你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure HDInsight IO 缓存提高 Apache Spark 工作负载的性能
注意
- IO 缓存在 Spark 2.3 之前一直受支持,在 Spark 2.4 (HDInsight 4.0) 和 Spark 3.1.2 (HDInsight 5.0) 中将不受支持
IO 缓存是 Azure HDInsight 的数据缓存服务,可用于提高 Apache Spark 作业的性能。 IO 缓存也适用于可在 Apache Spark 群集上运行的 Apache TEZ 和 Apache Hive 工作负载。 IO 缓存使用名为 RubiX 的开源缓存组件。 RubiX 是用于可从云存储系统访问数据的大数据分析引擎的本地磁盘缓存。 RubiX 在缓存系统中是唯一的,因为它使用固态硬盘 (SSD),而不是保留操作内存以供缓存。 IO 缓存服务可在群集的每个工作节点上启动和管理 RubiX 元数据服务器。 它还可以配置群集的所有服务以便透明使用 RubiX 缓存。
大多数 SSD 提供超过 1 GB/秒的带宽。 此带宽由操作系统内存中文件缓存补充,提供的带宽足以加载大数据计算处理引擎(如 Apache Spark)。 剩余的操作内存可供 Apache Spark 处理很大程度依赖于内存的任务(如数据重组)。 独占使用操作内存可让 Apache Spark 实现最佳资源使用情况。
注意
IO 缓存当前将 RubiX 用作缓存组件,但在该服务的将来版本中可能会有所更改。 请使用 IO 缓存接口,并且不要直接对 RubiX 实现执行任何依赖项。 目前仅有 Azure BLOB 存储支持 IO 缓存。
Azure HDInsight IO 缓存的优点
使用 IO 缓存可为从 Azure Blob 存储读取数据的作业提高性能。
使用 IO 缓存时,无需对 Spark 作业进行更改即可看到性能提升。 禁用 IO 缓存时,此 Spark 代码会从 Azure Blob 存储远程读取数据:spark.read.load('wasbs:///myfolder/data.parquet').count()。 激活 IO 缓存时,同一行代码会导致通过 IO 缓存进行缓存读取。 执行以下读取操作时,会从 SSD 本地读取数据。 HDInsight 群集上的工作节点配备有本地附加的专用 SSD 驱动器。 HDInsight IO 缓存使用这些本地 SSD 进行缓存,这样可以将延迟降为最低级别并最大程度地增加带宽。
入门
默认情况下,在预览版中将停用 Azure HDInsight IO 缓存。 IO 缓存可用于运行 Apache Spark 2.3 的 Azure HDInsight 3.6+ Spark 群集。 要在 HDInsight 4.0 上激活 IO 缓存,请执行以下步骤:
在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.net,其中CLUSTERNAME是群集的名称。选择左侧的“IO 缓存”服务。
选择“操作”(在 HDI 3.6 中为“服务操作”)和“激活”。
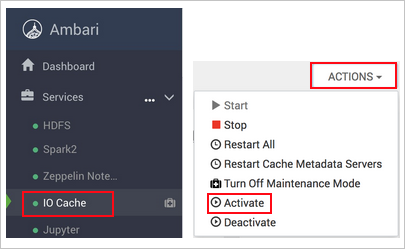
确认重新启动群集上所有受影响的服务。
注意
即使进度栏显示已激活,但 IO 缓存实际上未启用,直到重新启动其他受影响的服务。
疑难解答
启用 IO 缓存后可能会收到运行 Spark 作业时出现的磁盘空间错误。 出现这些错误的原因是 Spark 还将本地磁盘存储用于在执行数据重组操作期间存储数据。 启用 IO 缓存并减少 Spark 存储空间后,Spark 可能会耗尽 SSD 空间。 IO 缓存所用的空间量默认为 SSD 空间总量的一半。 IO 缓存的磁盘空间使用量可以在 Ambari 中进行配置。 如果收到磁盘空间错误,请减少 IO 缓存所用的 SSD 空间量,并重新启动该服务。 若要更改为 IO 缓存设置的空间,请执行以下步骤:
在 Apache Ambari 中,选择左侧的“HDFS”服务。
依次选择“配置”和“高级”选项卡。
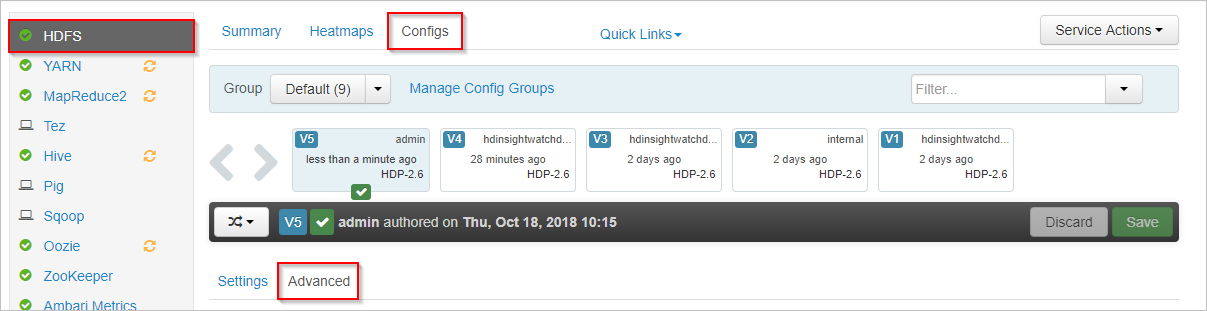
向下滚动并展开“自定义 core-site”区域。
查找属性 hadoop.cache.data.fullness.percentage。
更改框中的值。

选择右上角的“保存”。
选择“重新启动”>“重新启动所有受影响的项”。

选择“确认全部重启”。
如果不起作用,请禁用 IO 缓存。
后续步骤
阅读有关 IO 缓存的详细信息,包括以下博客文章中的性能基准:Apache Spark 作业通过 HDInsight IO 缓存使速度加快 9 倍