你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 Azure HDInsight 中将 Apache Spark 和 Apache Hive 与 Hive Warehouse Connector 集成
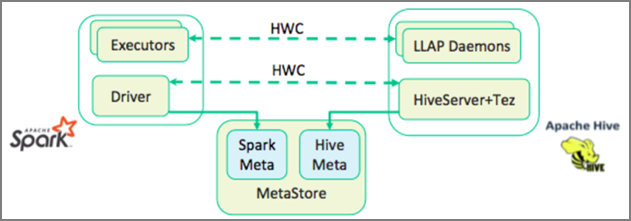
Apache Hive Warehouse Connector (HWC) 是一个库,可让你更轻松地使用 Apache Spark 和 Apache Hive。 它支持在 Spark DataFrames 和 Hive 表之间移动数据等任务。 此外,通过将 Spark 流数据定向到 Hive 表中。 Hive Warehouse Connector 的工作方式类似于 Spark 与 Hive 之间的桥梁。 它还支持将 Scala、Java 和 Python 作为开发编程语言。
通过 Hive Warehouse Connector 可利用 Hive 和 Spark 的独特功能构建功能强大的大数据应用程序。
Apache Hive 为原子性、一致性、隔离性和持久性 (ACID) 数据库事务提供支持。 有关 Hive 中的 ACID 和事务的详细信息,请参阅 Hive 事务。 Hive 还通过 Apache Ranger 以及在 Apache Spark 中不可用的低延迟分析处理 (LLAP) 提供详细安全控制。
Apache Spark 的结构化流式处理 API 提供了 Apache Hive 中没有的流式处理功能。 从 HDInsight 4.0 开始,Apache Spark 2.3.1 及更高版本和 Apache Hive 3.1.0 使用单独的元存储目录,这会增加互操作性的难度。
通过 Hive Warehouse Connector (HWC) 可更轻松地将 Spark 和 Hive 一起使用。 HWC 库将数据从 LLAP 守护程序并行加载到 Spark 执行程序。 与从 Spark 到 Hive 的标准 JDBC 连接相比,此过程可更高效且更具适应性。 这为 HWC 提供了两种不同的执行模式:
- 通过 HiveServer2 的 Hive JDBC 模式
- 使用 LLAP 守护程序的 Hive LLAP 模式 [推荐]
默认情况下,HWC 配置为使用 Hive LLAP 守护程序。 对于使用上述模式及其相应 API 执行 Hive 查询(读取和写入)的信息,请参阅 HWC API。
Hive Warehouse Connector 支持的部分操作包括:
- 描述表
- 为 ORC 格式的数据创建表
- 选择 Hive 数据和检索数据帧
- 将数据帧批量写入到 Hive
- 执行 Hive 更新语句
- 从 Hive 读取表数据、在 Spark 中转换数据,然后将数据写入到新的 Hive 表
- 使用 HiveStreaming 将数据帧或 Spark 流写入到 Hive
Hive Warehouse Connector 设置
重要
