什么是异步进度跟踪?
重要
此功能目前以公共预览版提供。
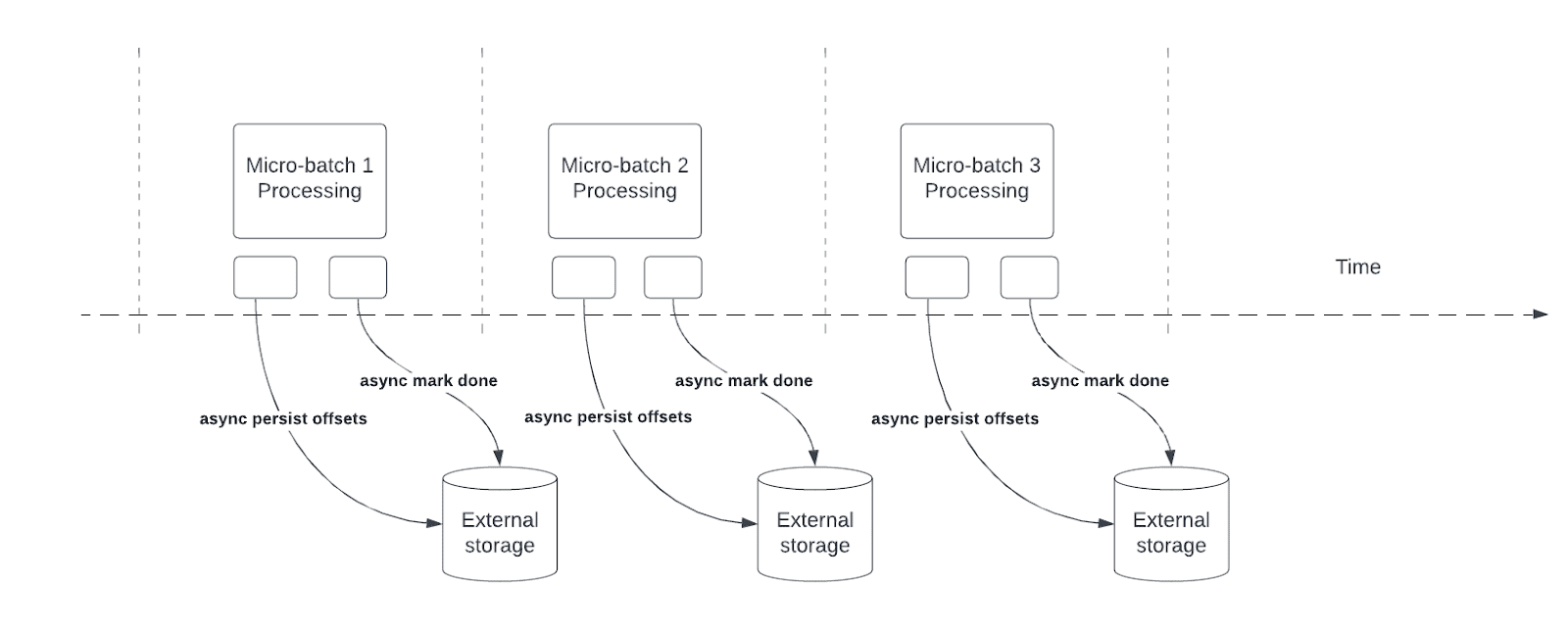
异步进度跟踪使结构化流式处理管道能够以异步方式与微批中的实际数据处理并行创建进度检查点,从而降低与维护 offsetLog 和 commitLog 相关的延迟。
注意
异步进度跟踪不适用于 Trigger.once 或 Trigger.availableNow 触发器。 尝试使用这些触发器启用此功能会导致查询失败。
异步进度跟踪如何减少延迟?
结构化流式处理依赖于持久保存和管理偏移量作为查询处理的进度指示器。 偏移管理操作直接影响处理延迟,因为在完成这些操作之前,不会发生数据处理。 异步地进度跟踪允许结构化流式处理管道记录进度,且不会受到这些偏移管理操作的影响。
何时应配置检查点频率?
用户可以配置进度检查点的创建频率。 检查点频率的默认设置为大多数查询提供良好的吞吐量。 配置频率对于偏移管理操作的发生速率高于可以处理的速率的方案非常有用,这会增加偏移管理操作积压。 为了阻止这种日益增多的积压工作,数据处理被阻止或减慢,实质上是还原处理行为,以消除异步进度跟踪的好处。
注意
故障恢复时间随着检查点间隔时间的增加而增加。 如果发生故障,管道必须重新处理上一个成功检查点之前的所有数据。 用户可以考虑在日常处理期间可以保持较低延迟与在故障情况下可以快速恢复之间进行权衡。
哪些配置与异步进度跟踪相关联?
| 选项 | 价值 | 违约 | 描述 |
|---|---|---|---|
| 异步进度跟踪已启用 (asyncProgressTrackingEnabled) | 真/假 | false | 启用或禁用异步进度跟踪 |
| asyncProgressTrackingCheckpointIntervalMs | 毫秒 | 1000 | 提交偏移量和完成提交的间隔 |
用户如何启用异步进度跟踪?
用户可以使用类似于以下代码的代码来启用此功能:
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
关闭异步进度跟踪
启用异步进度跟踪后,框架不会检查每个批的进度。 若要解决此问题,请在禁用异步进度跟踪之前,使用以下设置处理至少两个微批处理:
.option("asyncProgressTrackingEnabled", "true").option("asyncProgressTrackingCheckpointIntervalMs", 0)
在至少两个微批处理完成处理后停止查询。 现在可以安全地禁用异步进度跟踪并重启查询。
如果在未完成此步骤的情况下禁用了异步进度跟踪,可能会遇到以下错误:
java.lang.IllegalStateException: batch x doesn't exist
在驱动程序日志中,可能会看到以下错误:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
按照本部分中的说明禁用异步进度跟踪,可以解决这些错误并修复流式处理工作负荷。
异步进度跟踪的限制
此功能具有以下限制:
- 仅当将 Kafka 用作接收器时,无状态管道才支持异步进度跟踪。
- 精确一次的端到端处理无法通过异步进度跟踪来保证,因为在发生故障时,批处理的偏移范围可能会更改。 某些接收器(例如 Kafka)从不提供“恰好一次”保证。