你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
“评估模型”组件
本文介绍 Azure 机器学习设计器中的一个组件。
使用此组件可以评估已训练模型的准确性。 你提供了一个数据集,其中包含从模型生成的分数,“评估模型”组件将计算一组行业标准的评估指标。
“评估模型”返回的指标取决于评估的模型类型:
- 分类模型
- 回归模型
- 聚类分析模型
提示
如果你还不熟悉模型评估,我们建议观看 Stephen Elston 博士的视频系列,该系列是 EdX 机器学习课程的一部分.
如何使用“评估模型”
将评分模型的“得分数据集”输出或将数据分配到聚类的“结果数据集”输出连接到“评估模型”的左侧输入端口。
注意
如果使用“在数据集中选择列”等组件来选择部分输入数据集,请确保存在“实际标签”列(用于模型训练)、“评分概率”列和“评分标签”列以计算指标(如 AUC、二进制分类/异常检测的准确性)。 存在“实际标签”列、“评分标签”列以计算多类分类/回归的指标。 存在“赋值”列、“DistancesToClusterCenter no.X”列(X 是重心索引,范围为 0,...,重心数量 -1)以计算聚类分析的指标。
重要
- 若要评估结果,输出数据集应包含符合“评估模型”组件要求的特定分数列名称。
Labels列会被视为实际标签。- 对于回归任务,要计算的数据集必须设一个列,名为
Regression Scored Labels,表示评分标签。 - 对于二进制分类任务,要计算的数据集必须具有两列,名为
Binary Class Scored Labels、Binary Class Scored Probabilities,分别表示评分标签和概率。 - 对于多分类任务,要计算的数据集必须设一个列,名为
Multi Class Scored Labels,表示评分标签。 如果上游组件的输出没有这些列,则需要根据上述要求进行修改。
[可选] 将评分模型的“得分数据集”输出或第二个模型的“将数据分配到聚类”的“结果数据集”输出连接到“评估模型”的右侧输入端口 。 你可以在相同数据上轻松比较两个不同模型的结果。 两个输入算法应为同一算法类型。 你也可以使用不同的参数对相同数据运行两次,然后比较两次运行的评分。