- 不支持将 Spark 2.4 企业安全性套餐群集上安装的 HiveServer2 Interactive 实例与 Hive Warehouse Connector 一起使用。 相反,必须配置一个独立的 HiveServer2 Interactive 群集来承载 HiveServer2 Interactive 工作负载。 不支持使用单一 Spark 2.4 群集的 Hive Warehouse Connector 配置。
- 不支持将 Hive Warehouse Connector (HWC) 库用于启用了工作负载管理 (WLM) 功能的 Interactive Query 群集。
在你仅有 Spark 工作负载并想要使用 HWC 库的情况下,请确保 Interactive Query 群集未启用工作负载管理功能(未在 Hive 配置中设置hive.server2.tez.interactive.queue配置)。
对于同时存在 Spark 工作负载 (HWC) 和 LLAP 原生工作负载的情况,你需要创建使用共享的元存储数据库的两个单独的 Interactive Query 群集。 一个群集用于原生 LLAP 工作负载,可以在其中根据需要启用 WLM 功能;另一个群集用于仅限 HWC 的工作负载,不应当在其中配置 WLM 功能。 需要注意的是,从两个群集都可以查看 WLM 资源计划,即使只在一个群集中启用了该计划。 请勿在禁用了 WLM 功能的群集中对资源计划进行任何更改,因为这可能会影响另一个群集中的 WLM 功能。 - 尽管 Spark 支持 R 计算语言以简化其数据分析,但 Hive Warehouse Connector (HWC) 库不支持与 R 结合使用。若要执行 HWC 工作负载,可以使用仅支持 Scala、Java 和 Python 的 JDBC 式 HiveWarehouseSession API 执行从 Spark 到 Hive 的查询。
- Arrays/Struct/Map 类型等复杂数据类型不支持在 JDBC 模式下通过 HiveServer2 执行查询(读取和写入)。
- HWC 仅支持以 ORC 文件格式写入。 HWC 不支持非 ORC 写入(例如:parquet 和文本文件格式)。
Hive Warehouse Connector 对于 Spark 和 Interactive Query 工作负责需要单独的群集。 按照以下步骤在 Azure HDInsight 中设置这些群集。
支持的群集类型和版本
| HWC 版本 | Spark 版本 | InteractiveQuery 版本 |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interactive Query 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interactive Query 3.1 | HDI 5.0 |
创建群集
使用存储帐户和自定义的 Azure 虚拟网络创建 HDInsight Spark 4.0 群集。 有关在 Azure 虚拟网络中创建群集的信息,请参阅将 HDInsight 添加到现有虚拟网络。
使用与 Spark 群集相同的存储帐户和 Azure 虚拟网络创建 HDInsight Interactive Query (LLAP) 4.0 群集。
