sparklyr
Azure Databricks 支持笔记本、作业和 RStudio 桌面中的 sparklyr。 本文介绍如何使用 sparklyr,并提供可运行的示例脚本。 有关详细信息,请参阅 Apache Spark 的 R 接口。
要求
Azure Databricks 随附每个 Databricks Runtime 版本分发 sparklyr 的最新稳定版本。 可以通过导入已安装的 sparklyr 版本,在 Azure Databricks R 笔记本或托管在 Azure Databricks 上的 RStudio Server 内使用 sparklyr。
在 RStudio Desktop 中,Databricks Connect 允许将 Sparklyr 从本地计算机连接到 Azure Databricks 群集并运行 Apache Spark 代码。 请参阅将 sparklyr 和 RStudio Desktop 与 Databricks Connect 配合使用。
将 sparklyr 连接到 Azure Databricks 群集
若要建立 sparklyr 连接,可以使用 "databricks" 作为 spark_connect() 中的连接方法。
不需要 spark_connect() 的其他参数,也不需要调用 spark_install(),因为 Spark 已安装在 Azure Databricks 群集上。
# Calling spark_connect() requires the sparklyr package to be loaded first.
library(sparklyr)
# Create a sparklyr connection.
sc <- spark_connect(method = "databricks")
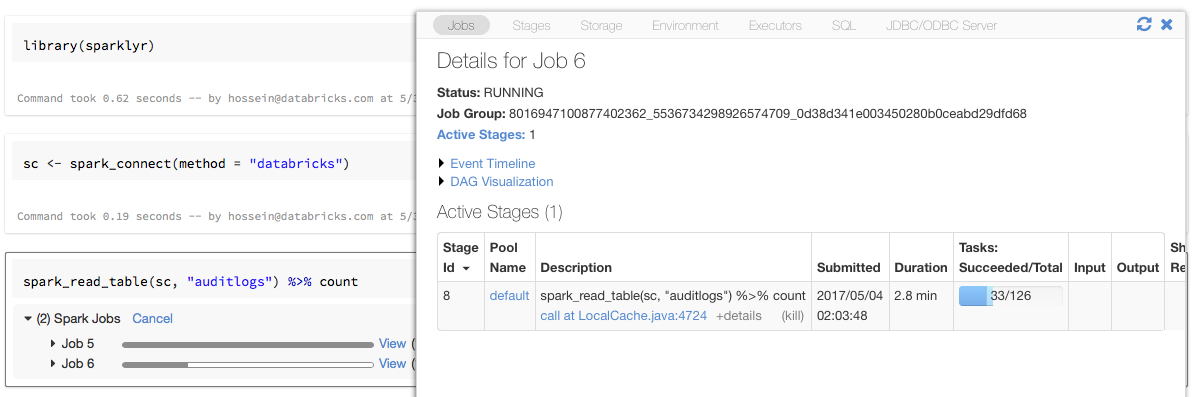
具有 sparklyr 的进度条和 Spark UI
如上例所示,如果将 sparklyr 连接对象分配给名为 sc 的变量,则在每个触发 Spark 作业的命令后,你将在笔记本中看到 Spark 进度条。
此外,还可以单击进度条旁边的链接,查看与给定 Spark 作业关联的 Spark UI。
使用 sparklyr
安装 sparklyr 并建立连接后,所有其他 sparklyr API 将正常工作。 有关一些示例,请参阅示例笔记本。
sparklyr 通常与其他 tidyverse 包(例如 dplyr)一起使用。 为方便起见,其中大多数包已预安装在 Databricks 上。 只需导入它们即可开始使用 API。
结合使用 sparklyr 和 SparkR
SparkR 和 sparklyr 可在单个笔记本或作业中一起使用。 可以将 SparkR 与 sparklyr 一起导入,并使用其功能。 在 Azure Databricks 笔记本中,SparkR 连接是预先配置的。
SparkR 中的某些函数屏蔽了 dplyr 中的部分函数:
> library(SparkR)
The following objects are masked from ‘package:dplyr’:
arrange, between, coalesce, collect, contains, count, cume_dist,
dense_rank, desc, distinct, explain, filter, first, group_by,
intersect, lag, last, lead, mutate, n, n_distinct, ntile,
percent_rank, rename, row_number, sample_frac, select, sql,
summarize, union
如果在导入 dplyr 后导入 SparkR,则可以通过使用完全限定的名称(例如 dplyr::arrange())引用 dplyr 中的函数。
同样,如果在 SparkR 后导入 dplyr,则 SparkR 中的函数将被 dplyr 屏蔽。
或者,可以在不需要时选择性地拆离这两个包中的一个。
detach("package:dplyr")
另请参阅比较 SparkR 和 sparklyr。
在 spark-submit 作业中使用 sparklyr
可以在 Azure Databricks 上运行使用 sparklyr 的脚本作为 spark-submit 作业,并进行少量代码修改。 上述部分说明不适用于在 Azure Databricks 上的 spark-submit 作业中使用 sparklyr。 特别是,必须向 spark_connect 提供 Spark 主 URL。 例如:
library(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
...
不支持的功能
Azure Databricks 不支持需要本地浏览器的 sparklyr 方法,如 spark_web() 和 spark_log()。 不过,由于 Spark UI 是内置在 Azure Databricks 上的,因此你可以轻松地查看 Spark 作业和日志。
参阅计算驱动程序和工作器日志。
示例笔记本:Sparklyr 演示
Sparklyr 笔记本
有关其他示例,请参阅 使用 R 中的 DataFrames 和表。