你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
排查 HDInsight 群集速度慢或作业失败问题
如果 HDInsight 群集上的应用程序处理数据运行速度缓慢或者发生故障并返回错误代码,你可以使用多个故障排除选项。 如果作业的运行时间超过预期或者响应时间比平时要慢,原因可能是群集的上游组件(例如运行群集的服务)发生故障。 但是,这些速度变慢问题的最常见原因是缩放不足。 创建新的 HDInsight 群集时,请选择适当的虚拟机大小。
若要诊断群集变慢或故障的原因,请收集有关环境的各个方面的信息,例如,关联的 Azure 服务、群集配置和作业执行信息。 一种有效的诊断方法是尝试在另一个群集上再现错误状态。
- 步骤 1:收集有关问题的数据。
- 步骤 2:验证 HDInsight 群集环境。
- 步骤 3:查看群集的运行状况。
- 步骤 4:查看环境堆栈和版本。
- 步骤 5:检查群集日志文件。
- 步骤 6:检查配置设置。
- 步骤 7:在不同的群集上再现故障。
步骤 1:收集有关问题的数据
HDInsight 提供了许多工具用于识别和排查群集问题。 下面逐步讲解这些工具的用法,并提供有关查明问题的建议。
识别问题
若要帮助识别问题,请考虑以下问题:
- 预期发生的情况是什么? 相反,发生了什么?
- 运行该过程花费了多长时间? 运行该过程应该花费多长时间?
- 在此群集上,我的任务是否一直都缓慢运行? 它们在其他群集上的运行速度是否更快?
- 此问题第一次是何时发生的? 从那以后,它多久发生一次?
- 群集配置是否有任何更改?
群集详细信息
重要的群集信息包括:
- 群集名称。
- 群集区域 - 检查区域中断。
- HDInsight 群集类型和版本。
- 为头节点和工作节点指定的 HDInsight 实例的类型和数量。
Azure 门户可以提供此信息:

还可以使用 Azure CLI:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
另一个选项是使用 PowerShell。 有关详细信息,请参阅使用 Azure PowerShell 在 HDInsight 中管理 Apache Hadoop 群集。
步骤 2:验证 HDInsight 群集环境
每个 HDInsight 群集依赖于各种 Azure 服务,以及 Apache HBase 和 Apache Spark 等开源软件。 HDInsight 群集还可能调用其他 Azure 服务,例如 Azure 虚拟网络。 群集上运行的任何服务或者外部服务都可能导致群集故障。 群集服务配置更改也可能导致群集故障。
服务详细信息
- 检查开源库发行版本。
- 检查 Azure 服务中断。
- 检查 Azure 服务使用限制。
- 检查 Azure 虚拟网络子网配置。
使用 Ambari UI 查看群集配置设置
可以在 Apache Ambari 中使用 Web UI 和 REST API 对 HDInsight 群集进行管理和监视。 基于 Linux 的 HDInsight 群集上已随附 Ambari。 在 Azure 门户的“HDInsight”页上选择“群集仪表板”窗格。 选择“HDInsight 群集仪表板”窗格打开 Ambari UI,并输入群集登录凭据。
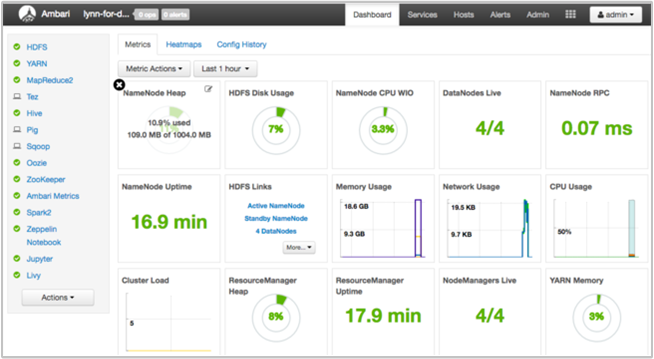
若要打开服务视图列表,请在 Azure 门户页上选择“Ambari 视图”。 此列表的内容取决于安装的库。 例如,可能会显示“YARN 队列管理器”、“Hive 视图”和“Tez 视图”。 选择某个服务链接以查看配置和服务信息。
检查 Azure 服务中断
