你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
什么是 HDInsight on AKS 中的 Apache Spark™? (预览版)
注意
我们将于 2025 年 1 月 31 日停用 Azure HDInsight on AKS。 在 2025 年 1 月 31 日之前,你需要将工作负荷迁移到 Microsoft Fabric 或同等的 Azure 产品,以避免工作负荷突然终止。 订阅上的剩余群集会被停止并从主机中移除。
在停用日期之前,仅提供基本支持。
重要
此功能目前以预览版提供。 Microsoft Azure 预览版的补充使用条款包含适用于 beta 版、预览版或其他尚未正式发布的 Azure 功能的更多法律条款。 有关此特定预览版的信息,请参阅 Azure HDInsight on AKS 预览版信息。 如有疑问或功能建议,请在 AskHDInsight 上提交请求并附上详细信息,并关注我们以获取 Azure HDInsight Community 的更多更新。
Apache Spark™ 是并行处理框架,支持使用内存中处理来提升大数据分析应用程序的性能。
Apache Spark™ 提供用于内存中群集计算的基元。 Spark 作业可以将数据加载和缓存到内存中并重复地对其进行查询。 内存中计算比基于磁盘的应用程序(例如通过 Hadoop 分布式文件系统 (HDFS) 共享数据的 Hadoop)快。 Apache Spark 允许与 Scala 和 Python 编程语言相集成,使你可以像处理本地集合一样处理分布式数据集。 无需将所有内容构造为映射和化简操作。
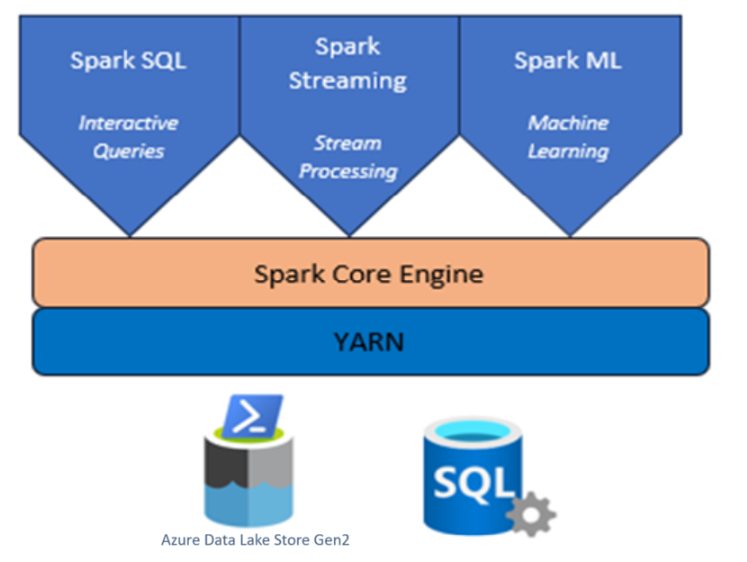
使用 HDInsight on AKS 的 Apache Spark 群集
Azure HDInsight 是适用于企业的分析服务,具有托管、全面且开源的特点。
Azure HDInsight on AKS 中的 Apache Spark™ 是 Microsoft Azure 中的托管 Spark 服务。 借助 Azure HDInsight on AKS 中的 Apache Spark,可以在 Azure 中存储和处理所有数据。 HDInsight 中的 Spark 群集与Azure Data Lake Storage Gen2兼容,允许在现有数据存储上应用 Spark 处理。
用于 AKS 上 HDInsight 的 Apache Spark 框架使用内存中处理功能实现快速数据分析和群集计算。 使用 Jupyter Notebook,可以与数据进行交互、将代码和 Markdown 文本结合使用,以及进行简单的可视化。
HDInsight 中的 Apache Spark on AKS 由多个组件组成,作为 Pod。
群集控制器
群集控制器负责安装和管理各自的服务。 在 Spark 群集中安装和管理各种控制器。
Apache Spark 服务组件
Zookeeper 服务:三节点 Zookeeper 群集,充当其他服务的分布式协调器或高可用性存储。
Yarn 服务: Hadoop Yarn 群集,Spark 作业会在群集中计划为 Yarn 应用程序。
客户端接口: HDInsight on AKS 中的 Apache Spark 群集提供各种客户端接口。 Livy Server、Jupyter Notebook、Spark History Server 向 AKS 上的 HDInsight 用户提供 Spark 服务。
参考
- Apache、Apache Spark、Spark 和关联的开源项目名称是 Apache Software Foundation (ASF) 的商标。