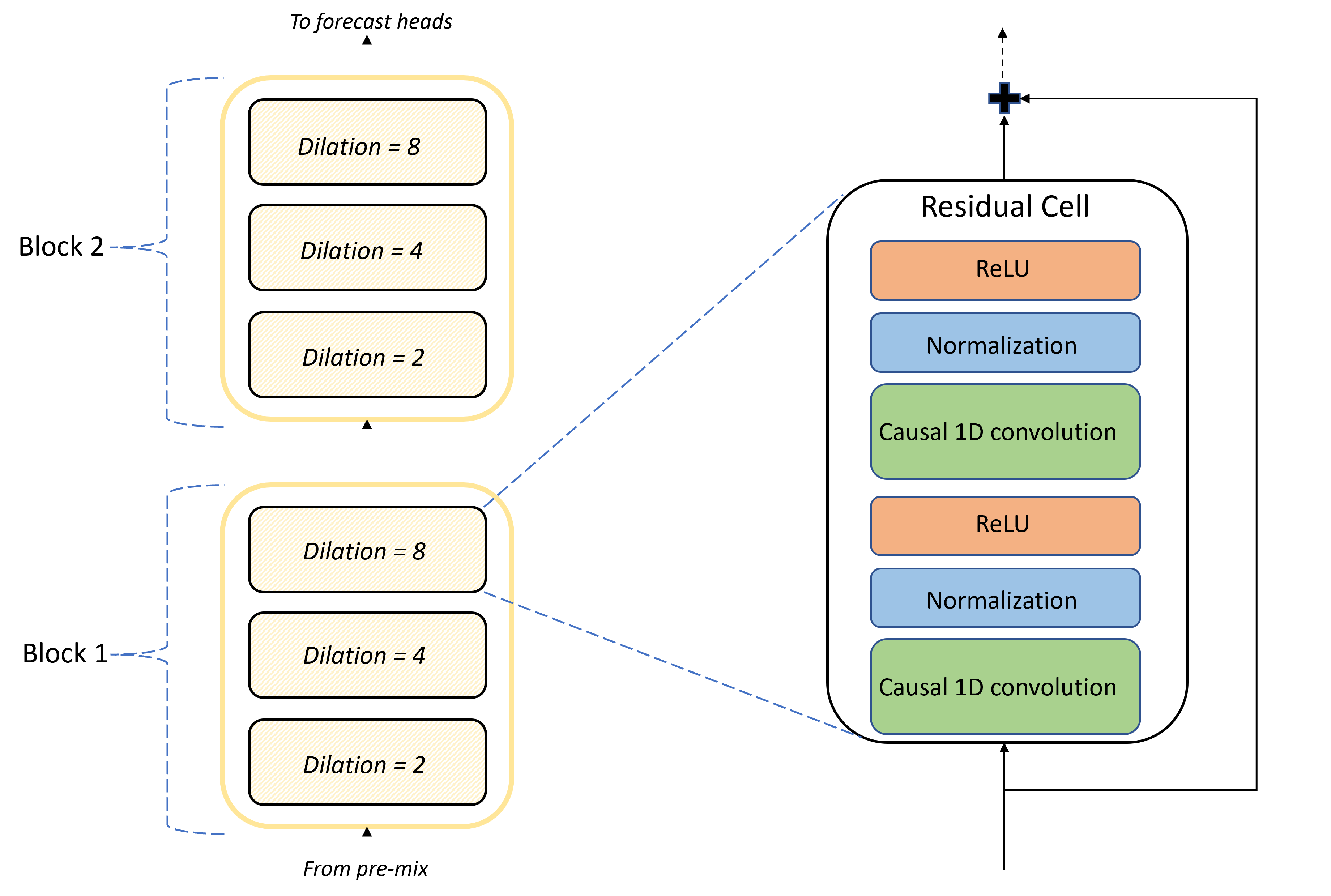
块和单元的数量以及每一层中的信号通道数量控制网络的大小。 下表汇总了 TCNForecaster 的体系结构参数:
| 参数 | 说明 |
|---|---|
| $n_{b}$ | 网络中的块数;也称为深度 |
| $n_{c}$ | 每个块中的单元数 |
| $n_{\text{ch}}$ | 隐藏层中的通道数 |
感受野取决于深度参数,由公式提供,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
我们可以在公式方面对 TCNForecaster 体系结构进行更精确的定义。 让 $X$ 作为输入数组,其中每一行都包含输入数据中的特征值。 我们可以将 $X$ 划分为数值和分类特征数组,$X_{\text{num}}$ 和 $X_{\text{cat}}$。 然后,TCNForecaster 由公式提供,
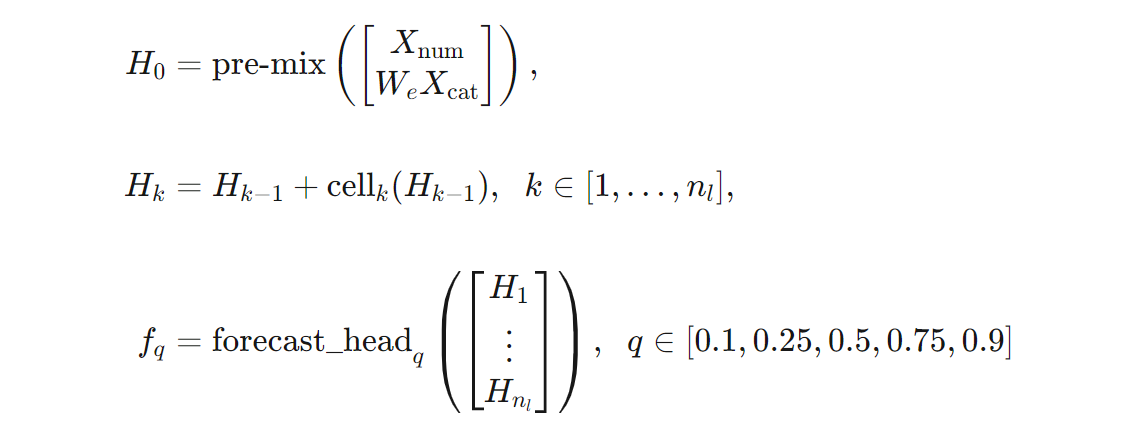
其中,$W_{e}$ 是分类特征的嵌入矩阵,$n_{l} = n_{b}n_{c}$ 是残差单元总数,$H_{k}$ 表示隐藏层输出,$f_{q}$ 是预测分布给定分位数的预测输出。 为了帮助理解,下表中列出了这些变量的维度:
| 变量 | 说明 | 维度 |
|---|---|---|
| $X$ | 输入数组 | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Hidden layer output for $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | 分位数的预测输出 $q$ | $h$ |
在表中,$n_{\text{input}} = n_{\text{features}} + 1$,即预测器/特征变量的数量加上目标数量。 预测头在一次传递中生成的所有预测,一直到最大范围,因此 TCNForecaster 是直接预测器。
AutoML 中的 TCNForecaster