HDInsight 依赖于多个 Azure 服务。 它在 Azure HDInsight 中运行虚拟服务器,在 Azure Blob 存储或 Azure DataLake Storage 中存储数据和脚本,在 Azure 表存储中为日志文件编制索引。 这些服务发生中断(不过这种情况很少见)可能会导致 HDInsight 出现问题。 如果群集发生意外的速度变慢或故障,请检查 Azure 状态仪表板。 每个服务的状态按区域列出。 请检查群集的区域,以及所有相关服务的区域。
检查 Azure 服务使用限制
在启动大型群集或同时启动多个群集时,如果超出 Azure 服务限制,则群集可能发生故障。 服务限制因 Azure 订阅而异。 有关详细信息,请参阅 Azure 订阅和服务限制、配额与约束。 可以使用资源管理器提高核心配额请求,向 Microsoft 请求增加可用 HDInsight 资源(例如 VM 核心和 VM 实例)的数量。
检查发行版本
将群集版本与最新的 HDInsight 发行版进行比较。 每个 HDInsight 发行版包含改进项目,例如新的应用程序、功能、修补程序和 bug 修复。 影响群集的问题可能已在最新的发行版本中得到解决。 如果可能,请使用最新版本的 HDInsight 和关联的库(例如 Apache HBase、Apache Spark 等)重新运行群集。
重启群集服务
如果群集速度变慢,请考虑通过 Ambari UI 或 Azure 经典 CLI 重启服务。 群集可能遇到暂时性的错误,而重启是稳定环境并可能提高性能的最快捷方法。
步骤 3:查看群集的运行状况
HDInsight 群集由虚拟机实例上运行的不同类型的节点组成。 可以监视每个节点上存在的资源严重不足、网络连接问题,以及可能降低群集速度的其他问题。 每个群集包含两个头节点,大多数群集类型包含工作节点和边缘节点的组合。
有关每个群集类型使用的各个节点的说明,请参阅使用 Apache Hadoop、Apache Spark、Apache Kafka 等在 HDInsight 中设置群集。
下列部分介绍如何检查每个节点和整个群集的运行状况。
使用 Ambari UI 仪表板获取群集运行状况的快照
Ambari UI 仪表板 (https://<clustername>.azurehdinsight.net) 提供群集运行状况的概述,例如运行时间、内存、网络和 CPU 使用率、HDFS 磁盘使用率,等等。 使用 Ambari 的“主机”部分可以查看主机级别的资源。 还可以停止和重启服务。
检查 WebHCat 服务
Apache Hive、Apache Pig 或 Apache Sqoop 作业失败的常见场合之一是 WebHCat(或 Templeton)服务发生故障。 WebHCat 是 Hive、Pig、Scoop 和 MapReduce 等远程作业执行使用的 REST 接口。 WebHCat 将作业提交请求转换为 Apache Hadoop YARN 应用程序,并返回派生自 YARN 应用程序状态的状态。 以下部分介绍常见的 WebHCat HTTP 状态代码。
BadGateway(502 状态代码)
此代码是来自网关节点的常规消息,也是最常见的故障状态代码。 发生此故障的可能原因之一是活动头节点上的 WebHCat 服务已关闭。 若要检查是否存在这种情况,请使用以下 CURL 命令:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari 将显示一条警报,其中指出了 WebHCat 服务已在哪些主机上关闭。 可以通过在相应的主机上重启 WebHCat 服务使其恢复运行。
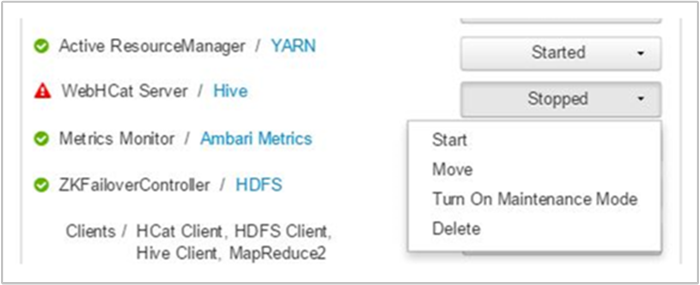
如果 WebHCat 服务器仍未运行,请查看操作日志中的故障消息。 有关更多详细信息,请查看节点上提到的 stderr 和 stdout 文件。
WebHCat 超时
