你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
预处理文本
本文介绍 Azure 机器学习设计器中的一个组件。
使用“预处理文本”组件来清理和简化文本。 它支持以下常见文本处理操作:
- 删除非索引字词
- 使用正则表达式搜索并替换特定目标字符串
- 词形还原,它将多个相关字词转换为同一个规范形式
- 大小写规范化
- 删除某些特定类别的字符,如数字、特殊字符和重复字符序列(如 "aaaa")
- 标识和删除电子邮件和 URL
“预处理文本”组件目前仅支持英语。
配置文本预处理
在 Azure 机器学习中,将“预处理文本”组件添加到你的管道。 可以在“文本分析”下找到此组件。
连接一个数据集,其中至少有一个列包含文本。
从“语言”下拉列表中选择语言。
要清理的文本列:选择要预处理的列。
删除非索引字词:如果要将预定义的非索引字列表应用于文本列,请选择此选项。
非索引字列表与语言相关并可自定义。
词形还原:如果希望以规范形式表示字词,请选择此选项。 此选项可用于减少其他类似文本标记的唯一匹配项的数量。
词形还原过程与语言高度相关。
检测句子:如果希望组件在执行分析时插入句子边界标记,请选择此选项。
此组件使用一系列三管道字符
|||来表示语句终止符。使用正则表达式执行可选的“查找替换”操作。 正则表达式将先于所有其他内置选项进行处理。
- 自定义正则表达式:定义要搜索的文本。
- 自定义替换字符串:定义单个替换值。
将大小写规范化为小写:如果要将 ASCII 大写字符转换为小写形式,请选择此选项。
如果不对字符执行规范化,系统会将同一单词的大写和小写形式视为两个不同的单词。
还可以从已处理的输出文本中删除以下类型的字符或字符序列:
删除数字:选择此选项可以删除指定语言中的所有数字字符。 标识性数字与域和语言相关。 如果数字字符是已知单词的组成部分,可能不会删除该数字。 阅读技术说明了解详细信息。
删除特殊字符:使用此选项可以删除任何非字母数字的特殊字符。
删除重复字符:选择此选项可以删除任何序列中重复次数超过两次的多余字符。 例如,"aaaaa"这样的序列可缩减为 "aa"。
删除电子邮件地址:选择此选项可以删除格式
<string>@<string>的任何序列。删除 URL:选择此选项可以删除任何包含以下 URL 前缀的序列:
http、https、ftp、www
展开谓词缩写形式:此选项仅适用于使用谓词缩写形式的语言;目前仅限英语。
例如,选择此选项后,可以将短语 "wouldn't stay there"(不会留在那里)替换为 "would not stay there"。
将反斜杠规范化为斜杠:选择此选项可将
\\的所有实例映射到/。将标记拆分为特殊字符:如果想将带有
&、-等字符的词语与这些字符拆分开来,请选择此选项。 此选项还可以减少重复次数超过两次的特殊字符。例如,字符串
MS---WORD将拆分成三个标记,MS、-和WORD。提交管道。
技术说明
Studio(经典版)中的“预处理文本”组件和设计器使用不同的语言模型。 设计器使用 spaCy 中的多任务 CNN 定型模型。 不同模型提供不同的分词器和词性标记器,会产生不同的结果。
以下是一些示例:
| 配置 | 输出结果 |
|---|---|
| 选择全部选项 说明: 对于“WC-3 3test 4test”中的“3test”这样的情况,设计器会删除整个单词(“3test”),因为在此上下文中,词性标记器会将此标记(“3test”)指定为数字,因此此组件会根据词性将其删除。 |
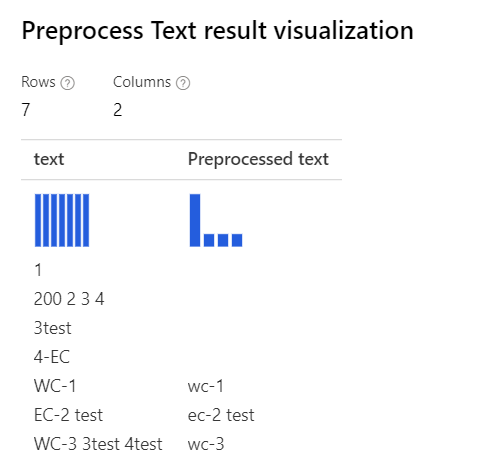
|
仅选择 Removing number说明: 对于类似于“3test”、“4-EC”这样的情况,设计器分词器不会拆分这些词,而是将其视为完整标记。 因此不会删除这些词中的数字。 |

|
还可以使用正则表达式输出自定义结果:
| 配置 | 输出结果 |
|---|---|
| 选中所有选项的 自定义正则表达式: (\s+)*(-|\d+)(\s+)* 自定义替换字符串: \1 \2 \3 |

|
仅 Removing number 选定自定义 正则表达式: (\s+)*(-|\d+)(\s+)* 自定义替换字符串: \1 \2 \3 |
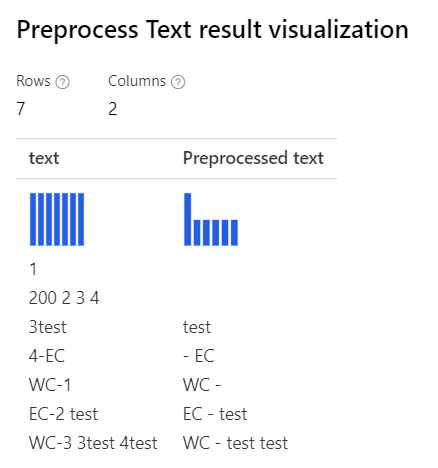
|
后续步骤
请参阅 Azure 机器学习可用的组件集。