TCNForecaster 是 AutoML 中的可选模型。 若要了解如何使用它,请参阅启用深度学习。
在本部分中,我们将介绍 AutoML 如何使用数据生成 TCNForecaster 模型,包括数据预处理、训练和模型搜索的说明。
数据预处理步骤
AutoML 对数据执行多个预处理步骤,为模型训练做准备。 下表按执行顺序描述了这些步骤:
| 步骤 | 说明 |
|---|---|
| 填充缺失数据 | 插入缺失值和观测间隙,并选择性地填充或删除短时序 |
| 创建日历功能 | 使用派生自日历的特征(例如星期几)以及特定国家/地区的节假日(可选)来扩充输入数据。 |
| 将分类数据编码 | 标签编码字符串和其他分类类型;这包括所有时序 ID 列。 |
| 目标转换 | (可选)根据某些统计测试的结果,将自然对数函数应用于目标。 |
| 标准化 | Z 评分规范化所有数值数据;规范化按特征和时序组执行,由时序 ID 列定义。 |
这些步骤包含在 AutoML 的转换管道中,因此在需要时在推理时会自动应用这些步骤。 在某些情况下,推理管道中包含步骤的反向操作。 例如,如果 AutoML 在训练期间将 $\log$ 转换应用于目标,则原始预测将在推理管道中指数化。
培训
TCNForecaster 遵循其他应用程序在图像和语言中通用的 DNN 训练最佳做法。 AutoML 将预处理的训练数据划分为示例,这些示例将被混合并组合成批。 网络按顺序处理批,使用反向传播和随机梯度下降来优化与损失函数相关的网络权重。 训练可能需要通过完整训练数据进行多次传递;每个传递称为一个时期。
下表列出并描述了 TCNForecaster 训练的输入设置和参数:
| 训练输入 | 说明 | 值 |
|---|---|---|
| 验证数据 | 训练中保留的部分数据,用于指导网络优化和缓解过度拟合。 | 由用户提供,如果未提供,则从训练数据自动创建。 |
| 主要指标 | 每个训练时期结束时针对验证数据的中值预测计算的指标;用于尽早停止和模型选择。 | 由用户选择;规范化均方根误差或规范化平均绝对误差。 |
| 训练时期 | 为网络权重优化运行的最大时期数。 | 100;自动尽早停止逻辑可能会在少量的时期终止训练。 |