配置 HWC 设置
收集初步信息
在 Web 浏览器中,导航到
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVE,其中 LLAPCLUSTERNAME 是 Interactive Query 群集的名称。导航到“摘要”>“HiveServer2 交互式 JDBC URL”并记下该值。 该值可能类似于:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive。导航到配置>高级>高级 hive-site>hive.zookeeper.quorum,并记下该值。 该值可能类似于:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181。导航到配置>高级>常规>hive.metastore.uris,并记下该值。 该值可能类似于:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083。导航到配置>高级>高级 hive-interactive-site>hive.llap.daemon.service.hosts,并记下该值。 该值可能类似于:
@llap0。
配置 Spark 群集设置
在 Web 浏览器中导航到
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configs,其中 CLUSTERNAME 是 Apache Spark 群集的名称。展开“自定义 spark2-defaults”。

选择“添加属性...”,以添加以下配置:
配置 值 spark.datasource.hive.warehouse.load.staging.dir如果使用的是 ADLS Gen2 存储帐户,请使用 abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
如果使用的是 Azure Blob 存储帐户,请使用wasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp。
设置为合适的 HDFS 兼容分段目录。 如果有两个不同的群集,则分段目录应该是 LLAP 群集存储帐户的分段目录中的文件夹,以便 HiveServer2 有权访问它。 将STORAGE_ACCOUNT_NAME替换为群集使用的存储帐户的名称,并将STORAGE_CONTAINER_NAME替换为存储容器的名称。spark.sql.hive.hiveserver2.jdbc.url之前从“HiveServer2 交互式 JDBC URL”获取的值 spark.datasource.hive.warehouse.metastoreUri之前从“hive.metastore.uris”获取的值。 spark.security.credentials.hiveserver2.enabled对于 YARN 群集模式为 true,对于 YARN 客户端模式为false。spark.hadoop.hive.zookeeper.quorum之前从“hive.zookeeper.quorum”获取的值。 spark.hadoop.hive.llap.daemon.service.hosts之前从“hive.llap.daemon.service.hosts”获取的值。 保存更改并重启所有受影响的组件。
