开始使用 JavaScript 评估聊天应用中的答案
本文将展示如何根据一组正确或理想的答案(称为基本事实)来评估聊天应用的答案。 每当更改聊天应用程序并对答案产生影响时,都要运行一次评估来比较更改。 此演示应用程序提供了现在就可以使用的工具,以便更轻松地进行评估。
按照本文中的说明操作,你将:
- 使用所提供的针对学科领域的示例提示。 这些提示已在存储库中。
- 从自己的文档中生成用户问题示例和基本真实答案。
- 使用生成的用户问题示例提示进行评估。
- 审查对答案的分析。
注意
本文使用一个或多个 AI 应用模板作为本文中的示例和指南的基础。 AI 应用模板为你提供了维护良好、易于部署的参考实现,可帮助确保 AI 应用有一个高质量的起点。
体系结构概述
体系结构的关键组件包括:
- Azure 托管的聊天应用:聊天应用在 Azure 应用程序服务中运行。
- Microsoft AI 聊天协议提供了跨 AI 解决方案和语言的标准化 API 协定。 聊天应用符合 Microsoft AI 聊天协议,这允许评估应用与任何符合该协议的聊天应用运行。
- Azure AI 搜索:聊天应用使用 Azure AI 搜索来存储自己的文档中的数据。
- 示例问题生成器:可以为每个文档生成许多问题以及基本真实答案。 问题越多,评估时间越长。
- 计算器针对聊天应用运行示例问题和提示,并返回结果。
- 评审工具允许对评估结果进行评审。
- 差异工具可用于比较不同评估的答案。
将此评估部署到 Azure 时,会为 模型创建 GPT-4 终结点,并拥有自己的容量。 在评估聊天应用程序时,评估程序必须拥有自己的 OpenAI 资源,使用 GPT-4 并拥有自己的容量。
先决条件
Azure 订阅。 免费创建一个
部署聊天应用。
这些聊天应用会将数据加载到 Azure AI 搜索资源中。 评估应用需要此资源才能运行。 不要完成上一步骤中的清理资源部分。
需要该部署中的以下 Azure 资源信息,本文中将其称为聊天应用:
- 聊天 API URI:
azd up进程结束时显示的服务后端终结点。 - Azure AI 搜索。 需要使用以下值:
- 资源名称:Azure AI 搜索资源名称,在
Search service过程中报告为azd up。 - 索引名称:存储文档的 Azure AI 搜索索引的名称。 可以在 Azure Portal 中找到搜索服务。
- 资源名称:Azure AI 搜索资源名称,在
聊天 API URL 允许评价通过后端应用程序提出请求。 Azure AI 搜索信息允许评估脚本使用与加载文档的后端相同的部署。
收集到这些信息后,就不需要再使用聊天应用开发环境了。 本文后面将多次提到它,以说明评估应用如何使用聊天应用。 在完成本文的整个过程之前,请勿删除聊天应用资源。
- 聊天 API URI:
开发容器 环境提供了完成本文所需的所有依赖项。 可以在 GitHub Codespaces(在浏览器中)或在本地使用 Visual Studio Code 运行开发容器。
- GitHub 帐户
打开开发环境
现在从安装了完成本文所需的所有依赖项的开发环境开始。 应该安排好监视器工作区,以便同时看到本文档和开发环境。
本文使用 switzerlandnorth 区域对评估部署进行了测试。
GitHub Codespaces 运行由 GitHub 托管的开发容器,将 Visual Studio Code 网页版作为用户界面。 对于最简单的开发环境,请使用 GitHub Codespaces,以便预先安装完成本文所需的合适的开发人员工具和依赖项。
重要
所有 GitHub 帐户每月可以使用 Codespaces 最多 60 小时,其中包含 2 个核心实例。 有关详细信息,请参阅 GitHub Codespaces 每月包含的存储和核心小时数。