| 尽早停止容忍 | 训练停止之前等待主要指标改进的时期数。 | 20 |
| 损失函数 | 网络权重优化的目标函数。 | 分位数损失平均超过第 10、25、50、75 和第 90 个百分位预测。 |
| 批大小 | 批中的示例数。 每个示例的维度 $n_{\text{input}} \times t_{\text{rf}}$ 用于输入,$h$ 用于输出。 | 根据训练数据中的示例总数自动确定;最大值为 1024。 |
| 嵌入维度 | 分类特征的嵌入空间的维度。 | 自动设置为每个特征中非重复值数的第四个根,向上舍入为最接近的整数。 阈值的最小值为 3,最大值为 100。 |
| 网络体系结构* | 控制网络大小和形状的参数:深度、单元数和通道数。 | 由模型搜索确定。 |
| 网络权重 | 控制信号混合、分类嵌入、卷积内核权重以及预测值的映射的参数。 | 随机初始化,然后针对损失函数进行优化。 |
| 学习速率* | 控制在梯度下降的每个迭代中可以调整多少网络权重;动态减少近收敛。 | 由模型搜索确定。 |
| 信息漏失率* | 控制应用于网络权重的信息漏失正则化程度。 | 由模型搜索确定。 |
标有星号 (*) 的输入由下一部分中介绍的超参数搜索确定。
模型搜索
AutoML 使用模型搜索方法查找以下超参数的值:
- 网络深度或卷积块数,
- 每个块的单元数,
- 每个隐藏层中的通道数,
- 网络正则化的信息漏失率,
- 学习速率。
这些参数的最佳值可能会因问题场景和训练数据而异,因此 AutoML 在超参数值空间中训练多个不同的模型,并根据验证数据的主要指标分数选择最佳模型。
模型搜索有两个阶段:
- AutoML 对 12 个“标志性”模型执行搜索。 标志性模型是静态的,选择用于合理跨越超参数空间。
- AutoML 继续使用随机搜索在超参数空间中进行搜索。
满足停止条件时,搜索将终止。 停止条件取决于预测训练作业配置,但一些示例包括时间限制、要执行的搜索试验次数限制以及验证指标未改进时的尽早停止逻辑。
后续步骤
- 了解如何设置 AutoML 以训练时序预测模型。
- 了解 AutoML 中的预测方法。
- 浏览 AutoML 中预测相关的常见问题。