如果等待响应花费的时间超过两分钟,HDInsight 网关会超时并返回 502 BadGateway。 WebHCat 向 YARN 服务查询作业状态,如果 YARN 做出响应的时间超过两分钟,则该请求可能超时。
在这种情况下,请查看 /var/log/webhcat 目录中的以下日志:
- webhcat.log 是服务器将日志写入到的 Log4j 日志
- webhcat-console.log 是启动服务器时的 stdout
- webhcat-console-error.log 是服务器进程的 stderr
注意
每个 webhcat.log 每日滚动更新,生成名为 webhcat.log.YYYY-MM-DD 的文件。 选择想要调查的时间范围内的相应文件。
以下部分介绍 WebHCat 超时的一些可能原因。
WebHCat 级超时
当 WebHCat 承受包含 10 个以上开放套接字的负载时,需要更长的时间来建立新的套接字连接,从而可能导致超时。 若要列出 WebHCat 的源和目标网络连接,请在当前活动头节点上使用 netstat:
netstat | grep 30111
30111 是 WebHCat 侦听的端口。 开放套接字数应小于 10。
如果没有开放套接字,则上述命令不会生成结果。 若要检查 Templeton 是否已启动并在侦听端口 30111,请使用:
netstat -l | grep 30111
YARN 级超时
Templeton 调用 YARN 来运行作业,Templeton 与 YARN 之间的通信可能导致超时。
在 YARN 级别有两种类型的超时:
提交某个 YARN 作业可能花费了过长的时间,从而导致超时。
如果打开
/var/log/webhcat/webhcat.log日志文件并搜索“queued job”,可以看到执行时间过长(超过 2000 毫秒)的条目,以及等待时间不断增加的条目。排队作业的等待时间之所以不断增加,是因为新作业的提交速率大于已完成的旧作业的提交速率。 在 YARN 内存全部用完后,
joblauncher queue无法再从默认队列借用容量。 因此,不能再接受新的作业进入作业启动器队列。 此行为可能导致等待时间变得越来越长,从而导致超时错误,并继而引发其他许多错误。下图显示了过度使用内存 (714.4%) 时的作业启动器队列。 只要默认队列中仍有可借用的容量,则此状态都是可接受的。 但是,当群集完全被占用并且 YARN 内存容量已被 100% 使用时,新作业必须等待,最终导致超时。

可通过两种方法解决此问题:降低新作业的提交速度,或通过扩展群集来提高旧作业的消耗速度。
YARN 处理可能需要花费较长时间,从而导致超时。
列出所有作业:这是一个非常耗时的调用。 此调用通过 YARN 资源管理器枚举应用程序,并针对每个已完成的应用程序从 YARN JobHistoryServer 获取状态。 如果作业数目较大,此调用可能超时。
列出七天以前的作业:HDInsight YARN JobHistoryServer 配置为将已完成作业的信息保留七天(
mapreduce.jobhistory.max-age-ms值)。 尝试枚举已清除的作业会导致超时。
诊断这些问题的步骤:
- 确定要排查的 UTC 时间范围
- 选择相应的
webhcat.log文件 - 查看这段时间的警告和错误消息
其他 WebHCat 故障
HTTP 状态代码 500
在 WebHCat 返回 500 的大多数情况下,错误消息中会包含有关故障的详细信息。 否则,请在
webhcat.log中仔细查看警告和错误消息。作业失败
有时,尽管与 WebHCat 的交互成功,但作业失败。
Templeton 以
stderr的形式将作业控制台输出收集到statusdir中,这些信息通常对故障排除很有帮助。stderr包含实际查询的 YARN 应用程序标识符。
步骤 4:查看环境堆栈和版本
