为什么要进行增量流处理?
如今的数据驱动型企业持续生成数据,这需要持续引入和转换这些数据的工程数据管道。 这些管道应该能够精确处理和传递一次数据,生成延迟小于 200 毫秒的结果,并始终尝试将成本降到最低。
本文介绍工程数据管道的批处理和增量流处理方法、为什么增量流处理是更好的选择,以及开始使用 Databricks 增量流处理产品/服务的后续步骤、Azure Databricks 上的流式处理和什么是增量实时表?。 这些功能可实现快速编写和运行管道,保证交付语义、延迟、成本等。
重复批处理作业的陷阱
设置数据管道时,可以先编写重复的批处理作业来引入数据。 例如,可以每小时运行一个 Spark 作业,从源读取数据并将数据写入到 Delta Lake 之类的接收器中。 这种方法的挑战在于以增量方式处理源,因为每小时运行的 Spark 作业需要从上一个作业结束的地方开始。 可以记录所处理数据的最新时间戳,然后选择时间戳比该时间戳更新的所有行,但这样做存在陷阱:
要运行连续数据管道,可以尝试安排每小时的批处理作业,该作业以增量方式从源读取、进行转换并将结果写入 Delta Lake 之类的接收器。 此方法可能存在陷阱:
- 在时间戳之后查询所有新数据的 Spark 作业将丢失延迟数据。
- 如果处理不当,失败的 Spark 作业可能会导致打破一次性的保证。
- 列出云存储位置的内容来查找新文件的 Spark 作业将变得昂贵。
然后,仍需要重复转换此数据。 你可能会编写重复的批处理作业,然后合并数据或应用其他操作,这会进一步让管道复杂化并降低其效率。
批处理示例
要充分了解管道的批处理引入和转换的陷阱,请考虑以下示例。
丢失的数据
给定一个包含使用情况数据的 Kafka 主题,该主题决定向客户收取多少费用,并且管道正在分批引入数据,则事件序列可能如下所示:
- 第一批在上午 8 点和上午 8:30 有两条记录。
- 最新的时间戳更新为上午 8:30。
- 上午 8:15 又有一条记录。
- 第二批会查询上午 8:30 后的所有内容,因此会错过上午 8:15 的记录。
此外,你不希望过度收费或低估用户,因此必须确保仅引入每条记录一次。
冗余处理
接下来,假设数据包含用户购买行,并且想要合并每小时的销售量,以便了解商店中最受欢迎的时间。 如果同一小时的购买分为不同的批次到达,那么将有多个批次产生同一小时的输出:
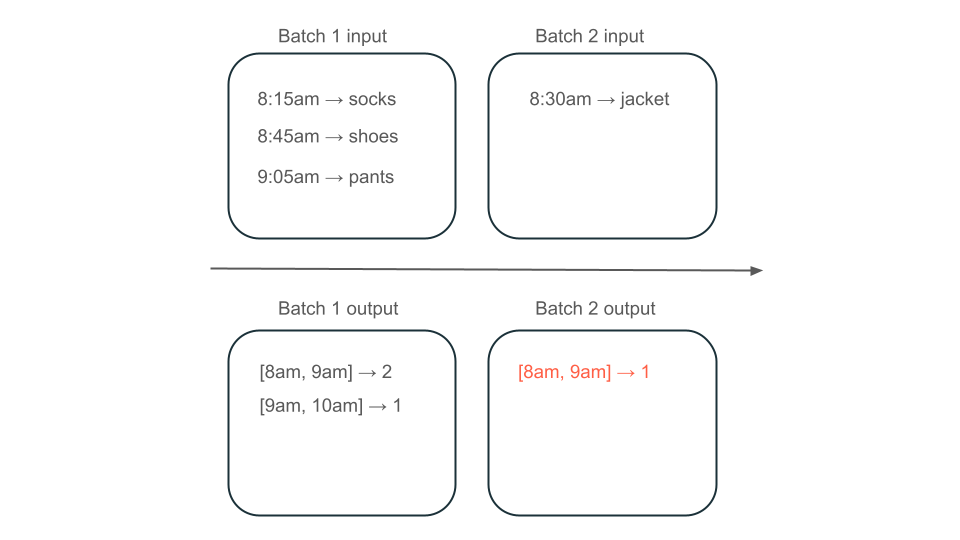
上午 8 点到 9 点的窗口有两个元素(批次 1 的输出)、一个元素(批次 2 的输出)还是三个元素(没有任何批次的输出)? 产生给定时间窗口所需的数据出现在多个转换批次中。 要解决此问题,可以按天对数据进行分区,并在需要计算结果时重新处理整个分区。 然后,可以覆盖接收器中的结果:
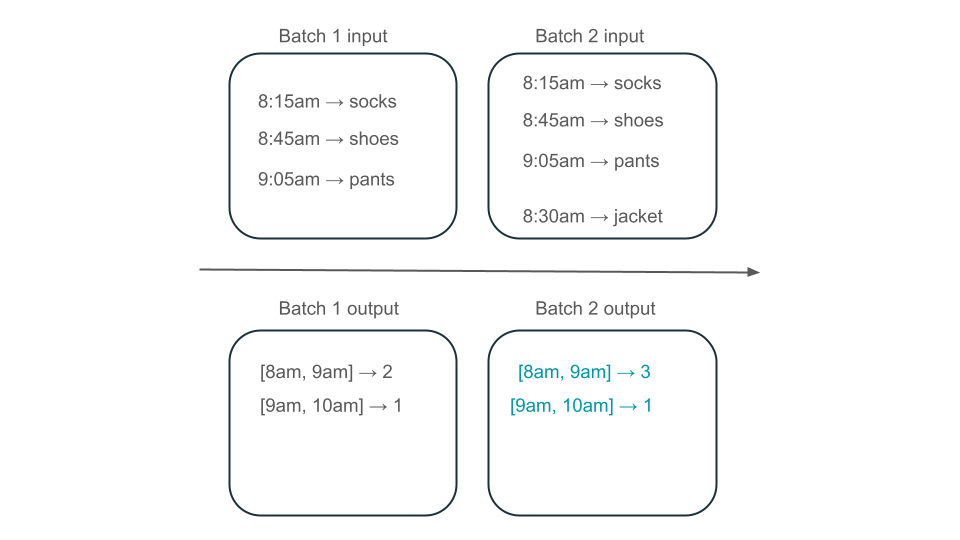
