Azure Databricks 群集的区域性灾难恢复
本文介绍可用于 Azure Databricks 群集的灾难恢复体系结构,以及实现该设计的步骤。
Azure Databricks 体系结构
当通过 Azure 门户创建 Azure Databricks 工作区时,会在所选 Azure 区域(例如美国西部)将某个托管应用程序部署为订阅中的 Azure 资源。 此设备部署在 Azure 虚拟网络中,该网络具有网络安全组和订阅中的 Azure 存储帐户。 该虚拟网络为 Databricks 工作区提供外围级安全性,并受网络安全组的保护。 在工作区中,可以通过提供辅助角色和驱动程序 VM 类型与 Databricks 运行时版本来创建 Databricks 群集。 持久化数据在存储帐户中可用。 创建群集后,可以通过笔记本、REST API 或 ODBC/JDBC 终结点运行作业:只需将作业附加到特定的群集即可。
Databricks 控制平面管理并监视 Databricks 工作区环境。 任何管理操作(例如创建群集)将从控制平面发起。 所有元数据(例如计划作业)都存储在 Azure 数据库中,数据库备份会自动异地复制到实现此功能的配对区域中。
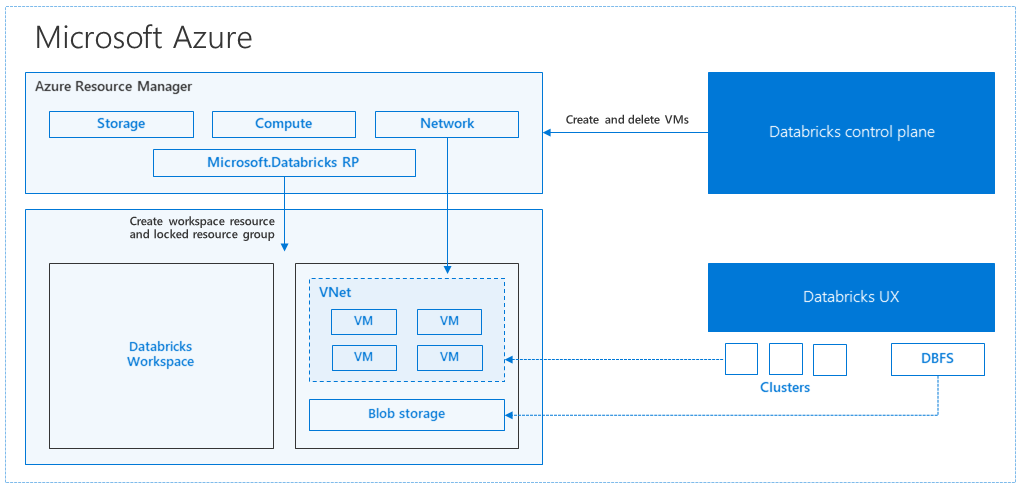
此体系结构的优势之一是,用户可将 Azure Databricks 连接到其帐户中的任何存储资源。 另一个重要优点在于,计算 (Azure Databricks) 和存储可以互相独立地缩放。
如何创建区域性灾难恢复拓扑
在上面的体系结构说明中,包含 Azure Databricks 的大数据管道使用了许多组件:Azure 存储、Azure 数据库和其他数据源。 Azure Databricks 是大数据管道的计算层。 它在本质上是临时性的,这意味着尽管数据仍在 Azure 存储中提供,但可以终止计算(Azure Databricks 群集),以避免在无需计算时支付计算费用。 计算 (Azure Databricks) 和存储源必须位于同一区域,避免作业遇到较高的延迟。
若要创建自己的区域性灾难恢复拓扑,需满足以下要求:
在不同的 Azure 区域中预配多个 Azure Databricks 工作区。 例如,在美国东部创建主要 Azure Databricks 工作区。 在另一个区域(例如“美国西部”)中创建辅助灾难恢复 Azure Databricks 工作区。 有关配对的 Azure 区域的列表,请参阅跨区域复制。 有关 Azure Databricks 区域的详细信息,请参阅支持的区域。
使用异地冗余存储。 默认情况下,与 Azure Databricks 关联的数据存储在 Azure 存储中,Databricks 作业的结果存储在 Azure Blob 存储中,这样,在群集终止后,处理的数据可持久提供,并保持高可用性。 群集存储和作业存储位于同一可用性区域中。 为了在出现区域性的服务中断时提供保护,默认情况下 Azure Databricks 工作区使用异地冗余存储。 使用异地冗余存储时,数据将复制到 Azure 配对区域。 Databricks 建议保留异地冗余存储作为默认值,但是,如果需要改用本地冗余存储,则可以在工作区的
storageAccountSkuName中将Standard_LRS设置为 。创建次要区域后,必须迁移用户、用户文件夹、笔记本、群集配置、作业配置、库、存储、初始化脚本,并重新配置访问控制。 以下部分介绍了其他详细信息。
区域灾难
若要为区域灾难做好准备,需要在次要区域中显式维护另一组 Azure Databricks 工作区。 请参阅灾难恢复。
建议的灾难恢复工具主要是 Terraform(用于基础结构复制)和 Delta Deep Clone(用于数据复制)。
详细迁移步骤
安装 Databricks CLI
本文中的示例使用 Databricks 命令行接口 (CLI),它是一个易于使用的包装器,基于 Azure Databricks REST API。
在执行任何迁移步骤之前,请在本地计算机或虚拟机上安装 Databricks CLI。 有关详细信息,请参阅安装 Databricks CLI。
注意
本文提供的 Python 脚本适用于 Python 2.7 及更高版本。
配置两个配置文件。
按照 _ 中的步骤,配置两个配置文件:一个用于主要工作区,另一个用于辅助工作区。
databricks configure --profile primary databricks configure --profile secondary在每个后续步骤中,本文中的代码块使用相应的工作区命令在配置文件之间切换。 请确保创建的配置文件的名称可以代入每个代码块。
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"如果需要,可以手动在命令行中切换:
databricks workspace list --profile primary databricks workspace list --profile secondary迁移 Microsoft Entra ID(以前称为 Azure Active Directory)用户
手动将相同的 Microsoft Entra ID(旧称 Azure Active Directory)用户添加到主要工作区中的辅助工作区。
迁移用户文件夹和笔记本