Ambari UI 中的“堆栈和版本”页提供有关群集服务配置和服务版本历史记录的信息。 错误的 Hadoop 服务库版本可能是群集故障的原因。 在 Ambari UI 中选择“管理”菜单,然后选择“堆栈和版本”。 选择页面上的“版本”选项卡查看服务版本信息:
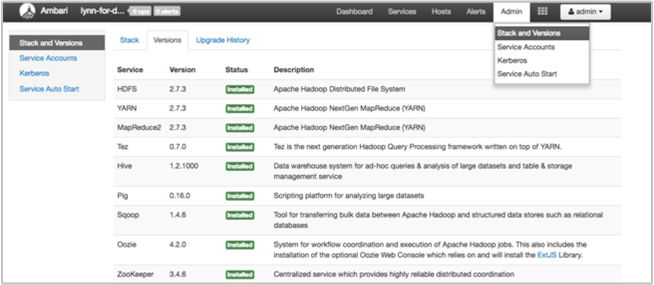
步骤 5:检查日志文件
构成 HDInsight 群集的许多服务和组件会生成多种类型的日志。 前文介绍了 WebHCat 日志文件。 可以根据以下部分中所述,调查其他多种有用的日志文件来缩小群集问题的范围。
HDInsight 群集由多个节点组成,其中的大多数节点负责运行已提交的作业。 作业可并发运行,但日志文件只能以线性方式显示结果。 HDInsight 执行新任务,并终止一开始就无法完成的其他任务。 整个活动将记录到
stderr和syslog文件。脚本操作日志文件显示群集的创建过程中发生的错误或意外的配置更改。
Hadoop 步骤日志标识了在执行某个包含错误的步骤过程中启动的 Hadoop 作业。
检查脚本操作日志
使用 HDInsight 脚本操作可以手动或者根据指定在群集上运行脚本。 例如,可以使用脚本操作在群集上安装其他软件,或者更改配置设置的默认值。 检查脚本操作日志可以深入了解群集安装和配置期间发生的错误。 可以通过选择 Ambari UI 中的“操作”按钮,或者访问默认存储帐户中的日志,来查看脚本操作的状态。
脚本操作日志位于 \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE 目录中。
使用 Ambari 快速链接查看 HDInsight 日志
HDInsight Ambari UI 中包含一些“快速链接”部分。 若要访问 HDInsight 群集中特定服务的日志链接,请打开该群集的 Ambari UI,然后在左侧列表中选择服务链接。 依次选择“快速链接”下拉列表、所需的 HDInsight 节点及其关联日志的链接。
例如,对于 HDFS 日志:
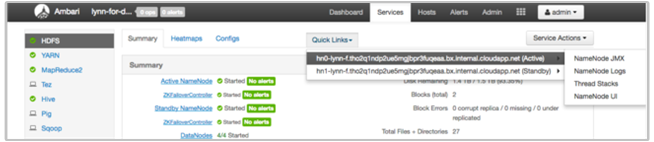
查看 Hadoop 生成的日志文件
HDInsight 群集会生成日志,这些日志将写入到 Azure 表和 Azure Blob 存储。 YARN 会创建自身的执行日志。 有关详细信息,请参阅管理 HDInsight 群集的日志。
查看堆转储
堆转储包含应用程序内存的快照,其中包括当时的变量值,这对于诊断运行时发生的问题很有用。 有关详细信息,请参阅为基于 Linux 的 HDInsight 上的 Apache Hadoop 服务启用堆转储。
步骤 6:检查配置设置
HDInsight 群集中预配置了相关服务(例如 Hadoop、Hive、HBase 等)的默认设置。 根据群集的类型、硬件配置、节点数目、运行的作业类型和正在处理的数据(以及数据处理方式),可能需要优化配置。
有关优化大多数方案的性能配置的详细说明,请参阅使用 Apache Ambari 优化群集配置。 在使用 Spark,请参阅优化 Apache Spark 作业的性能。
步骤 7:在不同的群集上再现故障
若要帮助诊断群集错误的原因,请使用相同的配置启动新群集,然后逐个重新提交已失败作业的步骤。 先检查每个步骤的结果,然后再处理下一个步骤。 使用此方法也许能够纠正和重新运行单个失败的步骤。 此方法还有一个优点,那就是只会加载输入数据一次。
- 使用与有故障群集相同的配置创建新的测试群集。
- 将第一个作业步骤提交到测试群集。
- 当此步骤完成处理时,请在步骤日志文件中查看错误。 连接到测试群集的主节点并在其中查看日志文件。 步骤日志文件只会在该步骤运行了一段时间、已完成或失败之后才显示。
- 如果第一个步骤成功,请运行下一个步骤。 如果出现错误,请在日志文件中调查错误。 如果这是代码中的错误,请予以纠正,然后重新运行该步骤。
- 继续运行,直到所有步骤都可完成运行且不出错。
- 完成调试测试群集后,请将其删除。