为企业安全性套餐 (ESP) 群集配置 HWC
企业安全性套餐 (ESP) 为 Azure HDInsight 中的 Apache Hadoop 群集提供企业级功能,如基于 Active Directory 的身份验证、多用户支持以及基于角色的访问控制。 有关 ESP 的详细信息,请参阅在 HDInsight 中使用企业安全性套餐。
除了上一部分中提到的配置之外,请添加以下配置以在 ESP 群集上使用 HWC。
从 Spark 群集的 Ambari Web UI 导航到“Spark2”>“配置”>“自定义 spark2-defaults”。
更新以下属性。
配置 值 spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summary,其中 CLUSTERNAME 是 Interactive Query 群集的名称。 单击 HiveServer2 Interactive。 你将会看到运行 LLAP 的头节点的完全限定的域名 (FQDN),如屏幕截图中所示。 将<llap-headnode>替换为此值。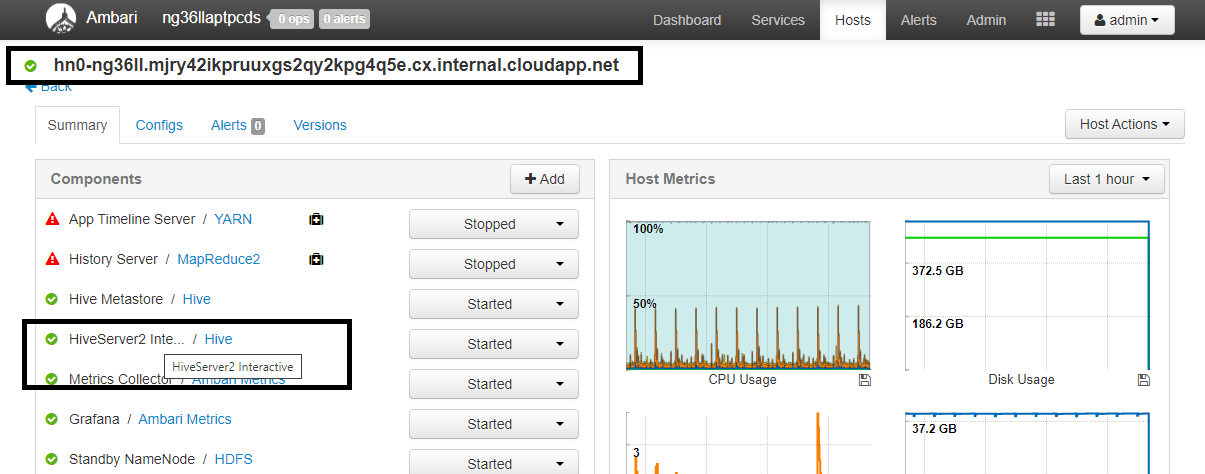
使用 ssh 命令连接到 Interactive Query 群集。 在
/etc/krb5.conf文件中查找default_realm参数。 以大写字符串的形式使用此值替换<AAD-DOMAIN>,否则会找不到凭据。
例如:
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET。
保存更改并根据需要重启组件。
Hive Warehouse Connector 用法
可以在几种不同方法之间进行选择,以使用 Hive Warehouse Connector 连接到 Interactive Query 群集并执行查询。 支持的方法包括以下工具:
下面是一些从 Spark 连接到 HWC 的示例。
Spark-shell
使用该方式可通过修改版的 Scala shell 交互式地运行 Spark。
使用 ssh 命令连接到 Apache Spark 群集。 编辑以下命令,将 CLUSTERNAME 替换为群集的名称,然后输入该命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.net在 ssh 会话中,执行以下命令以记下
hive-warehouse-connector-assembly版本:ls /usr/hdp/current/hive_warehouse_connector使用上面标识的
hive-warehouse-connector-assembly版本编辑下面的代码。 然后执行命令启动 spark shell:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false启动 spark shell 后,可以使用以下命令启动 Hive 仓库连接器实例:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-submit
