你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure HDInsight 对 Apache Hadoop HDFS 进行故障排除
了解使用 Hadoop 分布式文件系统 (HDFS) 时的常见问题和解决方法。 有关完整的命令列表,请参阅 HDFS 命令指南和文件系统 Shell 指南。
如何从群集内访问本地 HDFS?
问题
从 HDInsight 群集内通过命令行和应用程序代码(而不是使用 Azure Blob 存储或 Azure Data Lake Storage)访问本地 HDFS。
解决步骤
在命令提示符下,按原义使用
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...,如以下命令中所示:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /user从源代码按原义使用 URI
hdfs://mycluster/,如以下示例应用程序中所示:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }使用以下命令在 HDInsight 群集上运行已编译的 .jar 文件(例如,名为
java-unit-tests-1.0.jar的文件):hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
写入 blob 时的存储异常
问题
使用 hadoop 或 hdfs dfs 命令在 HBase 群集上编写大于或等于 ~12 GB 的文件时,可能会遇到以下错误:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
原因
写入 Azure 存储时,HDInsight 群集上的 HBase 的块大小将默认为 256 KB。 尽管这对 HBase API 或 REST API 来说可良好运行,但使用 hadoop 或 hdfs dfs 命令行实用工具时则会导致错误。
解决方法
使用 fs.azure.write.request.size 指定更大的块大小。 可以使用 -D 参数基于使用情况执行此修改。 以下命令是将此参数用于 hadoop 命令的示例:
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
还可使用 Apache Ambari 以全局方式增加 fs.azure.write.request.size 的值。 可以使用以下步骤在 Ambari Web UI 中更改该值:
在浏览器中,转到群集的 Ambari Web UI。 URL 为
https://CLUSTERNAME.azurehdinsight.net,其中CLUSTERNAME是群集的名称。 出现提示时,输入群集的管理员名称和密码。在屏幕左侧选择“HDFS”,然后选择“配置”选项卡。
在“筛选...”字段中输入
fs.azure.write.request.size。将值从 262144 (256 KB) 更改为新的值。 例如,4194304 (4 MB)。
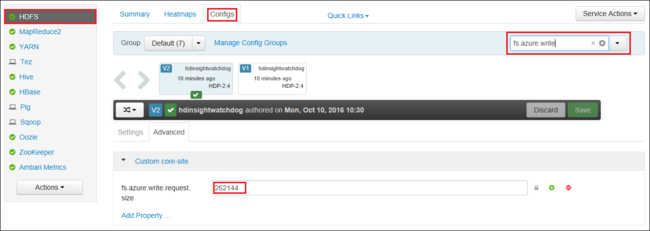
有关如何使用 Ambari 的详细信息,请参阅使用 Apache Ambari Web UI 管理 HDInsight 群集。
du
-du 命令显示给定目录中包含的文件和目录的大小或文件的长度(如果它只是一个文件)。
-s 选项生成所显示文件长度的聚合汇总。
-h 选项设置文件大小的格式。
示例:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
rm
-rm 命令删除指定为参数的文件。
示例:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
后续步骤
如果你的问题未在本文中列出,或者无法解决问题,请访问以下渠道之一获取更多支持:
通过 Azure 社区支持获取 Azure 专家的解答。
联系 @AzureSupport,这是用于改进客户体验的官方 Microsoft Azure 帐户。 它可以将 Azure 社区成员连接到适当的资源,为他们提供解答、支持和专家建议。
如果需要更多帮助,可以从 Azure 门户提交支持请求。 从菜单栏中选择“支持”,或打开“帮助 + 支持”中心。 有关更多详细信息,请参阅如何创建 Azure 支持请求。 Microsoft Azure 订阅中带有对订阅管理和计费支持的访问权限,技术支持通过 Azure 支持计划之一提供。