使用以下 python 代码迁移包含嵌套文件夹结构和每个用户的笔记本的沙盒用户环境。
注意
此步骤不会复制库,因为基础 API 不支持库。
将以下 python 脚本复制并保存到文件中,并在命令行中运行它。 例如,
python scriptname.py。import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "list", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")迁移群集配置
迁移笔记本后,可以选择性地将群集配置迁移到新工作区。 它几乎是使用 Databricks CLI 的完全自动化步骤,除非你想要进行选择性群集配置迁移。
注意
没有创建群集配置终结点,并且此脚本尝试立即创建每个群集。 如果订阅中没有足够的核心,群集创建操作可能会失败。 只要成功转移配置,即可忽略这种失败。
下面提供的脚本列显从旧群集 ID 到新群集 ID 的映射,稍后可对作业迁移(配置为使用现有群集的作业)使用该映射。
将以下 python 脚本复制并保存到文件中,并在命令行中运行它。 例如,
python scriptname.py。import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")).splitlines() print("Printing Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append(cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")迁移作业配置
如果在上一步骤中迁移了群集配置,则可以选择将作业配置迁移到新工作区。 这是使用 Databricks CLI 的完全自动化步骤,除非你想要执行选择性作业配置迁移,而不是对所有作业执行该操作。
注意
计划作业的配置还包含“计划”信息,因此,在迁移后,该作业默认会根据配置的时间开始工作。 因此,以下代码块在迁移过程中会删除所有计划信息(目的是避免针对新旧工作区重复运行)。 在准备好交接后,请配置此类作业的计划。
作业配置需要新群集或现有群集的设置。 如果使用现有群集,则以下脚本/代码会尝试将旧群集 ID 替换为新群集 ID。
复制以下 python 脚本并将其保存到某个文件。 将
old_cluster_id和new_cluster_id的值替换为在上一步骤中执行的群集迁移的输出。 例如python scriptname.py,在命令行中运行它。import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate " + str(job)) job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id " + str(job_req_settings_json['existing_cluster_id'])) continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")迁移库
目前无法直接将库从一个工作区迁移到另一个工作区。 需要手动将这些库重新安装到新工作区中。 可以使用 Databricks CLI 自动执行此操作以将自定义库上传到工作区。
迁移 Azure Blob 存储和 Azure Data Lake Storage 装入点
使用基于笔记本的解决方案手动重新装载所有 Azure Blob 存储和 Azure Data Lake Storage(第 2 代)装入点。 存储资源应已装载到主要工作区,必须在辅助工作区中重复该操作。 无法使用外部 API 进行装载。
迁移群集初始化脚本
可以使用 Databricks CLI 将任何群集初始化脚本从旧工作区迁移到新工作区。 首先,将所需的脚本复制到本地桌面或虚拟机。 接下来,将这些脚本复制到新工作区中的相同路径。
注意
如果有初始化脚本存储在 DBFS 中,请先将其迁移到支持的位置。 请参阅 _。
// Primary to local databricks fs cp dbfs:/Volumes/my_catalog/my_schema/my_volume/ ./old-ws-init-scripts --profile primary // Local to Secondary workspace databricks fs cp old-ws-init-scripts dbfs:/Volumes/my_catalog/my_schema/my_volume/ --profile secondary手动重新配置和重新应用访问控制。
如果现有的主要工作区配置为使用高级层或企业层 (SKU),则有可能你同时在使用访问控制。
如果确实使用了访问控制,请手动将访问控制重新应用到资源(笔记本、群集、作业、表)。
Azure 生态系统的灾难恢复
如果你在使用其他 Azure 服务,请确保也为这些服务实施灾难恢复最佳做法。 例如,如果你选择使用外部 Hive 元存储实例,应考虑 Azure SQL 数据库、Azure HDInsight 和/或 Azure Database for MySQL 的灾难恢复。 有关灾难恢复的常规信息,请参阅 Azure 应用程序的灾难恢复。
后续步骤
有关详细信息,请参阅 Azure Databricks 文档。