Spark-submit 是用于将任何 Spark 程序(或作业)提交到 Spark 群集的实用程序。
spark-submit 作业将按照我们的指示,设置和配置 Spark 和 Hive Warehouse Connector、执行我们传递给它的程序,然后干净地发布被使用的资源。
将 scala/java 代码连同依赖项一起生成到程序集 jar 后,使用以下命令启动 Spark 应用程序。 将 <VERSION> 和 <APP_JAR_PATH> 替换为实际值。
YARN 客户端模式
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN 群集模式
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
在 pySpark 中编写整个应用程序并打包成 .py 文件 (Python) 后,也会使用该实用程序,以便可将整个代码提交到 Spark 群集进行执行。
对于 Python 应用程序,请传递一个 .py 文件而非 /<APP_JAR_PATH>/myHwcAppProject.jar,然后将以下配置 (Python .zip) 文件添加到具有 --py-files 的搜索路径。
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
对企业安全性套餐 (ESP) 群集运行查询
在启动 spark-shell 或 spark-submit 之前使用 kinit。 将 USERNAME 替换为有权访问群集的域帐户的名称,然后执行以下命令:
kinit USERNAME
保护 Spark ESP 群集上的数据
输入以下命令,创建包含一些示例数据的
demo表:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');使用以下命令查看该表的内容。 在应用策略之前,
demo表会显示完整的列。hive.executeQuery("SELECT * FROM demo").show()
应用仅显示该列最后四个字符的列掩码策略。
转到 Ranger 管理 UI (
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/)。在“Hive”下单击用于群集的 Hive 服务。
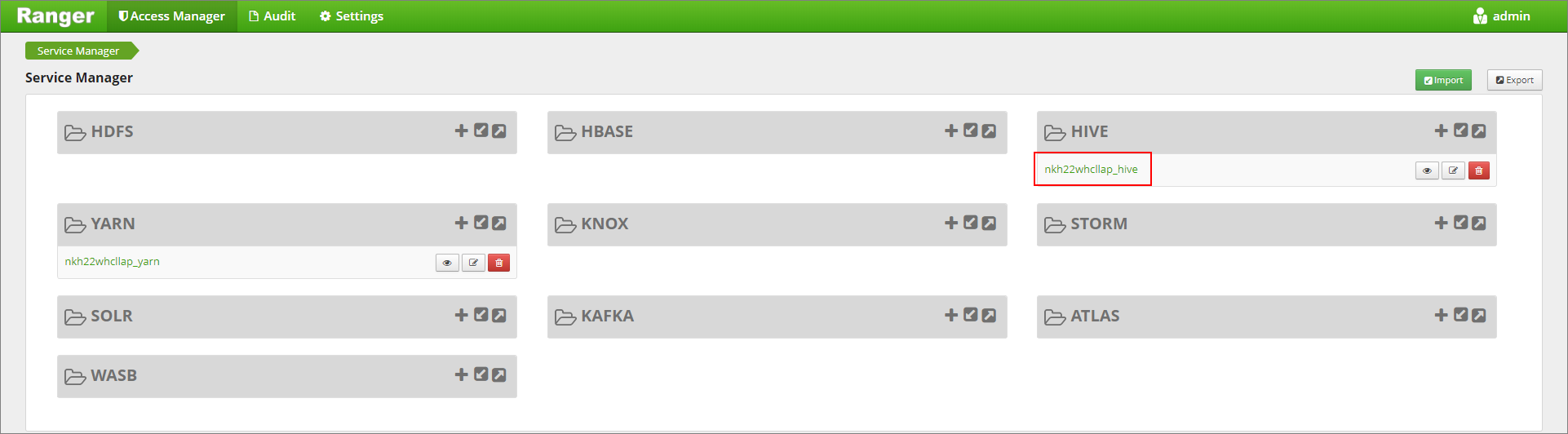
单击“掩码”选项卡,然后单击“添加新策略”

提供所需的策略名称。 从“选择掩码选项”菜单中选择数据库“默认”、Hive 表“演示”、Hive 列“名称”、用户“rsadmin2”、访问类型“选择”和“部分掩码: 显示最后 4 个”。 单击“添加” 。
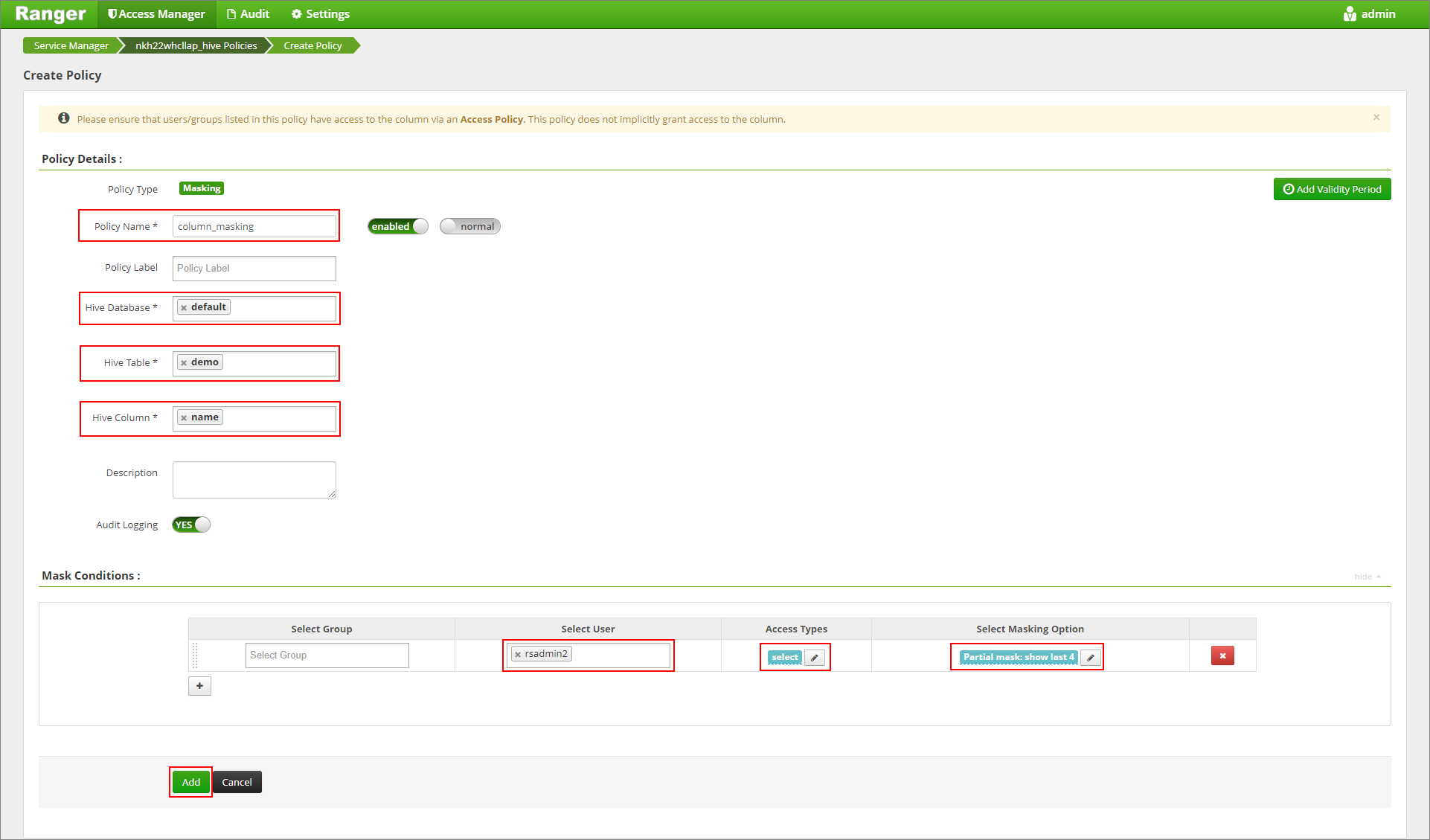
再次查看表的内容。 应用 Ranger 策略之后,我们只能看到该列的最后四个字符。