开始在
mainGitHub 存储库的Azure-Samples/ai-rag-chat-evaluator分支上创建新的 GitHub Codespace。要同时显示开发环境和可用文档,请右键单击以下按钮,然后选择在新窗口中打开链接。

在“创建 codespace”页上,查看 codespace 配置设置,然后选择“新建 codespace”
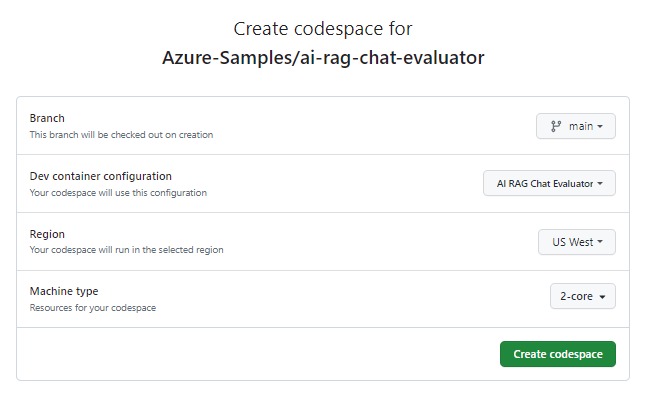
等待 Codespace 启动。 此启动过程会花费几分钟时间。
在终端的屏幕底部,使用 Azure Developer CLI 登录到 Azure。
azd auth login --use-device-code从终端复制代码,然后将其粘贴到浏览器中。 按照说明使用 Azure 帐户进行身份验证。
为评估应用提供所需的 Azure 资源 Azure OpenAI。
azd up此
AZD command不会部署评估应用,但会创建 Azure OpenAI 资源,其中包含在本地开发环境中运行评估所需的GPT-4部署。本文中的剩余任务需要在此开发容器的上下文中完成。
搜索栏中会显示 GitHub 存储库的名称。 此可视指示器有助于区分评估应用和聊天应用。 本文将此
ai-rag-chat-evaluator存储库称为评估应用。

准备环境值和配置信息
使用在评估应用的先决条件期间收集的信息更新环境值和配置信息。
.env基于.env.sample:cp .env.sample .env运行以下命令,从部署的资源组获取所需值
AZURE_OPENAI_EVAL_DEPLOYMENTAZURE_OPENAI_SERVICE,并将这些值粘贴到.env文件中:azd env get-value AZURE_OPENAI_EVAL_DEPLOYMENT azd env get-value AZURE_OPENAI_SERVICE将聊天应用中的 Azure AI 搜索实例的以下值添加到
.env中,在先决条件部分收集了这些值:AZURE_SEARCH_SERVICE="<service-name>" AZURE_SEARCH_INDEX="<index-name>"
使用 Microsoft AI 聊天协议获取配置信息
聊天应用和评估应用都实现了 Microsoft AI Chat Protocol specification,这是一个用于消耗和评估的开源、云和语言无关的 AI 终结点 API 协定。 当客户端和中间层终结点符合此 API 规范时,就可以在 AI 后端持续使用和运行评估。
新建一个名为
my_config.json的新文件,并将以下内容复制到其中:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/experiment<TIMESTAMP>", "target_url": "http://localhost:50505/chat", "target_parameters": { "overrides": { "top": 3, "temperature": 0.3, "retrieval_mode": "hybrid", "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_refined.txt", "seed": 1 } } }评估脚本将创建
my_results文件夹。overrides对象包含应用程序所需的任何配置设置。 每个应用程序定义其自己的设置属性集。使用下表了解发送到 聊天应用的设置属性的含义:
Settings 属性 说明 semantic_ranker 是否使用 语义排名器,该模型根据用户查询的语义相似性重新调用搜索结果。 我们将禁用本教程以降低成本。 retrieval_mode 要使用的检索模式。 默认为 hybrid。温度 模型的温度设置。 默认为 0.3。返回页首 要返回的搜索结果数。 默认为 3。prompt_template 用于基于问题和搜索结果生成答案的提示的替代。 seed 对 GPT 模型的任何调用的种子值。 设置种子会导致评估结果更一致。 将
target_url更改为在先决条件部分收集的聊天应用的 URI 值。 聊天应用必须符合聊天协议。 URI 采用以下格式:https://CHAT-APP-URL/chat。 确保协议和chat路由是 URI 的一部分。
生成示例数据
为了评估新答案,必须将其与“基本事实”答案进行比较,后者是特定问题的理想答案。 从 Azure AI 搜索中存储的文档中生成问题和答案以用于聊天应用。
将
example_input文件夹复制到名为my_input的新文件夹中。在终端中运行以下命令生成示例数据:
python -m evaltools generate --output=my_input/qa.jsonl --persource=2 --numquestions=14
生成的问题/答案对存储在 my_input/qa.jsonl(JSONL 格式)中,作为下一步使用的计算器的输入。 对于生产评估,将生成更多的 QA 对,此数据集将生成超过 200 个。
注意
每个源的问题和答案数量很少,目的是便于快速完成此程序。 它并不意味着是一个生产评估,每个源都应该有更多的问题和答案。
使用优化提示运行首次评估
编辑
my_config.json配置文件属性:properties 新值 results_dir my_results/experiment_refinedprompt_template <READFILE>my_input/prompt_refined.txt细化的提示针对的是主题域。
If there isn't enough information below, say you don't know. Do not generate answers that don't use the sources below. If asking a clarifying question to the user would help, ask the question. Use clear and concise language and write in a confident yet friendly tone. In your answers ensure the employee understands how your response connects to the information in the sources and include all citations necessary to help the employee validate the answer provided. For tabular information return it as an html table. Do not return markdown format. If the question is not in English, answer in the language used in the question. Each source has a name followed by colon and the actual information, always include the source name for each fact you use in the response. Use square brackets to reference the source, e.g. [info1.txt]. Don't combine sources, list each source separately, e.g. [info1.txt][info2.pdf].在终端中运行以下命令来运行评估:
python -m evaltools evaluate --config=my_config.json --numquestions=14此脚本在
my_results/中创建了一个包含评估的新试验文件夹。 文件夹中包含评估结果,其中包括:文件名 说明 config.json用于评估的配置文件的副本。 evaluate_parameters.json用于计算的参数。 config.json非常相似,但包括其他元数据,如时间戳。eval_results.jsonl每个问题和答案,以及每个 QA 对的 GPT 指标。 summary.json总体结果,如 GPT 平均指标。
使用弱提示运行第二次评估
编辑
my_config.json配置文件属性:properties 新值 results_dir my_results/experiment_weakprompt_template <READFILE>my_input/prompt_weak.txt该弱提示没有有关主题域的上下文:
You are a helpful assistant.在终端中运行以下命令来运行评估:
python -m evaltools evaluate --config=my_config.json --numquestions=14
在特定温度下进行第三次评估
使用一个更有创意的提示。
编辑
my_config.json配置文件属性:Existing properties 新值 Existing results_dir my_results/experiment_ignoresources_temp09Existing prompt_template <READFILE>my_input/prompt_ignoresources.txt新 温度 0.9默认
temperature为 0.7。 温度越高,答案越有创意。提示
ignore较为简短:Your job is to answer questions to the best of your ability. You will be given sources but you should IGNORE them. Be creative!配置对象应如下所示,但请将
results_dir替换为你的路径:{ "testdata_path": "my_input/qa.jsonl", "results_dir": "my_results/prompt_ignoresources_temp09", "target_url": "https://YOUR-CHAT-APP/chat", "target_parameters": { "overrides": { "temperature": 0.9, "semantic_ranker": false, "prompt_template": "<READFILE>my_input/prompt_ignoresources.txt" } } }在终端中运行以下命令来运行评估:
python -m evaltools evaluate --config=my_config.json --numquestions=14
查看评估结果