注意
算法类型是指机器学习算法下的“双类分类”、“多类分类”、“回归”、“聚类分析”。
提交管道以生成评估分数。
结果
运行“评估模型”后,选择组件以打开右侧的“评估模型”导航面板 。 然后,选择“输出 + 日志”选项卡,然后在该选项卡上,“数据输出”部分包含多个图标。 “可视化”图标有一个条形图图标,这是查看结果的第一种方法。
对于二元分类,单击“可视化”图标后,可以直观显示二元混淆矩阵。 对于多元分类,可以在“输出 + 日志”选项卡下找到混淆矩阵绘图文件,如下所示:
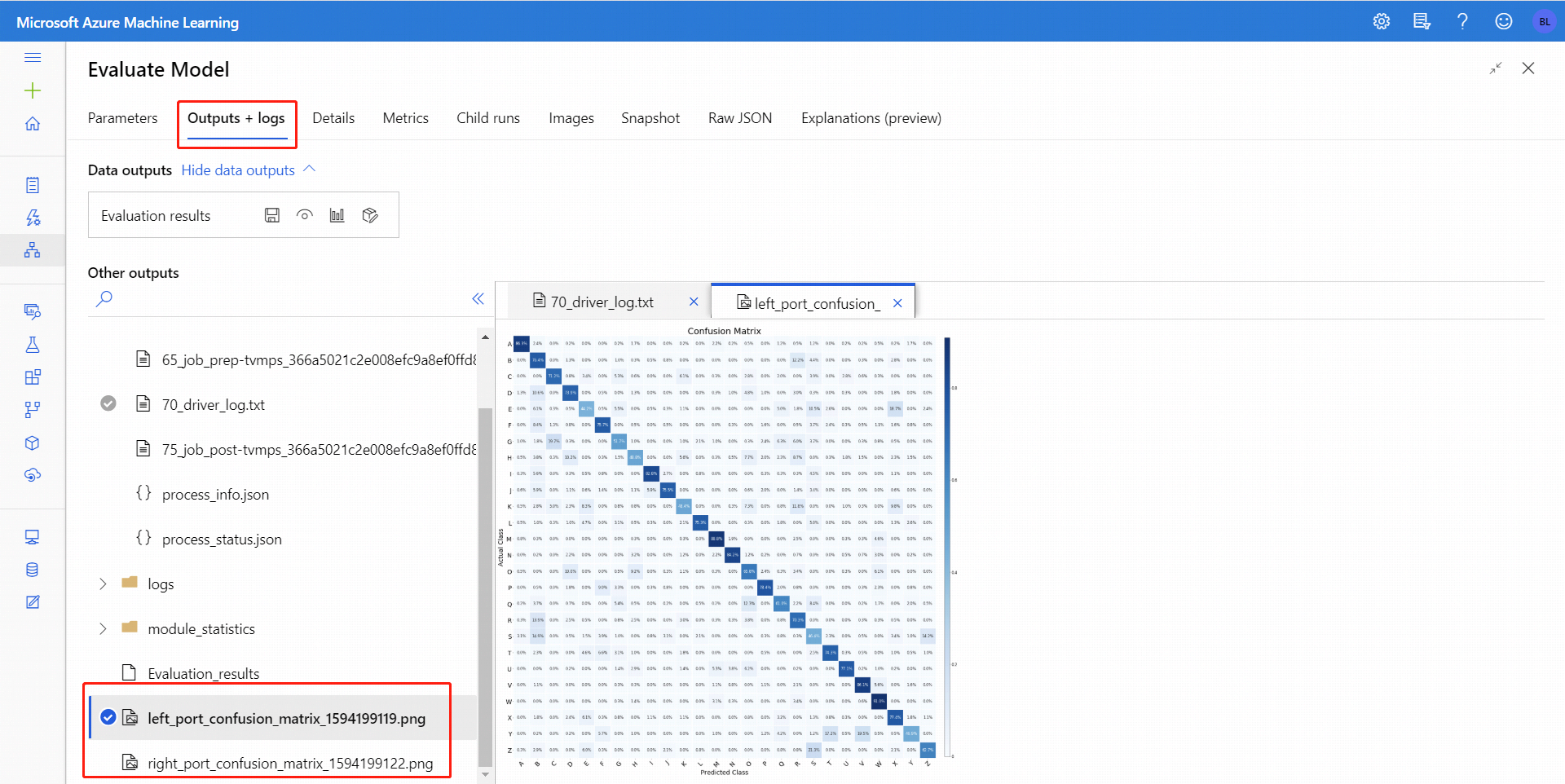
如果将数据集连接到“评估模型”的两种输入,结果将包含这两个数据集或这两个模型的指标。 附加到左侧端口的模型或数据先显示在报告中,其后是附加到右侧端口的数据集或模型的指标。
例如,下图表示使用不同参数的相同数据上生成的两个聚类分析模型的结果比较。
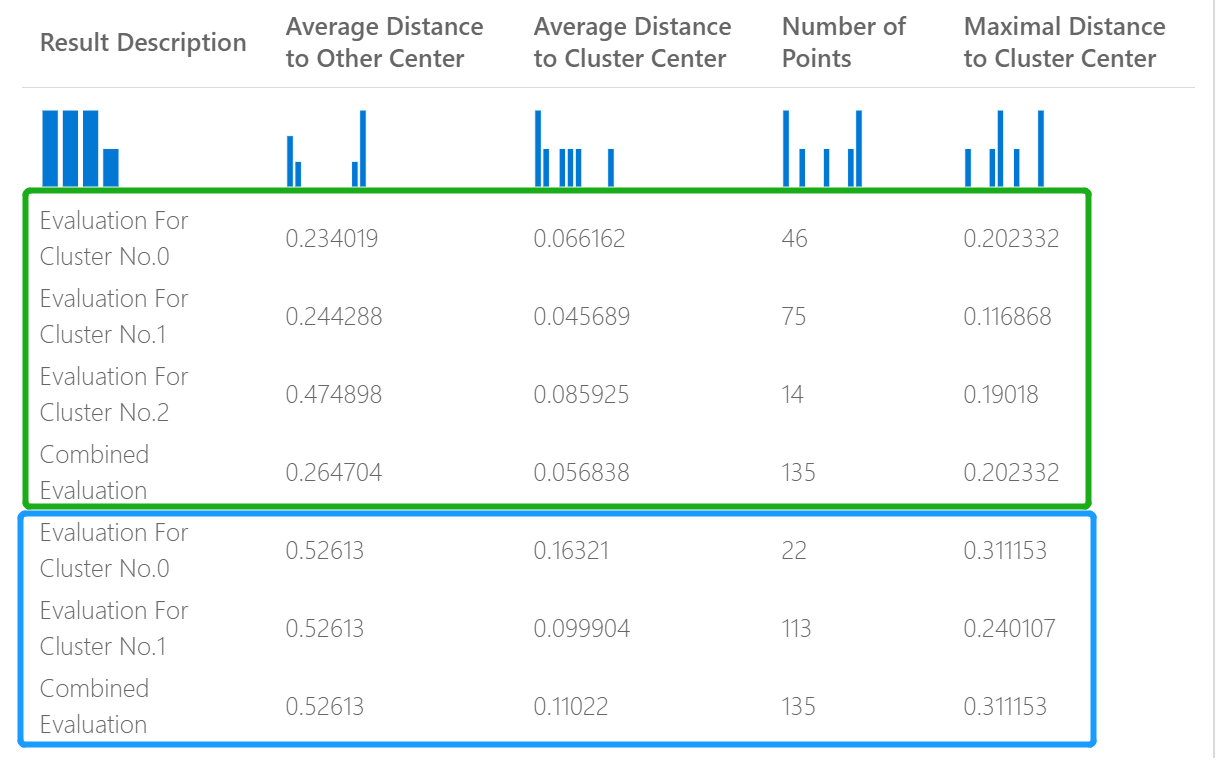
因为这是聚类分析模型,所以,计算结果不同于比较两个回归模型的分数或两个分类模型的结果。 不过,提供的结果在总体上是相同的。
指标
本部分介绍针对支持与“评估模型”配合使用的特定模型类型返回的指标:
分类模型的指标
评估二元分类模型时,会报告以下指标。
“准确度”衡量分类模型的优劣,即真实结果占总体的比例。
“精准率”是真实结果与所有正面结果之比。 查准率 = TP/(TP+FP)
“查全率”是实际检索到的相关实例总数的分数。 查全率 = TP/(TP+FN)
“F1 分数”计算为查准率与查全率的加权平均值,介于 0 到 1 之间,理想的 F1 分数值为 1。
“AUC”度量绘制的曲线下面的面积(在 y 轴上绘制真报率,在 x 轴上绘制误报率)。 此指标非常有用,因为它提供单个数字让你比较不同类型的模型。 AUC 不随分类阈值而变化。 它度量模型预测的质量,而不管选择的分类阈值如何。
回归模型的指标