然而,这是以延迟和成本为代价的,因为第二批需要做处理可能已处理数据的不必要工作。
增量流处理不存在陷阱
增量流处理可轻松避免重复批处理作业引入和转换数据的所有陷阱。 Databricks 结构化流式处理和增量实时表管理流式处理实现的复杂性,让你能够专注于业务逻辑。 只需指定要连接到的源、应对数据执行哪些转换以及写入结果的位置。
增量引入
Databricks 中的增量引入由 Apache Spark 结构化流式处理提供支持,可以以增量方式使用数据源并将其写入接收器。 结构化流式处理引擎可以只使用一次数据,并且引擎可以处理无序数据。 引擎可以在笔记本中运行,也可以在增量实时表中使用流式处理表。
Databricks 上的结构化流式处理引擎提供 AutoLoader 等专有的流式处理源,可以以经济高效的方式增量处理云文件。 Databricks 还为其他常用消息总线(如 Apache Kafka、Amazon Kinesis、Apache Pulsar 和 Google Pub/Sub)提供连接器。
增量转换
使用结构化流式处理的 Databricks 中的增量转换可以指定与批处理查询相同的 API 对 DataFrame 的转换,但它会跟踪一段时间内的批处理和聚合值的数据,这样就不必这样做。 它从不需要重新处理数据,因此比重复批处理作业更快、更具成本效益。 结构化流生成可以追加到接收器的数据流,例如 Delta Lake、Kafka 或任何其他受支持的连接器。
Delta Live Tables 中的具体化视图 由 Enzyme 引擎提供支持。 Enzyme 仍然以增量方式处理源,但不生成流,而是创建具体化视图,这是一个预先计算的表,用于存储给出的查询结果。 Enzyme 能够有效地确定新数据如何影响查询结果,并让预计算的表保持最新状态。
具体化视图在合并上创建一个视图,该视图始终能有效地进行自我更新,例如,在上述场景中,你知道上午 8 点到 9 点的窗口有三个元素。
选择结构化流式处理还是增量实时表?
结构化流式处理和增量实时表之间的显著差异在于操作流式处理查询的方式。 在结构化流式处理中,需要手动指定许多配置,并且必须手动将查询整合在一起。 必须显式启动查询,等待查询终止、失败时取消查询以及执行其他操作。 在增量实时表中,以声明方式为管道提供要运行的增量实时表,并让这些表保持运行状态。
Delta Live Tables 还具有具体化视图等功能,可有效地以增量方式预先计算数据的转换。
有关这些功能的详细信息,请参阅 Azure Databricks 上的流式处理以及什么是增量实时表?。
后续步骤
使用增量实时表创建第一个管道。 请参阅教程:运行第一个增量实时表管道。
在 Databricks 上运行第一个结构化流式处理查询。 请参阅运行第一个结构化流式处理工作负载。
使用具体化视图。 请参阅 在 Databricks SQL 中使用具体化视图。