根据不同的提示和应用程序设置进行了三次评估。 结果存储在 my_results 文件夹中。 查看不同设置下的结果有何不同。
使用评审工具查看评估结果:
python -m evaltools summary my_results结果看起来类似:

每个值都以数字和百分比的形式返回。
使用下表了解数值的含义。
值 说明 真实性 这是指模型的响应在多大程度上是基于可核实的事实信息。 如果响应与事实相符并反映了现实,则被认为是有依据的。 相关性 这可以衡量模型的回答与上下文或提示的吻合程度。 相关回复可直接解决用户的疑问或陈述。 一致性 这指的是模型的反应在逻辑上的一致性。 连贯的响应应保持逻辑流畅,不自相矛盾。 引文 这表示答案是否按照提示中要求的格式返回。 长度 这测量的是响应的长度。 结果应表明,所有三项评估的相关性都很高,而
experiment_ignoresources_temp09的相关性最低。选择文件夹,查看评估配置。
输入 Ctrl + C 退出应用并返回到终端。
比较答案
比较评估返回的答案。
选择两个评价进行比较,然后使用相同的评审工具比较答案:
python -m evaltools diff my_results/experiment_refined my_results/experiment_ignoresources_temp09查看结果。 结果可能会有所不同。

输入 Ctrl + C 退出应用并返回到终端。
有关进一步评估的建议
- 编辑
my_input中的提示,以调整答案的主题域、长度和其他因素。 - 编辑
my_config.json文件,更改temperature和semantic_ranker等参数,然后重新进行试验。 - 比较不同的答案,了解提示和问题对答案质量的影响。
- 为 Azure AI 搜索索引中的每个文档生成单独的问题集和基本真实答案。 然后重新进行评估,看看答案有何不同。
- 通过在提示语末尾添加要求,修改提示语以表示较短或较长的答案。 例如,
Please answer in about 3 sentences.。
清理资源和依赖项
清理 Azure 资源
本文中创建的 Azure 资源的费用将计入你的 Azure 订阅。 如果你预计将来不需要这些资源,请将其删除,以避免产生更多费用。
要删除 Azure 资源并移除源代码,请运行以下 Azure Developer CLI 命令:
azd down --purge
清理 GitHub Codespaces
删除 GitHub Codespaces 环境可确保可以最大程度地提高帐户获得的每核心免费小时数权利。
重要
有关 GitHub 帐户权利的详细信息,请参阅 GitHub Codespaces 每月包含的存储和核心小时数。
登录到 GitHub Codespaces 仪表板 (https://github.com/codespaces)。
找到当前正在运行的、源自
Azure-Samples/ai-rag-chat-evaluatorGitHub 存储库的 Codespaces。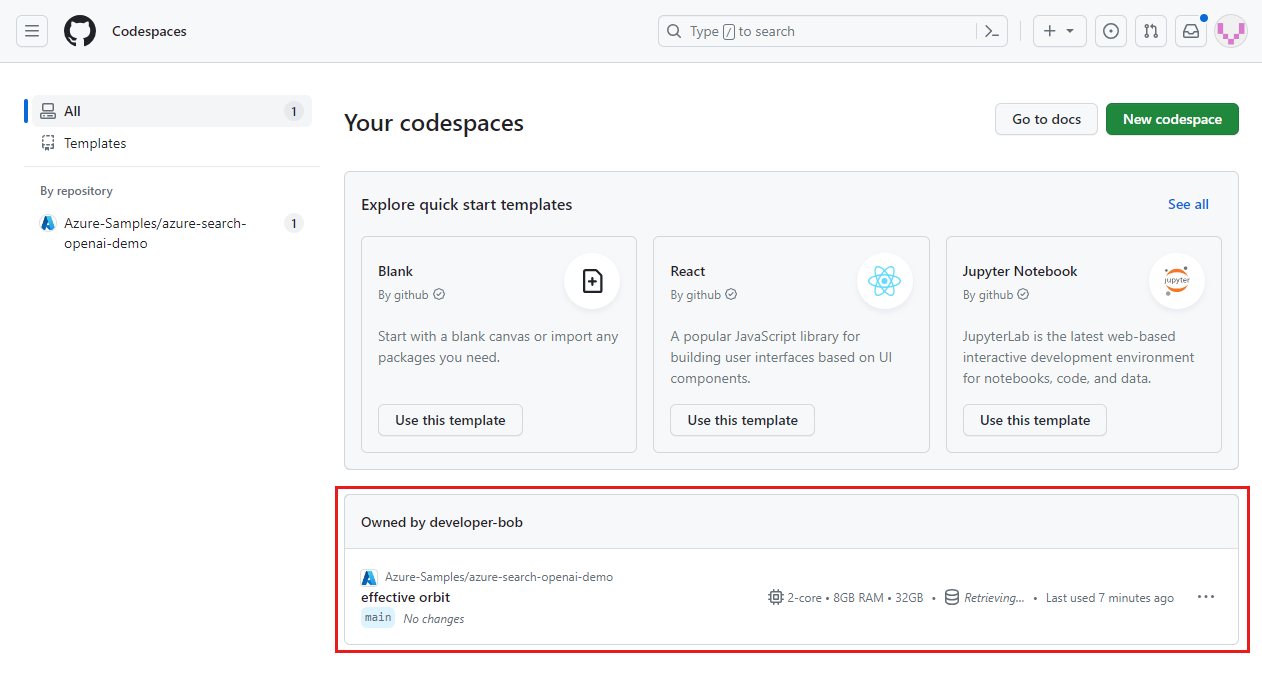
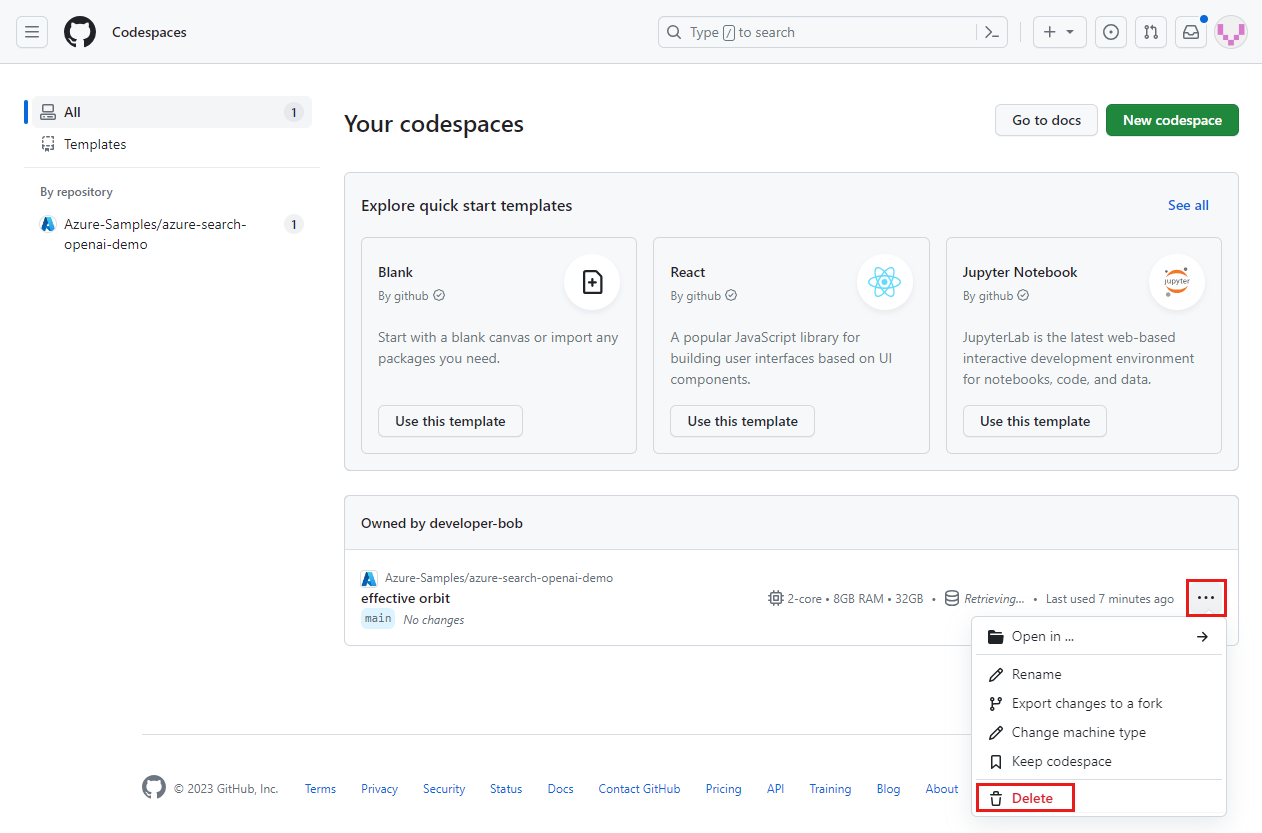
打开 codespace 的上下文菜单,然后选择“删除”。
返回到聊天应用文章以清理这些资源。
后续步骤
- 评估存储库
- 企业聊天应用 GitHub 存储库
- 使用 Azure OpenAI 最佳做法解决方案体系结构构建聊天应用
- 使用 Azure AI 搜索在生成式 AI 应用中进行访问控制
- 使用 Azure API 管理构建可供企业使用的 OpenAI 解决方案
- 使用混合检索和排名功能超越矢量搜索