回归模型返回的指标旨在估算错误量。 如果观测值与预测值之间的差很小,则认为模型能够很好地拟合数据。 不过,查看残差模式(任何一个预测点与其对应实际值之间的差)可以很好地判断模型中的潜在偏差。
将报告以下指标来评估线性回归模型。 其他回归模型(例如快速林分位数回归)可能具有不同的指标。
“平均绝对误差 (MAE)”度量预测对实际结果的接近程度;因此,分数越低越好。
“均方根误差 (RMSE)”创建单个值用于汇总模型中的误差。 求差的平方时,指标将忽略过预测与欠预测之差。
“相对绝对误差 (RAE)”是预期值与实际值之间的相对绝对差;之所以是相对的,是因为平均差将除以算术平均值。
“相对平方误差 (RSE)”类似地通过除以实际值的总平方误差来归一化预测值的总平方误差。
“决定系数”(通常称为 R 2)将模型的预测能力表示为 0 和 1 之间的值。 如果为 0,则模型是随机的(不解释任何信息);1 表示完美拟合。 但是,在解释 R2 值时应谨慎,因为低值可能是完全正常的,而高值可能会令人怀疑。
聚类分析模型指标
由于聚类分析模型在许多方面与分类和回归模型有很大差别,因此评估模型也会为聚类分析模型返回一组不同的统计信息。
聚类分析模型返回的统计信息说明分配给每个聚类的数据点数量、聚类之间的隔离量以及每个聚类中数据点的聚集程度。
聚类分析模型的统计信息是整个数据集的平均值,并附带有包含每个聚类的统计信息的行。
评估聚类分析模型时,将报告以下指标。
“到其他中心的平均距离”列中的分数表示该聚类中每个点与所有其他聚类中心的平均距离。
“到聚类中心的平均距离”列中的分数表示某个聚类中所有点到该聚类中心的接近程度。
“点数”列显示为每个聚类分配了多少数据点,以及所有聚类中数据点的总数。
如果分配给聚类的数据点数量小于可用的数据点总数,则意味着无法将数据点分配给聚类。
“到聚类中心的最大距离”列中的分数表示每个点与该点的聚类中心之间的最大距离。
如果此数字较高,则可能表示该聚类相当分散。 你应该将统计信息与“到聚类中心的平均距离”一起查看,以确定聚类的分布情况。
各部分结果底部的“组合评估”分数列出了在该特定模型中创建的聚类的平均得分。
后续步骤
请参阅 Azure 机器学习可用的组件集。