使用 AutoML 预测(无服务器)
重要
此功能目前以公共预览版提供。
本文介绍如何使用马赛克 AI 模型训练 UI 运行无服务器预测试验。
马赛克 AI 模型训练 - 预测通过自动选择最佳算法和超参数来简化时序数据的预测,同时在完全托管的计算资源上运行。
若要了解无服务器预测与经典计算预测之间的差异,请参阅 无服务器预测与经典计算预测。
要求
使用时序列训练数据,并保存为 Unity Catalog 表。
如果工作区启用了安全出口网关(SEG),则必须将
pypi.org添加到 允许的域 列表中。 请参阅管理无服务器流出量控制的网络策略。
使用 UI 创建预测试验
转到 Azure Databricks 登陆页,然后单击边栏中的 试验。
在“预测”磁贴中,选择“开始训练”。
从可访问的 Unity Catalog 表格列表中选择 训练数据。
- 时间列:选择包含时序时间段的列。 列的类型须为
timestamp或date。 - 预测频率:选择表示输入数据频率的时间单位。 例如,分钟、小时、天、月。 这决定了你的时间序列的粒度。
- 预测地平线:指定要预测未来所选频率的单位数。 这与预测频率一起定义时间单位和要预测的时间单位数。
注意
若要使用 自动 ARIMA 算法,时序必须有一个常规频率,其中任意两个点之间的间隔必须在整个时序中相同。 AutoML 通过使用以前的值填充这些值来处理缺失的时间步骤。
- 时间列:选择包含时序时间段的列。 列的类型须为
选择要让模型预测的预测目标列。
(可选)指定 Unity 目录表 预测数据路径 存储输出预测。
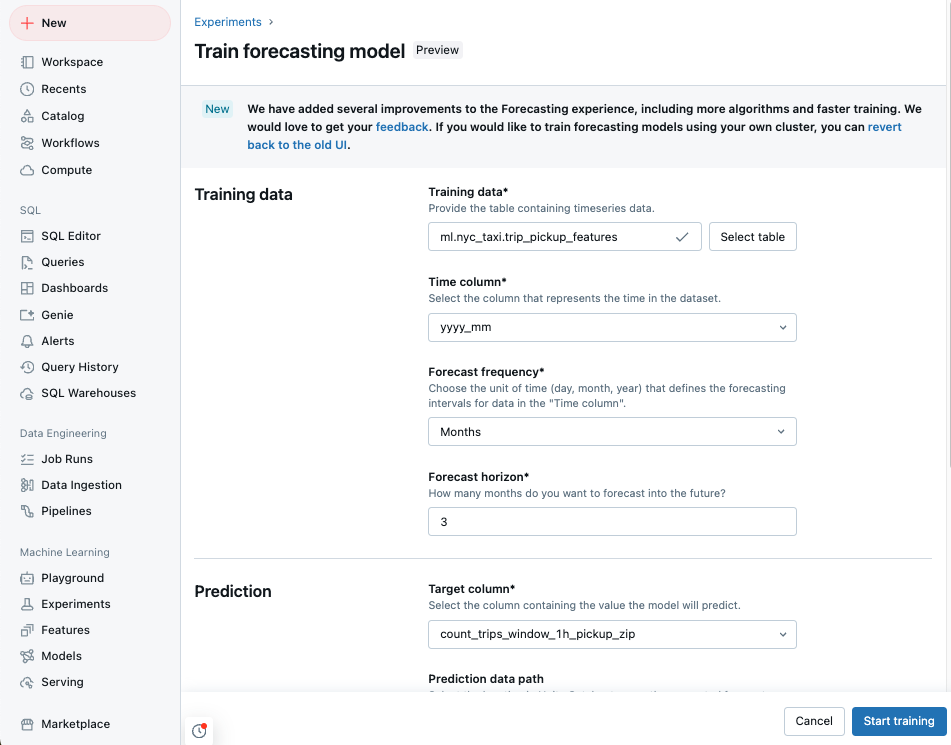
选择模型注册 Unity 目录位置和名称。
(可选)设置 高级选项:
- 试验名称:提供 MLflow 试验名称。
- 时序标识符列 - 对于多系列预测,请选择标识各个时序的列。 Databricks 按这些列将数据分组为不同的时序,并单独训练每个序列的模型。
- 主要指标:选择用于评估和选择最佳模型的主要指标。
- 训练框架:选择要浏览的 AutoML 框架。
- 拆分列:选择包含自定义数据拆分的列。 值必须为“train”、“validate”、“test”
- 权重列:指定要用于加权时序的列。 给定时序的所有样本必须具有相同的权重。 权重必须位于 [0, 10000] 范围内。
- 假日区域:选择要用作模型训练中的协变量的假日区域。
- 超时:设置 AutoML 试验的最长持续时间。
运行试验并监视结果
若要启动 AutoML 试验,请单击 开始训练。 在试验训练页中,可以执行以下操作:
- 随时停止试验。
- 监视运行。
- 导航到任一运行的运行页。
查看结果或使用最佳模型
训练完成后,预测结果将存储在指定的 Delta 表中,最佳模型注册到 Unity 目录。
在“试验”页中,从以下后续步骤中选择:
- 选择 查看预测 以查看预测结果表。
- 选择 Batch 推理笔记本 打开自动生成的笔记本,以便使用最佳模型进行批量推理。
- 选择 创建服务终结点,将最佳模型部署到模型服务终结点。
无服务器预测与经典计算预测
下表总结了无服务器预测与使用经典计算 的
| 特征 | 无服务器预测 | 经典计算预测 |
|---|---|---|
| 计算基础结构 | Azure Databricks 管理计算配置,并自动优化成本和性能。 | 用户配置的计算 |
| 治理 | 注册到 Unity 目录的模型和项目 | 用户配置的工作区文件存储 |
| 算法选择 | 统计模型 加上深度学习神经网络算法 DeepAR | 统计模型 |
| 特征存储集成 | 不支持 | 支持 |
| 自动生成的笔记本 | 批处理推理笔记本 | 所有试用版的源代码 |
| 一键式模型服务部署 | 支持 | 不支持 |
| 自定义训练/验证/测试拆分 | 支持 | 不支持 |
| 单个时间序列的自定义权重 | 支持 | 不支持 |